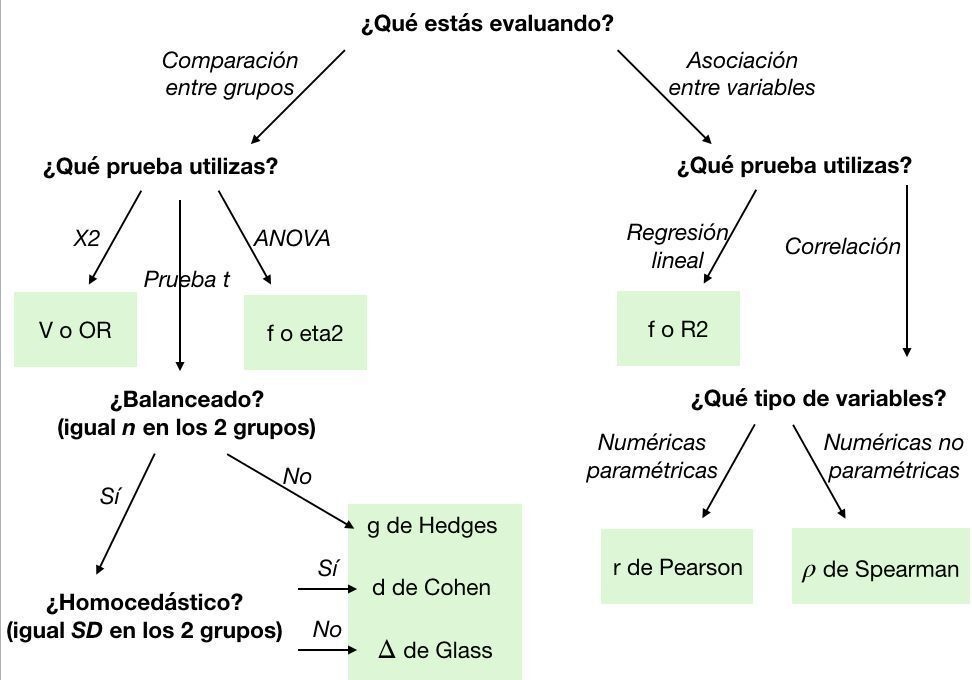
💥14 herramientas secretas impulsadas por #RStats para ahorrar tiempo y esfuerzo en tus proyectos de datos (¡No te lo pierdas!):👀
1️⃣ ¡Edita tus datos de forma interactiva (y guarda el código)! 👀
📦 'editData' es un complemento de RStudio para editar un data.frame o un tibble de forma interactiva
🔗 buff.ly/3U5Tgjy
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
📦 'editData' es un complemento de RStudio para editar un data.frame o un tibble de forma interactiva
🔗 buff.ly/3U5Tgjy
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
2️⃣ ¡Crea gráficos #ggplot de forma interactiva!🚀
📦esquisse es otro de mis addins favoritos de #rstudio
✅ exporta el gráfico o recupera el código para reproducir el gráfico
🔗 buff.ly/3mxLHSo
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
📦esquisse es otro de mis addins favoritos de #rstudio
✅ exporta el gráfico o recupera el código para reproducir el gráfico
🔗 buff.ly/3mxLHSo
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
3️⃣ ¡Elige los colores para tus gráficos de forma interactiva!
📦colourpicker te ayuda a elegir el color y lo actualiza en tiempo real para que puedas ver los cambios de inmediato
🔗 github.com/daattali/colou…
#datavisualization #dataviz #dataScientist #rstats #programmer #Colors
📦colourpicker te ayuda a elegir el color y lo actualiza en tiempo real para que puedas ver los cambios de inmediato
🔗 github.com/daattali/colou…
#datavisualization #dataviz #dataScientist #rstats #programmer #Colors
4️⃣ ¡Edita los themes de ggplot2 a golpe de click y personaliza tus gráficos!
📦 ggThemeAssist te permite elegir/ajustar cualquier detalle de tus gráficos
🔗 github.com/calligross/ggt…
#dataviz #dataScientist #Analytics #stats #datavisualization #tableau #BI #powerBI #RStats
📦 ggThemeAssist te permite elegir/ajustar cualquier detalle de tus gráficos
🔗 github.com/calligross/ggt…
#dataviz #dataScientist #Analytics #stats #datavisualization #tableau #BI #powerBI #RStats
5️⃣ ¡Visualiza series temporales en 1seg!📈
📦 tsviz es sencillo e interactivo
🔗 buff.ly/3ekxlSL
#datascience #analytics #timeseries #stats #DataAnalytics #data #cienciadedatos #BusinessProposal #BI #dataviz #DataVisualization #RStats #Python #SQL #Excel #powerbi
📦 tsviz es sencillo e interactivo
🔗 buff.ly/3ekxlSL
#datascience #analytics #timeseries #stats #DataAnalytics #data #cienciadedatos #BusinessProposal #BI #dataviz #DataVisualization #RStats #Python #SQL #Excel #powerbi
6️⃣ ¡Procesa variables categóricas rápidamente!
