Looking for Scrolly Tales? Check out these recent candidates

@DefiyantlyFree Postliberalism's core rejection of Enlightenment liberalism embedded in the American Founding—individual rights, church-state separation, and negative liberty—favoring instead state promotion of virtue, hierarchy, and common good,
1)
1)
@DefiyantlyFree marks a sharp break from William F. Buckley conservative fusionism's defense of limited government and the liberal order.
JD Vance's alignment with thinkers like Deneen positions him as advancing postliberal ideas under Trump's umbrella,
2)
JD Vance's alignment with thinkers like Deneen positions him as advancing postliberal ideas under Trump's umbrella,
2)
@DefiyantlyFree but with potential divergences on foreign policy restraint vs. American exceptionalism and superpower status, highlighting internal right-wing tensions over whether to conserve or transcend the Republic's foundational principles.
3)
3)

1HILO ¿MANCHEGOS DE MANCHESTER? (Memoria Histórica)
Que no corra la voz, pero los millones de turistas británicos que visitan España en el verano, en realidad, regresaban a la tierra de sus ancestros...+
Que no corra la voz, pero los millones de turistas británicos que visitan España en el verano, en realidad, regresaban a la tierra de sus ancestros...+

2 Hace unos años el profesor de Oxford Bryan Sykes, realizó una investigación genética que desmontó la teoría de que los celtas provienen de tribus de Centroeuropa. Publicó los resultados en su LIBRO «Blood of the Isles» (en español , «La sangre de las Islas»).

3 Analizaron material genético de personas de origen celta y de habitantes de la costa cantábrica. El ADN de ambos grupos era prácticamente idéntico
La explicación: los ingleses provienen de un grupo de pescadores que salió de la Península Ibérica hace unos 6.000 ó 7.000 años.
La explicación: los ingleses provienen de un grupo de pescadores que salió de la Península Ibérica hace unos 6.000 ó 7.000 años.


The Bovine Growth Hormone issue goes to just one single company: Eli Lilly. We need public pressure, exposure and/or divest of this chemical. It is why US milk differs from Canadian milk and dairy and beef.
Dr. Shiv Chopra helped to stop the use of Bovine Growth Hormone in Beef in Canada but milk from US is still coming into Canada with it. This is the photo I took of him in 2017.

May 31 2017 at a UW event called Water is Life. The event Featured Dr. Vandana Shiva, Maude Barlow, Chief Leslee White-Eye & Dr. Shiv Chopra. He warned us about the use of Bovine Growth Hormones in use in Canada. The Calves exposed were being shipped here and US was pressuring Canada to sell their milk which contained it.


@CerfiaFR Ce genre de classement, c'est vraiment n'importe quoi car basé sur le nombre d'habitants "intramuros" sans prendre en compte l'agglomération ou l'air d'attraction (ou "banlieue de").
1/n
1/n
@CerfiaFR Classement ridicule faisant alors concourir Poitiers (IntraMuros : 10k hab. | Agglo : 135k | Zone d'Attraction : +300k) avec Rouen (120k | 500k | 700k = Nice), avec Saint-Germain-en-Laye (46k | 11M d'habitants (ZA de Paris) !
2/n
2/n
@CerfiaFR … et donc aux richesses & subventions totalement disproportionnées, et/ou sans prendre en compte le type de population : Pessac & Saint-Germain-en-Laye sont 2 banlieues bourgeoises de grande villes Bordeaux & Paris).
3/n
3/n

I recently spoke at the 2026 International Working Group (IWG) on Women and Sport.
Here are my slides.
Here are my slides.

Sport seeks to identify and reward talent.
We want to find the best swimmers and the best boxers. Athletes with the physicality, skill and mental strength to win.
And we identify and reward talent by measuring performance.
But performance is an output, and not just of talent.
We want to find the best swimmers and the best boxers. Athletes with the physicality, skill and mental strength to win.
And we identify and reward talent by measuring performance.
But performance is an output, and not just of talent.

Nurturing matters. Environment matters. Having an athletic parent matters.
Nurture can obscure talent.
But differential nurture is, at least in principle, fixable.
Nurture can obscure talent.
But differential nurture is, at least in principle, fixable.


