
And I might be going to livetweet it a little bit. For funsies!
Laurent works for @datadoghq, who has 10000s of hosts, 10s of clusters, up to 2500 nodes per cluster. (Not all clusters that big of course.) They're multi-cloud and ingest trillions of data points per day.
"Sure but are you webscal-💥🔫"
"Sure but are you webscal-💥🔫"
@datadoghq Kubernetes control planes: from the simple, theoretical architecture of "Kubernetes 101", to the not-so-simple, but very real architecture that you want when running thousands of nodes. #LISA19 @lbernail 
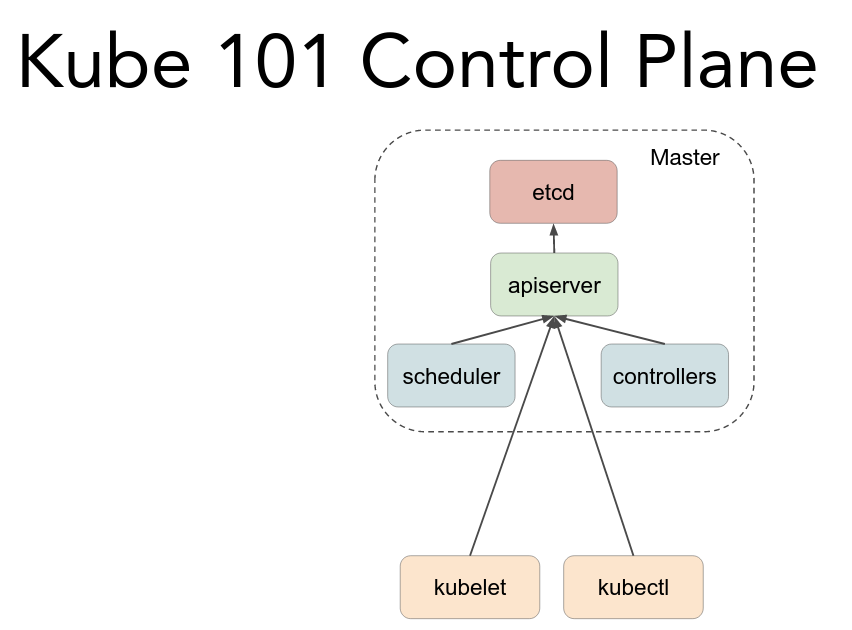
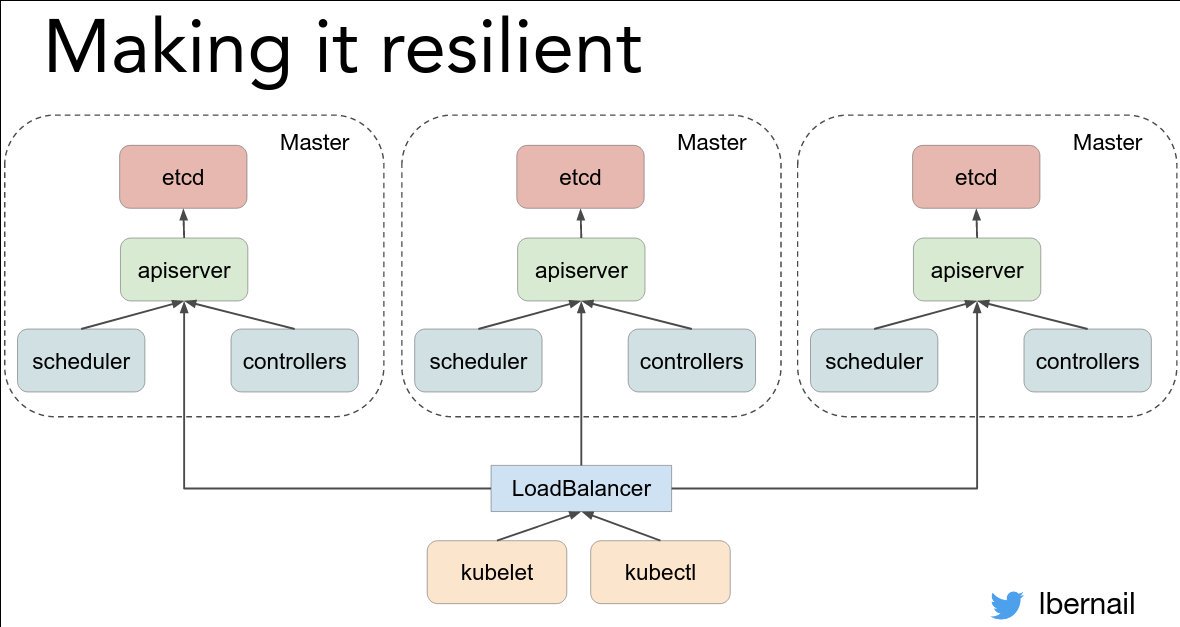
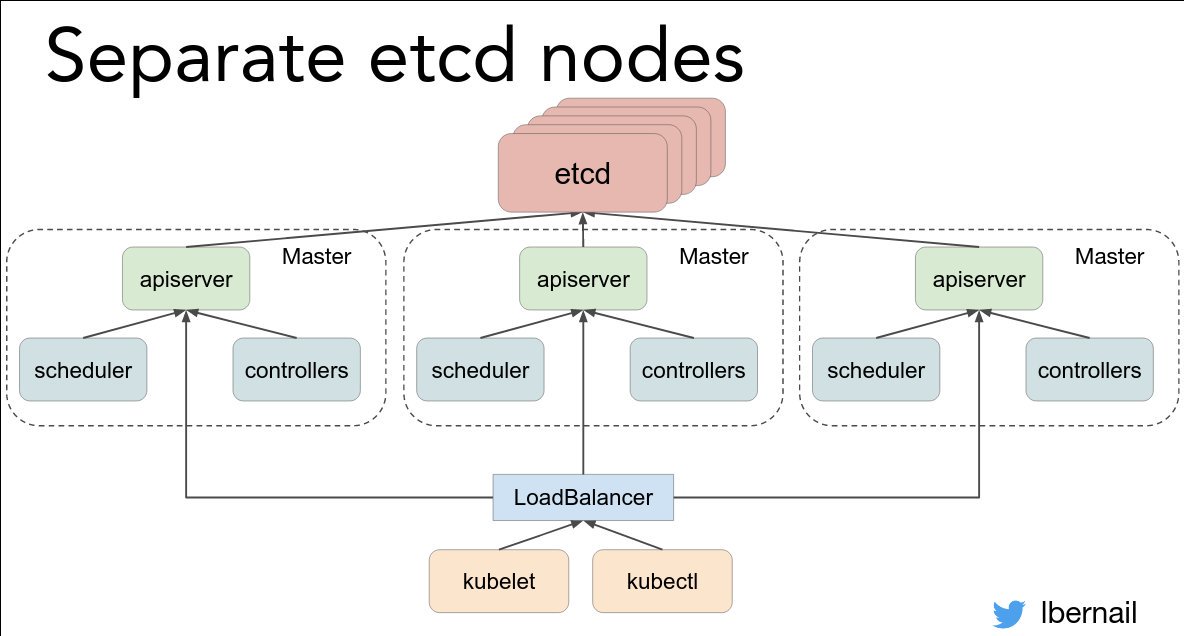
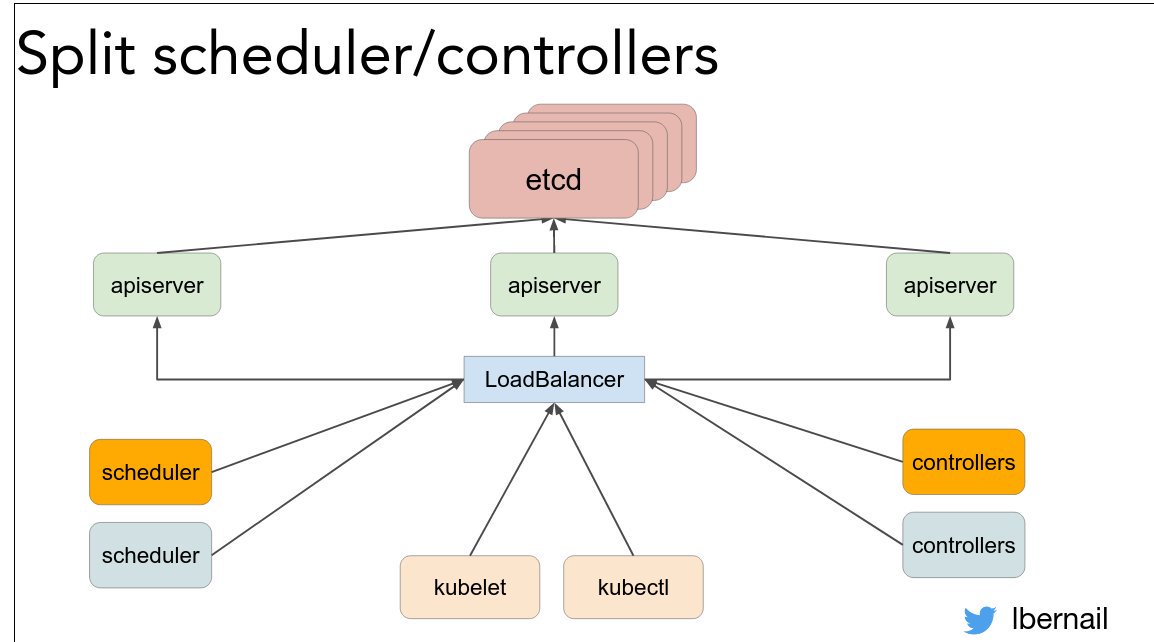
@datadoghq @lbernail Certificate management in Kubernetes is hard. One recommendation: rotate certificates often. Like, *daily*. Because the only way to make sure that an operation works like clockwork, is to do it regularly. Rotating certificates yearly = a ticking timebomb!
