I think I had a tough time communicating with @yudapearl today. It’s worth sharing where I think we ended up misunderstanding each other. I don’t think he is likely to agree with me, but it's useful for me to articulate here.
Here’s the seed tweet:
Here’s the seed tweet:
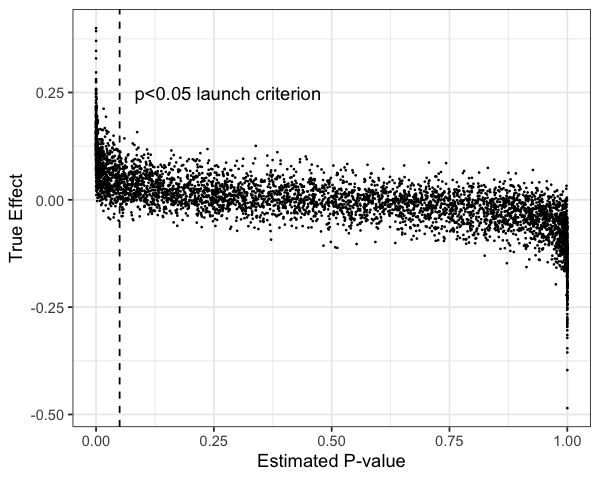
I shared the Meng paper because it’s a nice discussion of how greater sample size doesn’t solve estimation problems. This is part of a strong opinion I have that collecting adequate data is the key challenge in most empirical problems. Some people will not agree with this.
Most folks thought I was talking about causal inference from the start. I was actually talking about the tool of *randomization*. IMO, Meng’s paper is an example of measuring the value of randomization for an estimation problem. Randomness is a complement to sample size.
An underrated aspect of causal inference is designing a data collection process that makes estimation possible. You can’t produce a useful model without data! The practice of experimentation as a special case of collecting adequate data for a variety of causal inference problems.
Ask any empirical researcher: data availability is likely a fundamental constraint for making progress in their field. Data constrains what we can estimate. Because of scarcity, sometimes researchers work backward, finding data and figuring out what they can use it to estimate.
Two key tools of data collection are 1) randomization and 2) intervention. They form the basis for the widespread practice of experimentation. Intervention is what allows us to create effects, and randomization is how we measure those effects with less bias.
(Sidebar: Many common practices fit under this loose definition of experimentation: A/B tests, bandit algorithms, Bayesian optimization, reinforcement learning. They are dialog with the real world where we cause some change and the record the consequences.)
From my (obviously strong) experimentalist perspective, the goal of most people practicing causal inference is: *finding or making data* that can let them estimate the models they need, to answer the queries they have, or make the decisions they need to make.
I expect Pearl won't agree because he may see causal inference as orthogonal to the practice of people getting their data. For me, an empirical researcher, I’d rather have good data + a simple causal inference problem than messy data + a complex one (even with all Pearl’s tools).
Randomization is useful for data collection in surveys as well as experiments. It’s a more general tool than simply causal inference. The Meng concepts for survey data are portable to causal inference, you could derive a similar data quality measure given an ATE estimator.
I would love to see Pearl’s perspective applied to improving experimentation and collecting adequate data. I am not well versed in it enough to know if work in this direction exists. Personally, I have turned to the statistics literature to learn about these things.
Parting thought: as a causal inference practitioner it's valuable to to invest in understanding sampling, randomization, experimental design, etc. Projects are often limited by what data you can design + you need to critically evaluate data as being suitable for certain tasks.
If you got to this point, I appreciate you reading this. It's been really helpful for me to get these thoughts down, and I'd love to hear any feedback you have on any aspect.