@First10EM OK, Justin, thanks for your patience. I needed an extra day to put this together, because I wanted to have some simulations & visual representations to help convey a few points.
@First10EM I also want to preface my comments by saying that a) it’s always good to see people interested in critical appraisal and b) as a philosophical matter, it’s a good thing for people to demand a high bar of evidence before adopting therapies into their practice.
@First10EM Therefore: I am absolutely fine with inherent skepticism and/or a desire to see very strong evidence of benefit before you think a therapy should be routinely used, and I am not going to make statements about whether the WAKE UP trial actually merits changing your practice.
@First10EM However, I will try to clarify some of the statistical points in your post which are not quite correct. I hope that after reading these comments, you consider updating your post, because you clearly have a large following and your knowledge dissemination...
@First10EM …has great potential (when accurate) but also can be harmful when misunderstandings are spread through the clinical community trying to interpret this evidence (making your readers more skeptical of trial results for misunderstood or outright wrong reasons).
@First10EM Issue 1: the two paragraphs about “law of large numbers” and “regression to the mean” start off with good intentions, but your application of these principles in the last sentence of the second paragraph is not correct. 


@First10EM It is true that smaller trials are more likely to have “extreme results” or “deviate from truth” – but this can be true in *both* directions (e.g. early looks with small N are just as likely to UNDER-estimate treatment effect as they are to OVER-estimate treatment effect)
@First10EM The way your passage is written starts off ok: as you add more patients the results move towards the “true number” – but then you conclude by insinuating that “regression of the mean could have made this a negative trial” (which assumes that the “true number” is a *null* effect).
@First10EM But that’s a misguided application of the law of large #'s and RTOM, because the estimate can be bigger *or* smaller than the "true number" at any point, so “regression to the mean” does not move the effect towards the *null* in the long run – it moves closer to the “true number”
@First10EM Since the “true number” can be bigger or smaller than the point estimate at any given time (and there is no way of actually knowing which), we do not know that RTOM would make this a negative trial with more patients – that would only be true if treatment effect is actually null
@First10EM I’ll walk through a simulation that might be useful for illustrating this.
@First10EM I have simulated data for a hypothetical trial with a known “true” effect of mortality=40% for Control & mortality=30% for Intervention. Therefore, the “true number” for the odds ratio in an infinite population is about 0.64.
@First10EM I have simulated data for 1000 total patients (500 per treatment group). Here is a plot of the estimated Odds Ratio (y-axis) computed after every 10 patients randomized (x-axis); this is literally the first simulated trial that I ran, so there’s no cherry-picking here:
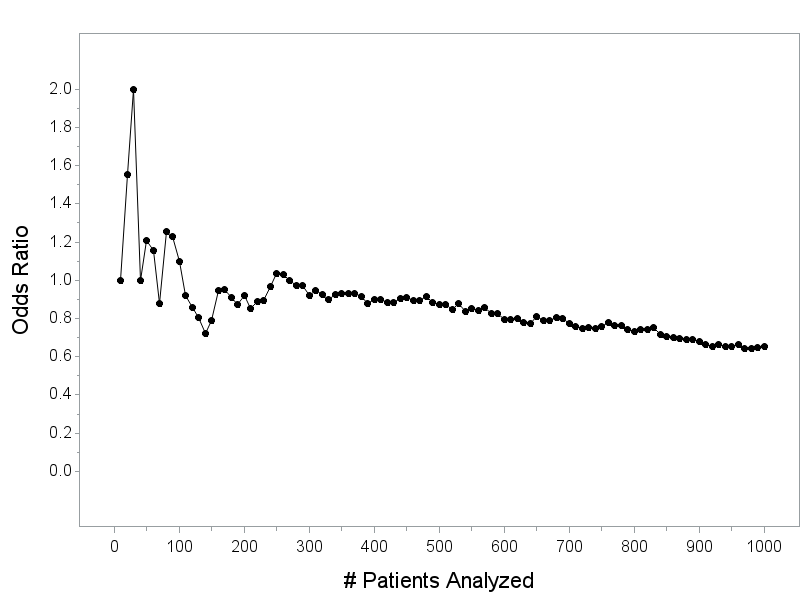
@First10EM Note that the final estimate of the OR after 1000 patients in this trial is 0.653, which happens to be almost identical to the “True” Odds Ratio in a hypothetical treatment with 40% mortality in control that’s improved to 30% mortality with treatment.
