It's my ten year anniversary at AWS, I got a new badge and everything! To celebrate, I'm going to tweet out the lightning talk I gave at last week's Amazon dev con. It's all about my favorite thing from my ten years: Shuffle Sharding! 

Ever wonder how we manage multi-tenancy at AWS? or why we want you to use the personal health dashboard instead of the AWS status dashboard? are you pining for a bonus content section with probabilistic math? These slides on Shuffle Sharding are for you!!
O.k., so this is me, 15 years ago, building a data center. That's what I used to do for money. This one was about 30 racks, and I was the project lead. It took me about a year to build it, everything from initial design to labeling cables.

These days I work with the AWS ELB team, and we regularly spin up that same amount of capacity in minutes. Think software upgrades or new region builds. This is insane to me. What took me a year now takes me me minutes. That's Cloud.
Our Cloud gives us this agility because we all pool our resources. So a much bigger, and better than me, team can build much bigger, and better than mine, data centers, which we all share. 10 years in, pretty much everyone understands that this is awesome.
BUT ... it comes with a challenge. When I built my own data centers, I was the only tenant and didn't need to worry about problems due to other customers. The core competency of a cloud provider is handling this challenge: efficiency and agility but still a dedicated experience.
It's no good sharing everything if a single "noisy neighbor" can cause everyone to have a bad experience. We want the opposite! At AWS we are super into compartmentalization and isolation, and mature remediation procedures. Shuffle Sharding is one of our best techniques. O.k. ..
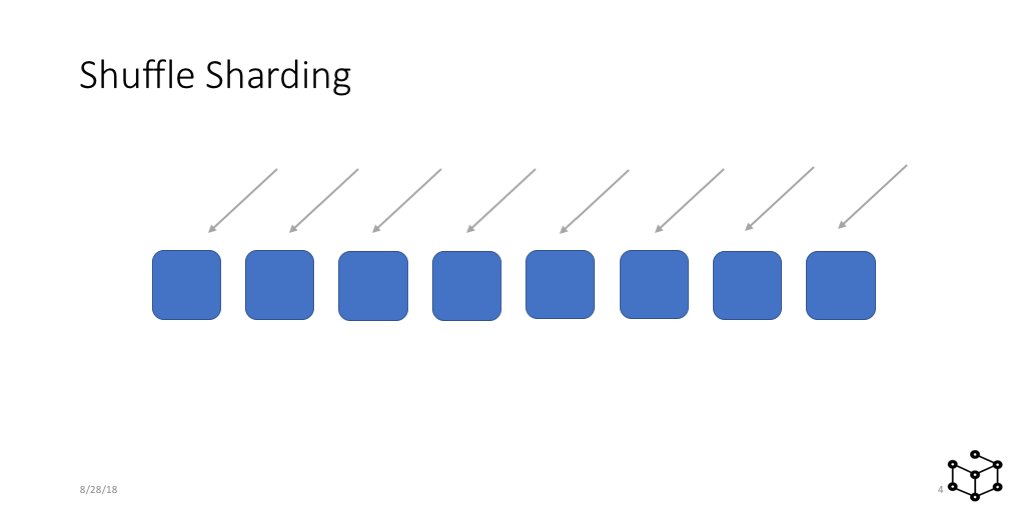
So to understand Shuffle Sharding, let's start with a traditional service. Here I have 8 instances, web servers or whatever. It's horizontally scalable, and fault tolerant in the sense that I have more than one instance.