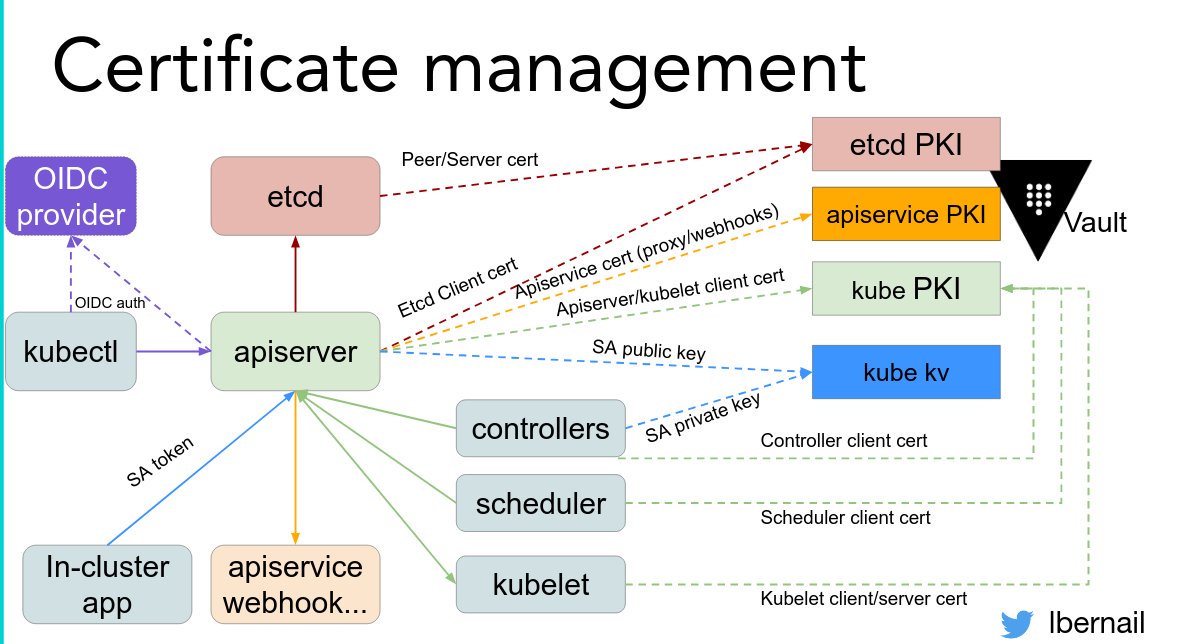
@datadoghq @lbernail Laurent explains that they had two places where certificate rotation happened yearly, and ... both places, they ran into issues. First one was for kubelet cert renewal, because (TL,DR) cert issuance uses group system:bootstrappers but renewal uses system:nodes.
