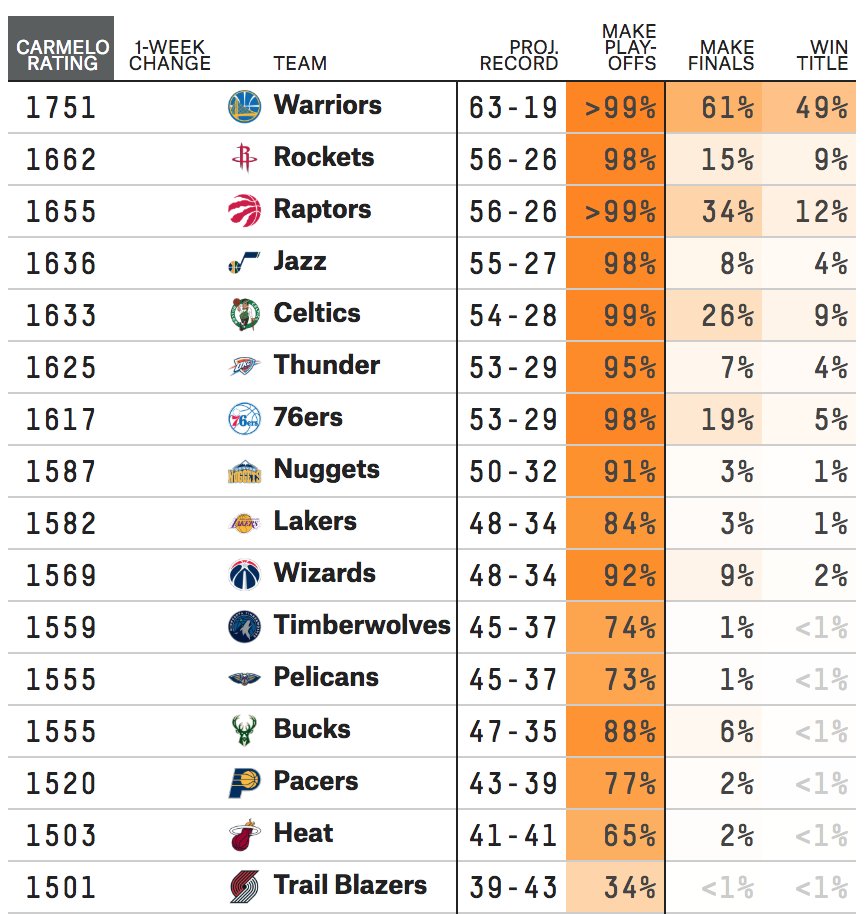
Today I'm at the "Methodology for Measurement of Learning in Learning Analytics" workshop at #LAK18, presented by @UllaRingtved, Linda Corrin, and @SandraMilligan3, and various guest speakers.
Follow this tread for updates.
Follow this tread for updates.
Here's an abstract of the workshop. #LAK18 

(3/n) 'What has happened in recent years in learning analytics is no different then what happened in the last 50-100 years in education, including the mistakes downfalls. However, in LA, the scope and influence of research has substantially increased, making it more dangerous'
(4/n) 'Today we'll talk a lot about measurement analytics, which is the combination of measurement theory, learning analytics, and educational science.'
(5/n) Discusses issued/concerns in measurement analytics:
- how to get actionable analytics?
- issues of data triangulation
- what do we measure?
- what do we NOT measure?
- quantity/quality of data
- lots of real-life education *doesn't* have big data
- data =! evidence
- how to get actionable analytics?
- issues of data triangulation
- what do we measure?
- what do we NOT measure?
- quantity/quality of data
- lots of real-life education *doesn't* have big data
- data =! evidence
(6/n) Shameless plug: a lot of these issues in/with measurement and learning analytics we discussed in our paper "Learning about Learning at Scale: Methodological Challenges and Recommendations". Link: dl.acm.org/citation.cfm?i….

(7/n) Now talking about measuring aptitude (knowledge, skills, etc), which is 'becoming increasingly important'. Today a strong dominance of numerical test approaches (e.g., school grades, IQ).
(8/n) IQ is given as a good and bad example of the above. (my opinion: it's bit presented as a straw man version of IQ, but ok)
(9/n) Other approach: Knowledge Space Theory (KST). Focus on (knowledge/performance) items and the mastery of these individual items. Came up with 'surmise relations': 'if you master X, we can assume (surmise) that you can perform Y to some extent'.
(10/n) This is how you can model an elaborate knowledge space, with various mathematical properties, such as being transitive, anti-symmetric, reflexive, and a closed system.
(11/n) This later evolved into 'Competence-based Knowledge Space Theory', which separates competence and performance. Typically includes 'many-to-many' relations between these different items, each with different weights.
(12/n) Question: how does this compare to latent construct modeling? Answer: this is much more top-down, with experts creating the knowledge space, while latent-construct modeling is much more bottom-up and data driven. Both have (dis)advantages.
(13/n) Discussant: this talk is a good example showing that and how learning analytics should go beyond 'theory blind' data analyses. You *need* theory.
(14/n) New talk, on sentiment analysis in forum posts (in MOOCs). Two, complementary approaches: a machine learning approach, and a semantic dictionary approach.
(15/n) Interesting practical problem: icons and emoijs aren't covered in standardized sentimental analysis dictionaries. E.g., in Chinese (context of this study), "2333" is used to signify what we know as 'LOL'.
(16/n) Downside of relying on forum discussions: students active on the forum score substantially higher than the average student (grade 32.6 vs 0.6), so it's a highly non-typical student.
(17/n) Sentiment analysis outcomes: many posts containing negative sentiments relate to questions about assignments, quizzes, and not learning attitudes. Many post intentions are to see help. In 90% of the cases this help is also provided. #LAK18
(18/n) Suggestions to improve MOOC design: 1) stimulate & facilitate students to actively ask questions on the forums, 2) provide mutual help on the forums (by students and teachers alike).
(19/n) Comments by audience/discussant: in these models it's vital to look at correlations between the predictors because you often run into a problem a multicollinearity. #LAK18
(20/n) Discussant: in our research we found that people who have posts which receive negative responses typically do very well. Why? Because these are often the students who challenged the status quo, which often gets some negative feedback. #LAK18
(21/n) Moving on, Rianne Conijn (Tilburg University) about "What's (not) in a keystroke". #LAK18
(22/n) With keystroke logging you collect every keystroking, while enables a much more fine-grained look at the writing process.
(23/n) Has been used to:
- predict writing quality & essay scores
- distinguish skilled from less skilled writers
- to determine boredom and engagement
- to assess mental ability
- to determine the tasks' cognitive load
- predict writing quality & essay scores
- distinguish skilled from less skilled writers
- to determine boredom and engagement
- to assess mental ability
- to determine the tasks' cognitive load
(24/n) Combine keylogs with self-reported writing style for a more comprehensive overview of the writing process.
(25/n) About 3% of keystrokes labeled as (initial) planning. About 16% as deletion. No relation between keystroke planing features and self-reported writing styles.