📦questionr reordena y recodifica fácilmente los factores, divide el rango de una variable numérica en intervalos
🔗 buff.ly/39QesbS
#DataManagement #DataAnalytics #DataScience #stats #statistocs #RStatsES #Analytics #RStats
📦questionr reordena y recodifica fácilmente los factores, divide el rango de una variable numérica en intervalos
🔗 buff.ly/39QesbS
#DataManagement #DataAnalytics #DataScience #stats #statistocs #RStatsES #Analytics #RStats

7️⃣ Explora tus datos con una sola línea de código y crea un informe automático
📦DataExplorer automatiza la mayor parte del manejo y visualización de datos
🔗 boxuancui.github.io/DataExplorer/
Similares: DataMaid, ExPanDaR, skimr, dlookr
#rstats #DataManagement #dataviz #Datavisualization
📦DataExplorer automatiza la mayor parte del manejo y visualización de datos
🔗 boxuancui.github.io/DataExplorer/
Similares: DataMaid, ExPanDaR, skimr, dlookr
#rstats #DataManagement #dataviz #Datavisualization
8️⃣ ¡Convierte tus análisis en documentos, informes, presentaciones y tableros reproducibles y de alta calidad!
✅ #RMarkdown (o #Quarto) une texto, código y resultados en un único documento
¡Adiós copy & paste, adiós errores!
🔗 rmarkdown.rstudio.com
✅ #RMarkdown (o #Quarto) une texto, código y resultados en un único documento
¡Adiós copy & paste, adiós errores!
🔗 rmarkdown.rstudio.com
9️⃣ Crea tableros interactivos para #RStats, utilizando #RMarkdown
📦 flexdashboard incluye texto, figuras/tablas estáticas o gráficos interactivos, ¡mediante código sencillo!
Puedes combinarlo con shiny, ggplotly y otros “widgets html”
🔗 pkgs.rstudio.com/flexdashboard/
#dataviz
📦 flexdashboard incluye texto, figuras/tablas estáticas o gráficos interactivos, ¡mediante código sencillo!
Puedes combinarlo con shiny, ggplotly y otros “widgets html”
🔗 pkgs.rstudio.com/flexdashboard/
#dataviz
🔟 ¡Crea los metadatos (YAML) de R Markdown de manera interactiva!
💥 ymlthis te permitirá crear informes reproducibles increíbles
🔗 buff.ly/3Re0ikR
#dataviz #DataVisualization #DataScience #data #Analytics #stats #statistics #programming #rstudio
💥 ymlthis te permitirá crear informes reproducibles increíbles
🔗 buff.ly/3Re0ikR
#dataviz #DataVisualization #DataScience #data #Analytics #stats #statistics #programming #rstudio
1️⃣1️⃣ ¡Visualiza paso a paso tus canalizaciones de datos!👀
📦ViewPipeSteps crea pestañas con la vista de datos con los resultados de las funciones encadenadas en tuberías (pipes %>%)
🔗 github.com/daranzolin/Vie…
#RStatsES #data #Database #DataManagement #datascience #DataAnalytics
📦ViewPipeSteps crea pestañas con la vista de datos con los resultados de las funciones encadenadas en tuberías (pipes %>%)
🔗 github.com/daranzolin/Vie…
#RStatsES #data #Database #DataManagement #datascience #DataAnalytics
1️⃣2️⃣ Analiza de manera sencilla las expresiones regulares
- Crea interactivamente tu expresión regular
- Busca coincidencia de cadenas
- Consulta la ayuda interactiva y los recursos incluidos para aprender expresiones regulares
🔗 github.com/gadenbuie/rege…
#rstats #datamanagement
- Crea interactivamente tu expresión regular
- Busca coincidencia de cadenas
- Consulta la ayuda interactiva y los recursos incluidos para aprender expresiones regulares
🔗 github.com/gadenbuie/rege…
#rstats #datamanagement
1️⃣3️⃣ ¡Si quieres estar a la última con todas las novedades de paquetes de #RStats apunta este addin!💥
- Busca paquetes relevantes
- Obtén metadatos del paquete
- Descubre paquetes
- Mantente al día con CRAN
🔗 buff.ly/2QBkrVP
#ML #IA #BigData #datamining #programming
- Busca paquetes relevantes
- Obtén metadatos del paquete
- Descubre paquetes
- Mantente al día con CRAN
🔗 buff.ly/2QBkrVP
#ML #IA #BigData #datamining #programming
1️⃣4️⃣¡Integra #chatgpt3 en tus análisis de datos con #RStats!
📦gpttools incluye:
📄comentarios de roxygen
💬código de explicación
🧪sugiere pruebas unitarias para funciones
🚀convierte scripts en funciones reutilizables
🔗 github.com/JamesHWade/gpt…
#ChatGPT #AI #ML #tech #Data
📦gpttools incluye:
📄comentarios de roxygen
💬código de explicación
🧪sugiere pruebas unitarias para funciones
🚀convierte scripts en funciones reutilizables
🔗 github.com/JamesHWade/gpt…
#ChatGPT #AI #ML #tech #Data
😉Sígueme para obtener más herramientas y recursos de #DataScience #ML #IA #RStats y aprende las mejores técnicas y enfoques.
¿Cuál es la herramienta que más te ha gustado de esta lista?, ¡Comenta abajo!👇
Si te resultó útil, ¡Comparte este hilo! 🤩
¿Cuál es la herramienta que más te ha gustado de esta lista?, ¡Comenta abajo!👇
Si te resultó útil, ¡Comparte este hilo! 🤩
https://twitter.com/RosanaFerrero/status/1618253373526147073?s=20&t=_Vi7cYiNfDz2a7wpC2C3dg
• • •
Missing some Tweet in this thread? You can try to
force a refresh