We put the servers behind a load balancer, and each server gets a portion of the incoming requests. LOTS of services are built like this. Super common pattern. You're probably yawning!
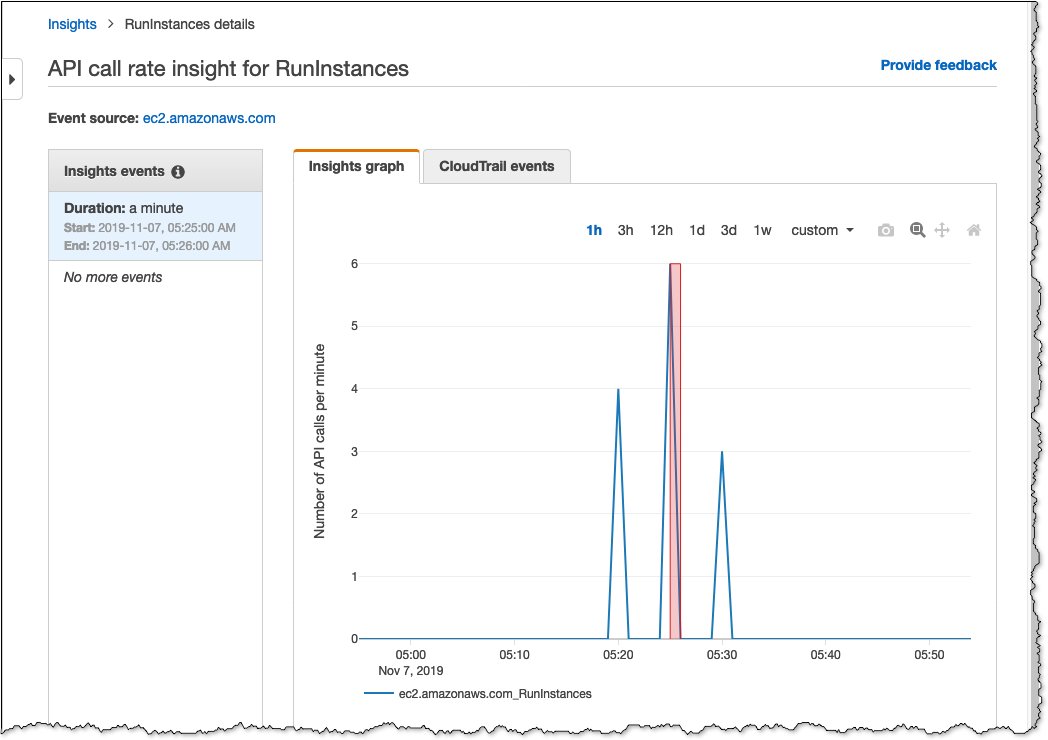
And then one day we get a problem request. Maybe the request is very expensive, or maybe it even crashes a server, or maybe it's a run-away client that is retrying super aggressively. AND it takes out a server. This is bad.
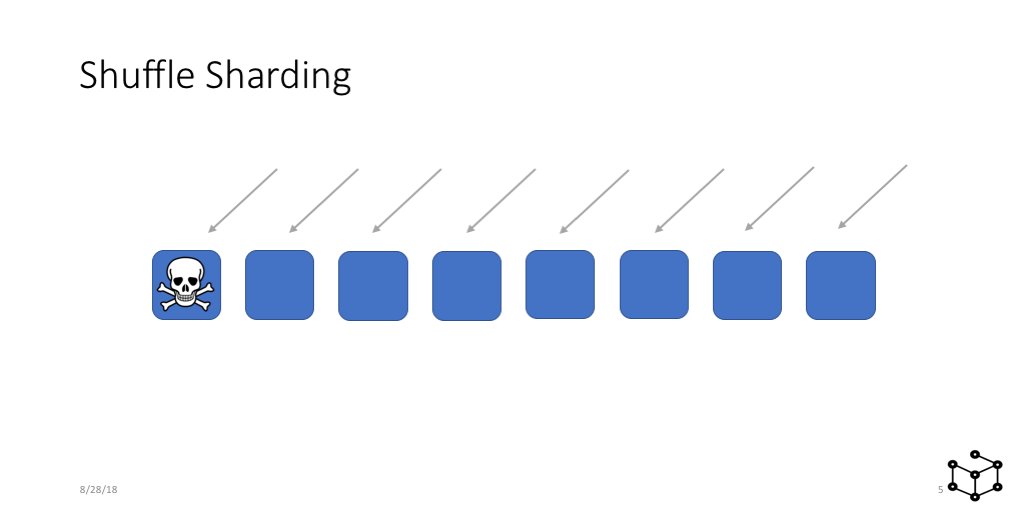
What's even WORSE is that this can cascade. The load balancer takes the server out, and so the problem request goes to another server, and so on. Pretty soon, the whole service is down. OUCH. Everyone has a bad day, due to one problem request or customer.
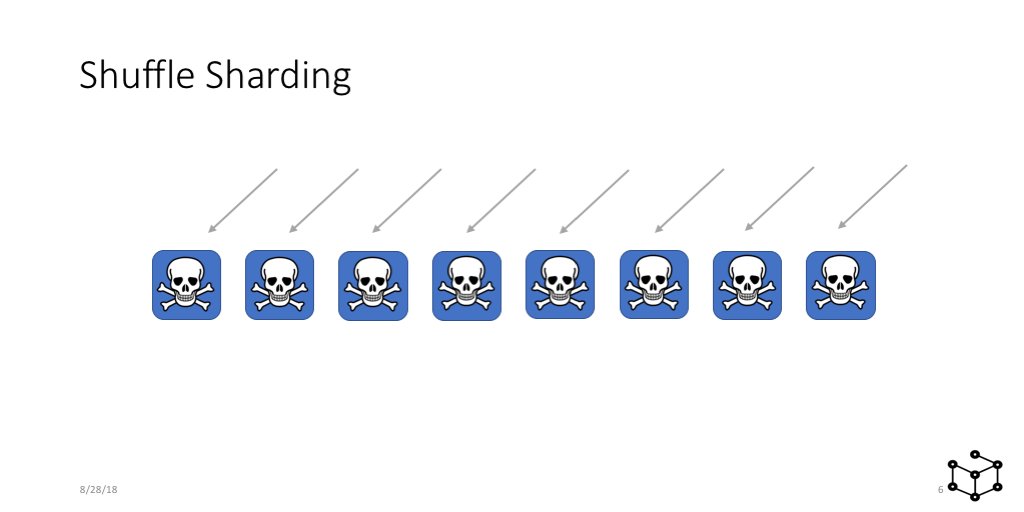
At AWS we have a term the scope of impact that we call "Blast Radius". And here the blast radius is basically "All customers". That's about as bad as it gets. But this is really common! Lot's of systems are built like this out in the world.