@First10EM The point that I hope to convey with this example:
@First10EM You’ve implied that the “law of large numbers” makes it likely that “regression of the mean” can turn borderline-significant results into a negative trial – but..
@First10EM ...you’re adding an unspoken assumption that the “true number” for the treatment effect is actually the null (e.g. that continuing the trial would make the treatment effect go back towards OR=1)
@First10EM However, the “regression to the mean” doesn’t mean that the effect will move towards the null as N increases – it means that it will move towards the “true number” – and you don’t know what that true number is; it could also be a *bigger* treatment effect than what’s observed.
@First10EM The example above illustrates this nicely. As more patients were followed, the “law of large numbers” and “regression to the mean” did pull the effect towards the “true number” – it just happened that the “true number” is a more impressive effect than the earlier looks!
@First10EM The estimated OR at 500 patients was 0.87; the estimated OR at 600 patients was 0.79; the estimated OR at 700 patients was 0.77; at 800 patients, 0.73; at 900 patients, 0.68; and at 1000 patients, 0.65 (again, the “real” OR for the treatments in this simulation is about 0.64)
@First10EM Conclusion for Issue 1: you’ve suggested that “regression to the mean” could have made this a negative trial, but that’s not quite a correct interpretation of regression to the mean or the law of large numbers.
@First10EM This only happens under an additional assumption that “the mean” or “the true number” is actually “the null” – you’re omitting or at least downplaying the possibility that the treatment effect would actually get *bigger* if the trial continued and randomized more patients.
@First10EM I think you’re also combining this with a point that you make a bit later about trials that are stopped early tending to overestimate effect sizes; we’ll get into that a bit later.
@First10EM Issue 2: moving into the discussion about a mortality difference, the argument suddenly abandons the concern about regression to the mean [null] and assumes that “it is very likely that this difference (if maintained) would have been statistically significant”

@First10EM Wait, what happened to the Justin that was worried about the law of large numbers and regression to the mean making results less significant over time? He was here just a paragraph ago!
@First10EM For the primary endpoint, you’re worried that “regression of the mean could have made this a negative trial” but you’re content to assume the mortality effect would remain the same had the trial continued and it would have “become significant” with more patients.
@First10EM It is a valid concern that trials stopped early will have less power than originally designed for (in general) and that this will especially influence the ability to detect differences in secondary outcomes that are rarer events, so there’s a legitimate point here, but…
@First10EM …it’s logically inconsistent to start by assuming that regression to the mean (the null!) would make this “positive result” on the primary outcome less positive, but assuming that the mortality result would remain constant.
@First10EM (there is a separate and worthwhile conversation about whether you find the "primary outcome" in this trial sufficiently compelling to overwhelm a concern about mortality - that's a separate value judgement on the WAKE UP trial, and one you're free to make)
@First10EM Issue 3: this paragraph about early stopping, which has a mixture of correct information and some misleading information.

@First10EM It is correct that trials are not stopped “randomly” – they are most commonly stopped for one of the following broadly defined categories: efficacy, futility, or harm.
@First10EM “We stop positive trials early, when the results look unbelievably good, and prevent the likely regression to the mean” – this is a partial truth.
@First10EM There’s an underlying correct point: effect sizes from trials that are stopped early for efficacy are (in general) an overestimate of the true effect size, and that is due partially to RTM. I’ll try to clarify that with another simulation.
@First10EM Let's use: 40% mortality in Control; 30% mortality in Intervention; trial designed to randomize 1000 patients; we’ll include an interim look at 500 patients using a simple O’Brien-Fleming rule (alpha=0.0054 to stop for efficacy at interim; alpha=0.0492 at final analysis)
@First10EM I simulated this trial 1000 times. 370 of the trials would have been stopped early for efficacy (alpha<0.0054 at an interim look with 500 patients).
@First10EM The estimated odds ratio in the simulations that stopped early for efficacy (p<0.0054 at 500-patient interim) range from 0.32 to 0.60 with a median of 0.53
@First10EM Recall that the “true” odds ratio for this scenario is about 0.64; the advantage of doing this by simulation is that we “know” what the true answer is, something we cannot actually do in real-life trials.