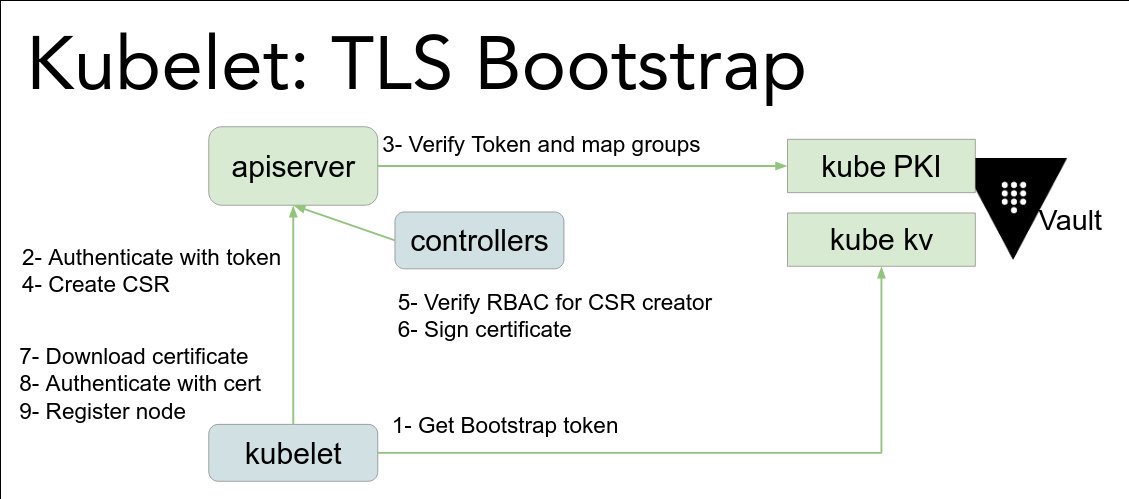
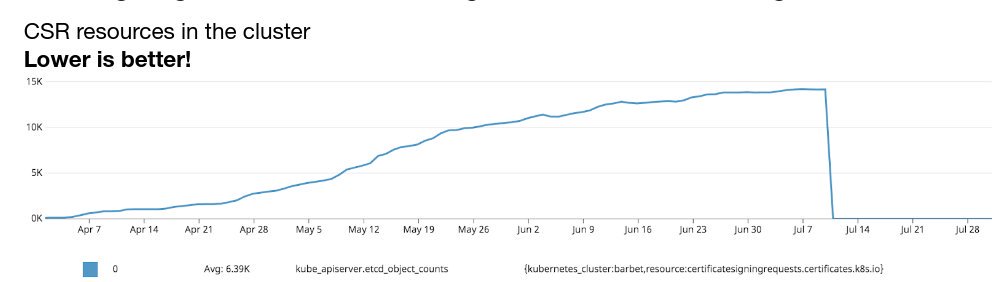
@datadoghq @lbernail The second one was for some CRD.
Takeaway: "If something is hard, do it often!" @lbernail #LISA19
(See also: devops, software deployment, etc. :))
Takeaway: "If something is hard, do it often!" @lbernail #LISA19
(See also: devops, software deployment, etc. :))
@datadoghq @lbernail Laurent is now talking about the impact of API server restarts on etcd. When API server restarts, it reloads caches from etcd, and on big clusters, that's a significant impact.
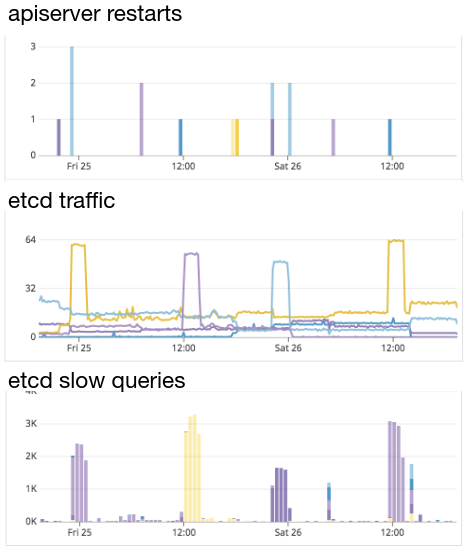
@datadoghq @lbernail Same thing with coredns when API server restarts. It's also interesting to see the total data transfer on these API servers. That's close to 100 Mb/s one a *single* API server (for old farts like me who still count in Mb/s) and there are ... 7 API servers on that graph? 😱
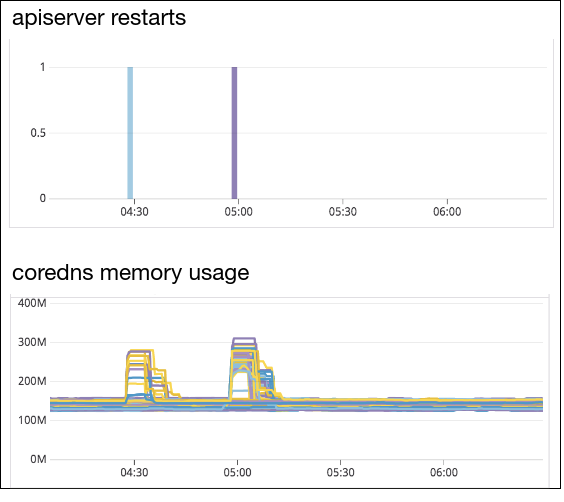
@datadoghq @lbernail Now Laurent tackles the networking aspects.