O.k., so what can we do? Well traditional sharding is something that we can do! We can divide the capacity into shards or cells. Here we go with four shards of size two. This change makes things much better!

Now if we repeat the same event, the impact is much smaller, just 25% of what it is was. Or more formally ...

The blast radius is now the number of customers divided by the number of shards. It's a big improvement. Do this! At AWS we call this cellularization and many of our systems are internally cellular. Our isolated regions, and availability Zones are a big famous macro example too.

THIS is one reason why the personal health dashboard is so much better than the status page. The status for your cell might be very different than someone else's!
... anyway, back to Shuffle Sharding. With Shuffle Sharding we can do much better again than traditional sharding. It's deceptively simple. All we do is that for each customer we assign them to two servers pretty much at random.

So for example, the ❤️ customer is assigned to nodes 1 and 4. Suppose we get a problem request from ❤️ ? What happens?
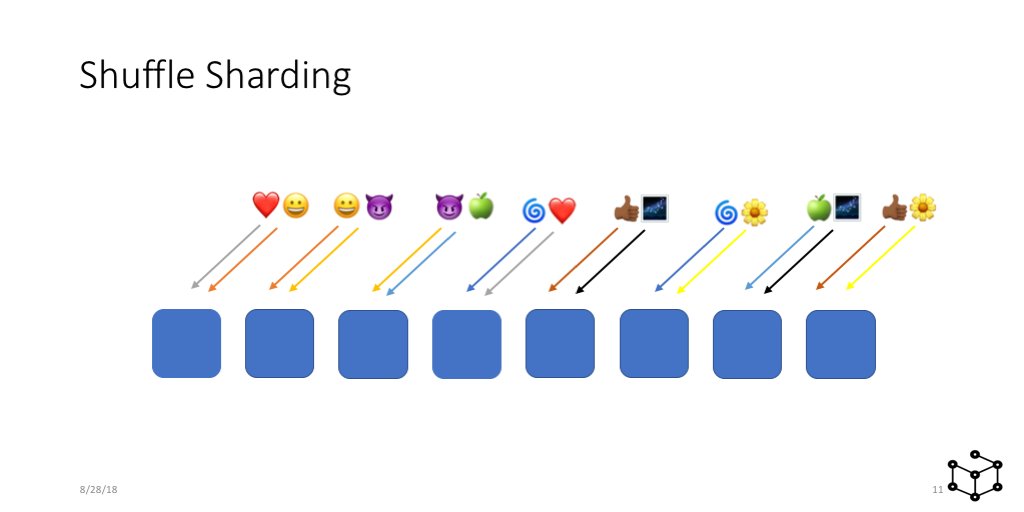
Well ... it could take out nodes 1 and 4. So ❤️ is having a bad experience now. Amazing devops teams are on it, etc , but it's still not great for them. Not much we can do about that. But what about everyone else?