@First10EM Yes, this shows that trials which have stopped early overestimate of the “true” effect size. It’s sort of a “selection bias” issue that IS actually related in a roundabout way to your earlier concern about regression to the mean (really the “mean” this time, not the null)
@First10EM Over more and more patients, the estimates would eventually converge on the true value of 0.64, but only simulations (or trials) where the early results are extreme in favor of the therapy are the ones that actually stop.
@First10EM Two identical runs of the same trial that both (would) end up with OR=0.65, p=0.001 after 1000 patients can be in a very different place after 500 patients
@First10EM Glancing at my sims quick, I see two examples that ended up with OR=0.65, p=0.001 at the “final” analysis with very different interim results: one has OR=0.57, p=0.003 (and would have stopped early) while the other has OR=0.72, p=0.098 (and would have continued to 1000 patients)
@First10EM These both arose from the exact same data-generating mechanism; it’s just a reflection of natural variability from one trial to the next.
@First10EM Note that the degree to which effect size estimates are overestimated in early-stopping situations depends on the operating characteristics of any given trial’s design; in some cases this may be more severe, in others less severe depending on timing of interims and stopping rules
@First10EM With that said, it’s fallacious to assume that trials stopped early for efficacy are somehow more likely to have therapies that actually *don’t work* because of this bias
@First10EM We know that the effect size estimates from trials that are stopped early for efficacy have a tendency to be biased, but they’re only stopped early when the interim is so overwhelming that it’s extremely improbable the results would fully reverse if the trial ran to completion.
@First10EM (It is worth noting that stopping thresholds for efficacy should generally be quite high – there are some teaching examples of trials that would have stopped if you’d just used p<0.05 at an interim that ended up showing no benefit or even harm)
@First10EM So what we learn from trials that stop early for efficacy ends up “the therapy might be a little less effective than the estimate, but the evidence is so powerful it would be extremely improbable to see these results if it actually doesn’t work.”
@First10EM Your solution of looking at the limit of the CI nearest the null, while imperfect, is probably a reasonable enough thing to do since it’s hard to precisely quantify the degree of bias without going hard into the weeds of the trial design and interim strategy.
@First10EM “On the other hand, we stop negative trials early for “futility”, not allowing enough time for the differences in adverse events to become statistically significant.” – again, this is a partial truth seemingly insinuating bad-faith on the part of trial investigators.
@First10EM Trials that are stopped early for futility are stopped because there is little/no chance that the trial will conclude that the therapy works, so it is unethical or unwise to continue entering patients into the trial when the information gain from doing so is minimal.
@First10EM They’re not stopped to *hide* some evidence of adverse events; they’re stopped because the primary objective of the trial will not gain from enrolling additional patients.
@First10EM Also worth noting, there is a subtle difference between trials that are stopped for “futility” (experimental therapy has low residual probability of demonstrating benefit) versus stoppage for “harm” where the experimental therapy is actually showing harm.
@First10EM Until this point I’ve been trying to explain the general misconceptions about early-stopping. Now let’s talk about the specific setting of WAKE-UP, which is a bit of an odd duck in that it was not actually stopped early because of a planned interim analysis.
@First10EM If it had been stopped early because of a planned interim analysis, like the setting described above, it’s valid to point out that while it is likely that the therapy is effective, it is also likely that the effect size reported in the trial is an overestimate of the true benefit
@First10EM But you go ahead and apply this ( “stopping trials early introduces significant bias”) to a setting where it is not clear that this actually applies. Stopping trials early *for efficacy* introduces a bias. WAKE UP was not stopped based on an interim for efficacy.
@First10EM “The more opportunities you have to stop your trial early, the worse the bias becomes.” – this not, strictly speaking, a true statement. It depends on how the interim analyses are performed.
@First10EM It is true that repeated interim looks increase the probability of concluding efficacy when there is no treatment effect, if a statistical procedure is not employed to control for the number of interim analyses performed, but...
@First10EM ...this is where we use that “advanced math” you mentioned reading about before.
@First10EM Any well-designed trial with planned interim looks uses a proper alpha-spending function to avoid inflated Type I error from the interim analyses.