The constraints that they have at Datadog are just blowing up all the normal assumptions about anything.
Huge traffic, low-latency is required, 1000+ nodes cluster, lots of cross-cluster traffic, requires integration with VMs, too. 🤯
The constraints that they have at Datadog are just blowing up all the normal assumptions about anything.
Huge traffic, low-latency is required, 1000+ nodes cluster, lots of cross-cluster traffic, requires integration with VMs, too. 🤯
@datadoghq @lbernail Small clusters can use simple, efficient solutions.
Medium clusters can use overlays, which are nice but have overhead.
Big clusters with perf requirements will need to use native pod routing, i.e. make sure that the cloud fabric can carry pod traffic like 1st class traffic.
Medium clusters can use overlays, which are nice but have overhead.
Big clusters with perf requirements will need to use native pod routing, i.e. make sure that the cloud fabric can carry pod traffic like 1st class traffic.



@datadoghq @lbernail On AWS, that means using e.g. ENI (~dedicated cloud network interfaces) for your pods. There are a few CNI plugins available.
Laurent is giving a big shoutout to the @lyfteng CNI plugin and to @ciliumproject 💯
Laurent is giving a big shoutout to the @lyfteng CNI plugin and to @ciliumproject 💯
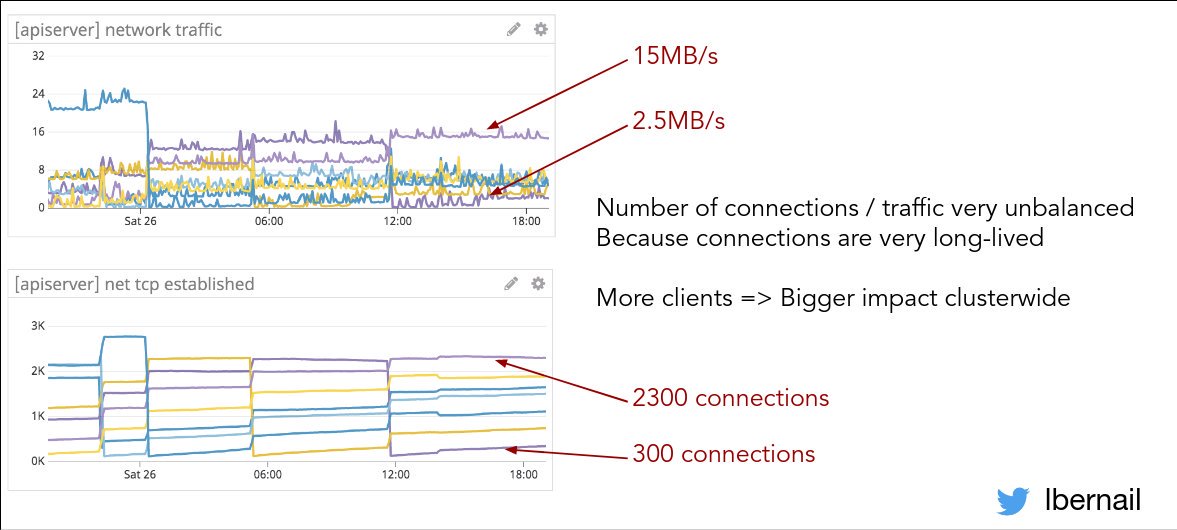
@datadoghq @lbernail @lyfteng @ciliumproject Next up: internal traffic, specifically, when connecting to ClusterIP. This is implemented by kube-proxy, which by default, users iptables, in a way that doesn't scale if you have MANYMANYLOTS services.
Switching to IPVS helps, ... BUT !!!
Switching to IPVS helps, ... BUT !!!

@datadoghq @lbernail @lyfteng @ciliumproject There are some nasty, nasty issues with IPVS connection tracking when a backend disappears without a trace (e.g. a node crashes, "because of a kernel panic, or because... it's the cloud, you know" 🤣☁️🌩).
What happens then?
What happens then?
Then some traffic keeps going to that dead destination for a few minutes.