Well, if we look at ❤️'s neighbors. They're still fine! As long as their client is fault tolerant, which can be as simple as using retries, they can still get service. 😀 gets service from node 2 for example.

O.k. let's PAUSE for a second and appreciate that. Same number of nodes. Same number of nodes for each customer. Same number of customers. Just by using MATH, we've reduced the blast radius to 1 customer! That's INSANE.
The blast radius ends up getting really small. It's roughly proportionate to the factorial of the shard size (small) divided by the factorial of the number of nodes (which is big) ... so it can get really really small.

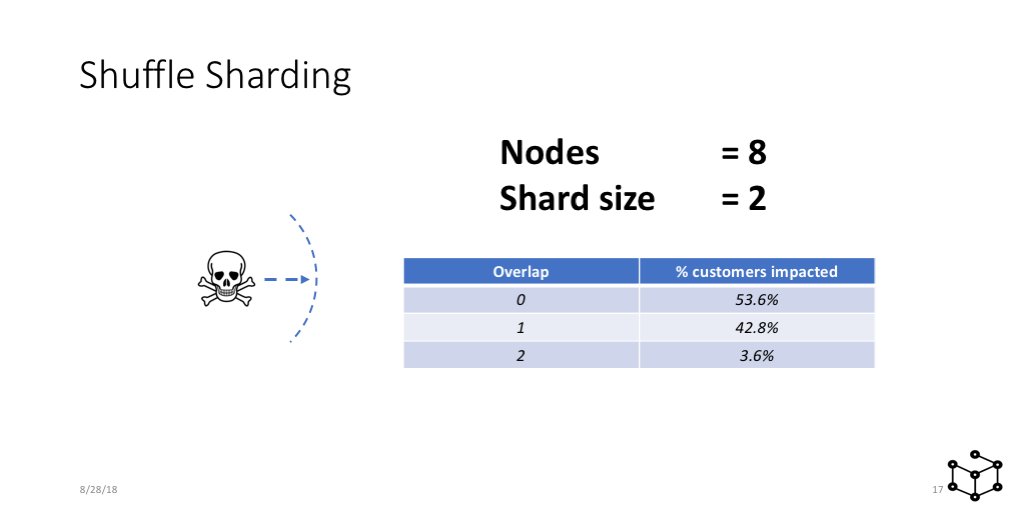
Let's look at example. So for 8 nodes and a shard size of 2, like these slides fit, the blast radius ends up being just 3.6%. What that means is that if one customer triggers an issue, only 3.6% of other customers will be impacted. Much better than the 25% we saw earlier.
But that's still way to high for us. AWS HyperPlane, the system that powers VPC NAT Gateway, Network Load Balancer, PrivateLink, etc ... we design for a hundred nodes, and a shard size of five. Let's look at those numbers ...
O.k. now things get really really small. About 0.0000013% of other customers would share fate in this case. It's so small that because we have fewer than a million customers per cell anyway, there can be zero full overlap.

