
Curious what people may mean when they say a neural network is (not) compositional? And how that relates to linguistics and philosophy literature on compositionality?
Check our new paper on compositionality in neural networks: arxiv.org/pdf/1908.08351…!
Check our new paper on compositionality in neural networks: arxiv.org/pdf/1908.08351…!

Whether neural networks are able to learn linguistic compositionally has been the topic of debate ever since neural networks were first used for natural language processing.
But what does it actually mean for a neural network to be compositional? What definition of compositionality is used? And how does this relate to the principle of compositionality and the vast amount of literature about this topic?
In this paper, we are explicit about different aspects of compositionality that may be considered important by different researchers, starting from linguistic and philosophical research about compositionality.
We propose five theoretically grounded tests and use them to diagnose three popular sequence to sequence architectures: a recurrent architecture, a convolution-based architecture and a transformer model.

We instantiate these tests on a strongly compositional artificial data set. But make sure the distribution of lengths and parse tree depths of the sentences match the distributions observed in a corpus with English sentences (WMT17)

We test if models can deal with this compositional data set at all;
If models can systematically recombine new pairs of words not seen in the training data;
If they can productivey generalise to input sentences that are longer than the ones they are trained on;
Under what conditions they infer that words are synonyms, and how they deal with that;
If they compute representations in a *localist* fashion, computing the meanings of all smaller parts first, or instead use the global composition operations.
And how much evidence they need to learn *exceptions* to rules. Do they *overgeneralise* when they are presented with exceptions during training?
Some teasers from our findings:
They do overgeneralise!
Convolution based models and Transformers first overgeneralise and then memorise the exception, LSTMs have difficulty accommodating both rules and exceptions.
(For the impact of the exception frequency, check the paper!)
Convolution based models and Transformers first overgeneralise and then memorise the exception, LSTMs have difficulty accommodating both rules and exceptions.
(For the impact of the exception frequency, check the paper!)

Although models generally have good scores on the task itself, they do not seem to compute the meanings of phrases in a localist fashion.
They do overgeneralise!
Convolution based models and Transformers first overgeneralise and then memorise the exception, LSTMs have difficulty accomodating both rules and exceptions.
(For the impact of the exception frequency, check the paper!)
Convolution based models and Transformers first overgeneralise and then memorise the exception, LSTMs have difficulty accomodating both rules and exceptions.
(For the impact of the exception frequency, check the paper!)

Although models generally have good scores on the task itself, they do not seem to compute the meanings of phrases in a localist fashion.
To take apart models' ability to correctly compute compositional meanings and to infer synonyms, for this test we look at their *consistency* rather than their accuracy. Also, we consider how close synonyms are in the embedding space.
Interestingly, even when the synonyms are distributionally dissimilar (but are identical wrt their 'translation'), transformer models put them close together in the embedding space.
When comparing the consistency of *incorrect* outputs, however, it seems that in the most difficult condition, none of the models really inferred that words were synonyms.
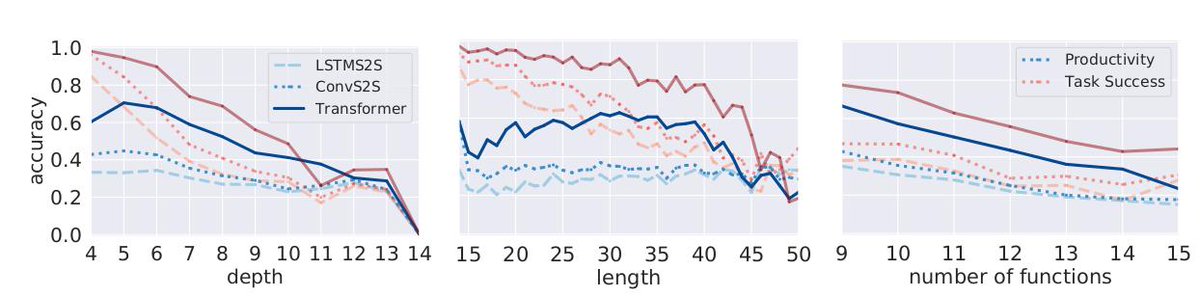
To assess models productivity, we redistribute the training data such that all long sequences are in the test data.
This allows us to compare models' accuracy when they *do* have evidence for a particular length of sequence and when they do not. We measure this in terms of different definitions of "length", such as number of tokens and parse tree depth.
Probably unsurprisingly to many, models are not very good at generalising to longer sequences.
Interestingly, this does *not* seem to stem from early emission of their end-of-sequence symbol (the "<eos>-problem"): For all architectures, the percentage of times the generated output is contained in the true output is less than 20%.
The systematicity scores for all models are surprisingly much lower than the scores for the overall data set, which also requires systematic recombinations of input words.
Why? What else? And what does this have to do with compositionality in natural language?
For more results, motivation and elaborate discussion, have a look: arxiv.org/pdf/1908.08351…!
For more results, motivation and elaborate discussion, have a look: arxiv.org/pdf/1908.08351…!