There are a few other scenarios; overall, mitigations include:
- sysctl net/ipv4/vs/expire_nodest_conn
- setting backend weight to 0
- lower tcp_retries2
There are a few other scenarios; overall, mitigations include:
- sysctl net/ipv4/vs/expire_nodest_conn
- setting backend weight to 0
- lower tcp_retries2
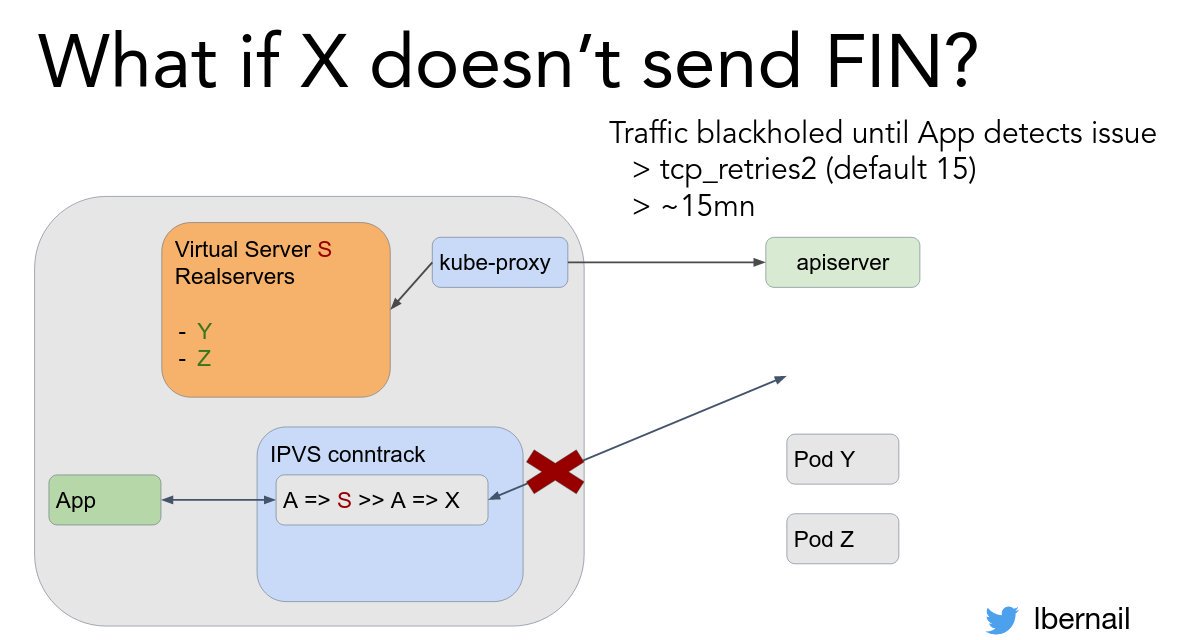
WARNING: if you troubleshoot Kubernetes and IPVS a lot, you might accidentally end up becoming a maintainer! At least, that's what happened to Laurent in that process. 🤷🏻♂️
Laurent now talks about ingress.
The current status quo is that the cloud load balancer sends traffic to a random node, which then bounces the traffic to the node running the backend pod.
It would be better to send traffic directly from load balancer to pod!
The current status quo is that the cloud load balancer sends traffic to a random node, which then bounces the traffic to the node running the backend pod.
It would be better to send traffic directly from load balancer to pod!


Another tricky thing: registration delay. When doing a rolling update, internal load balancers are updated in seconds, but external load balancers might take much longer.
Mitigation: check Pod ReadinessGates!
Mitigation: check Pod ReadinessGates!
Other topics not addressed today by Laurent:
DNS (it’s always DNS!)
Challenges with Stateful applications
How to DDOS <insert ~anything> with Daemonsets
Node Lifecycle
Cluster Lifecycle
Deploying applications
He could easily deliver a talk or two or five on ~each~ of them!
DNS (it’s always DNS!)
Challenges with Stateful applications
How to DDOS <insert ~anything> with Daemonsets
Node Lifecycle
Cluster Lifecycle
Deploying applications
He could easily deliver a talk or two or five on ~each~ of them!
And to wrap up, a few resources:
“Kubernetes the very hard way at Datadog”
“10 ways to shoot yourself in the foot with Kubernetes”
“Kubernetes Failure Stories”
k8s.af
Thanks Laurent for sharing all this! 💯
“Kubernetes the very hard way at Datadog”
“10 ways to shoot yourself in the foot with Kubernetes”
“Kubernetes Failure Stories”
k8s.af
Thanks Laurent for sharing all this! 💯