Again think about, we can build a huge big multi-tenant system with lots of customers on it, and still guarantee that there is *no* full overlap between those customers. Just using math. This still blows my mind.
If you want to try some numbers out for yourself, here's a python script that calculates the blast radius: gist.github.com/colmmacc/4a39a… . Try it for Route 53's numbers. There are 2048 Route 53 virtual name servers, and each hosted zone is assigned to 4. So n = 2048, and m = 4.
If you want to make your own Shuffle Shard patterns, and make guarantees about non-overlap, we open sourced our approach years ago. It's at: github.com/awslabs/route5…
Shuffle Sharding is amazing! It's just an application of combinatorials, but it decreases blast radiuses by huge factorial factors. So what does it take to use it in practice?
Well the client has to be fault-tolerant. That's easy, nearly all are. The technique works for servers, queues, and even things like storage. So that's easy too. The big gotcha is that you need a routing mechanism.

You either give each customer resource a DNS name, like we do for S3, CloudFront, Route53, and handle it at the DNS layer, or you need a content-aware router than can do ShuffleSharding. Of course at our scale, this makes sense, but not everyone.
O.k,. bonus MATH content!! I want to convince you that that rough approximation from earlier is correct, because with more insight we can make smarter decisions.

Shuffle Sharding is just like a lottery. Think about your nodes like the numbers in a lottery, and each customer gets a ticket with |shardsize| count of numbers. You want to measure the probability that two or tickets match.
First, we have to define some shorthand. N is the number of nodes. S is the shard size. O is the potential overlap between two tickets/customers. en.wikipedia.org/wiki/Lottery_m… has good background on how we then come to this equation ...
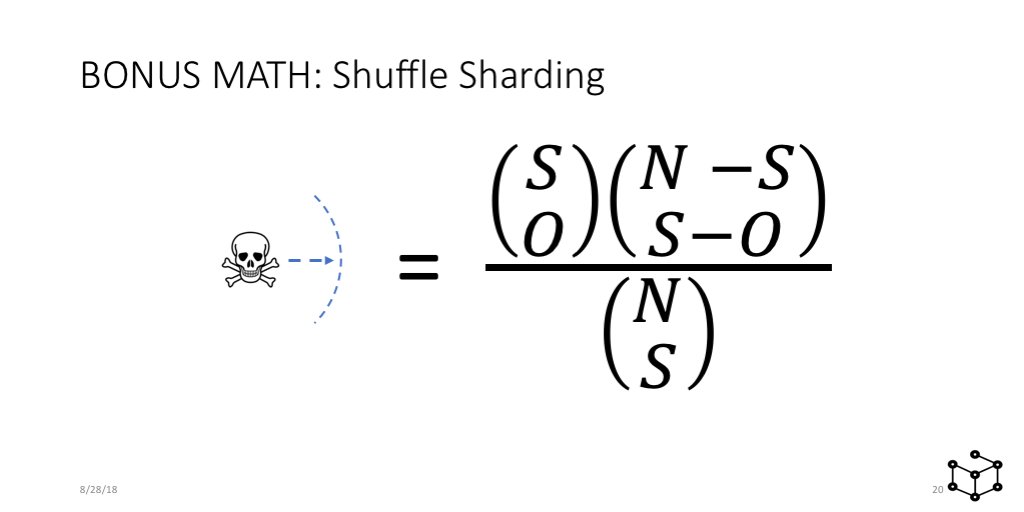
Now, let's take the special case of "full overlap". That's the case we care the most about; the problem request eats all of the nodes it can reach. How many other customers are impacted? Since O=S in this case, we end up with ...

The bracket notation is short for "choose" and since x choose x is 1, and x choose 0 is 1, we can replace everything above the line with 1.

Now let's expand the choose operator into its factorials ...

When you were about 10 you probably learned the reciprocal of a reciprocal is just to turn it upside down. That's still true. That gives us our final form ...

In that form it's pretty easy to see that the smaller S is relative to N, that Shuffle Sharding gets dramatically more and more effective! Convinced? I hope so!
That was my whole talk and it took me longer to tweet it than it did to give it on stage! Go figure. Feel free to AMA. And thanks for reading and making it to the end. Now use Shuffle Sharding anywhere that you can!