@First10EM “(One of the worst forms of p-hacking is checking your statistics after each patient enrolled, and stopping the trial when you see a p value less than 0.05).” – this is true, but disingenuous to bring up in context of RCT because...
@First10EM ... no self-respecting trialist, ethics board, or DSMB member would permit this chicanery. It also overestimates how easy it would be to actually do this and conceal it.
@First10EM The most common scenario where that “look after every data point” nonsense occurs, to be honest, is the lab sciences, where people will start with 6 mice, then check the data, then do a few more until they see the p-value they like.
@First10EM It’s very hard to get away with that in RCT’s (especially regulatory RCT’s!) where you have to pre-register the analysis plan including any planned interim analyses and efficacy-stopping thresholds.
@First10EM So now we come to the bizarre WAKE-UP scenario, where the trial was not stopped due to a planned interim analysis but due to anticipated loss of funding. And now we go off into a bit of conspiracy-theorist-land.
@First10EM Perhaps I missed something in the public discussion of this trial, but you are heavily insinuating that the trial sponsor/authors were looking at the data repeatedly and simply decided to stop when they saw a positive result. Is there any evidence at all that this occurred?

@First10EM If so, that certainly does change the conversation, but I am assuming if such evidence existed, you would have mentioned that as well.
@First10EM I've been fortunate that I've never worked on a trial that was in progress when funding became uncertain, so I can't speak directly to how such decisions are made, but I think you are suggesting a motive here based on facts not in evidence.
@First10EM I don't know exactly what it means when they refer to "anticipated loss of funding" - maybe when it became uncertain, they decided to stop this trial and redirect money towards other projects? It's hard to comment intelligently without more detail.
@First10EM In my opinion, making statements like this absent actual evidence undermines the faith in well-done RCTs that stop early for completely legitimate reasons.
@First10EM It suggests a cloak-and-dagger world where trial statisticians sit there hitting "refresh" on the analysis every day, then wink-wink let the investigators know when the results look good so they can stop the trial.
@First10EM Sounds good for a conspiracy novel, but simply not reflective of my experience in RCT's.
This is not to say all investigators are always on the up and up - I have absolutely worked with would-be authors that wanted to use QRP's - only to say that this is not reflective of how...
This is not to say all investigators are always on the up and up - I have absolutely worked with would-be authors that wanted to use QRP's - only to say that this is not reflective of how...
@First10EM ...anything has worked on any prospectively registered trial that I have been a part of.
@First10EM Anyway, the reason I find this disturbing is that I worry it makes clinicians who read your blog skeptical of basically *all* trials, the logical endpoint of which seems to be that we should not perform any medical practice at all.
@First10EM Can you give me an example of a trial that you think was sufficiently well-carried-out, analyzed and reported well, which warranted adopting a practice? Because from the times (admittedly perhaps a biased selection) I have read your blog, one would conclude…
@First10EM Trials that show big effects and stop early can’t be trusted – they overestimate effect sizes!
Trials that show big effects and run to completion can’t be trusted because it’s not plausible that the effect size could be that big!
Trials that show big effects and run to completion can’t be trusted because it’s not plausible that the effect size could be that big!
@First10EM Trials that show small effects don’t warrant changing practice because the effect sizes are small!
Therapies that haven’t been tested in trials shouldn’t be adopted without high-quality evidence!
Therapies that haven’t been tested in trials shouldn’t be adopted without high-quality evidence!
@First10EM So it would help me understand where you are coming from, I think, if I saw an example of a trial where you thought “This trial did everything right, and makes me think we should adopt this practice.”
@First10EM IN CONCLUSION
I think this is important because perpetuating myths about trial design and statistics undermines faith in legitimate efforts to generate high-quality evidence because people misunderstood a half-truth they read in a blog post somewhere.
I think this is important because perpetuating myths about trial design and statistics undermines faith in legitimate efforts to generate high-quality evidence because people misunderstood a half-truth they read in a blog post somewhere.
@First10EM Collectively, this thinking has harmed efforts to use more innovative trial designs that (potentially) could get answers faster with fewer patients exposed because large segments of the clinical audience are made skeptical of even *basic* trial practices like interim analyses
@First10EM (okay, now I'm actually done)