Ok this is going to be a long one. For all our sakes, let’s stop obsessing over individual chip specs and upgrade to systems-level thinking
1/15 🧵
Part I: The Facts
The CloudMatrix 384 superpod draws ~560 kW IT power. Huawei has sold 750 *= ~420 MW. cnstock.com/commonDetail/7… x.com/ChrisRMcGuire/…
1/15 🧵
Part I: The Facts
The CloudMatrix 384 superpod draws ~560 kW IT power. Huawei has sold 750 *= ~420 MW. cnstock.com/commonDetail/7… x.com/ChrisRMcGuire/…
2/15
That's not enough for this mystery AIDC alone, but Huawei doesn't just sell pods. It sells nodes and cards.
Further, Huawei is not the only domestic player. Alibaba T-HEAD, Kunlunxin, MetaX, Biren, Moore Threads, and Enflame have all deployed tens of thousands of cards into individual clusters.machineyearning.io/p/chinas-silic…
That's not enough for this mystery AIDC alone, but Huawei doesn't just sell pods. It sells nodes and cards.
Further, Huawei is not the only domestic player. Alibaba T-HEAD, Kunlunxin, MetaX, Biren, Moore Threads, and Enflame have all deployed tens of thousands of cards into individual clusters.machineyearning.io/p/chinas-silic…
3/15
“nobody has ever torn down a single–” SemiAnalysis just completed a teardown of Huawei’s Kirin 9030 smartphone chip, revealing SMIC is near pitch parity with Intel's leading 18A node. Careful putting more eggs in the “China can’t make chips” basket.
“nobody has ever torn down a single–” SemiAnalysis just completed a teardown of Huawei’s Kirin 9030 smartphone chip, revealing SMIC is near pitch parity with Intel's leading 18A node. Careful putting more eggs in the “China can’t make chips” basket.

GLP-1's do NOT cause muscle loss... at least not directly
Despite the rhetoric on social media from wellness influencers, GLP-1's are not catabolic
Yes, if you lose weight with GLP-1's and do not exercise, you will lose lean mass...
But it is no more than the amount of lean mass that is lost by people who lose weight without GLP-1s & don't exercise
Despite the rhetoric on social media from wellness influencers, GLP-1's are not catabolic
Yes, if you lose weight with GLP-1's and do not exercise, you will lose lean mass...
But it is no more than the amount of lean mass that is lost by people who lose weight without GLP-1s & don't exercise
GLP-1s can indirectly contribute to losing lean mass because they are powerful appetite suppressants
This enables people to enter a deeper calorie deficit and lose weight faster. Faster weight loss = more loss of lean mass
People who don't have much appetite are typically not choosing high protein sources since they tend to be more satiating and this can also contribute
This enables people to enter a deeper calorie deficit and lose weight faster. Faster weight loss = more loss of lean mass
People who don't have much appetite are typically not choosing high protein sources since they tend to be more satiating and this can also contribute
Many fitness coaches will try to scare you about GLP-1s because they are scared they will lose business
To be honest, GLP-1s have probably cost me business but I am not against them. If it helps people get healthy, then I am all for it
But they are not a replacement for lifestyle changes, rather use them as a springboard to help with lifestyle changes
To be honest, GLP-1s have probably cost me business but I am not against them. If it helps people get healthy, then I am all for it
But they are not a replacement for lifestyle changes, rather use them as a springboard to help with lifestyle changes

@choicehotels is blatantly ripping off its frequent guests by refusing to adhere to it's own T&Cs. 1/
I had 45K or so points with Choice privileges. I read the rules online, , and it says that to keep the points active, you have to do a "qualifying activity," which includes "redeeming Choice Privileges points." 2/choicehotels.com/choice-privile…
I did this on Feb. 14, redeeming points for a stay in August. But on Feb. 19, I decided I wasn't going to go to the hotel, so I canceled. I should have had 18 months from Feb. 14 before my points expired. 3/

29,233% in one year.
No MACD. No money flow. Nothing on the bottom of the chart at all.
He called all of it totally worthless, then named what he actually reads ↓
No MACD. No money flow. Nothing on the bottom of the chart at all.
He called all of it totally worthless, then named what he actually reads ↓


Let's take a look at the purge of what are now called "heterodox" economists from Ivies & other institutions in the 1960s as a case study. There was even an AEA committee on political discrimination that investigated tenure denials & dismissals: doi.org/10.1017/S02698… (1/n) x.com/Tyler_A_Harper…
The committee essentially sided with the institutions, while acknowledging violations of academic freedom & the committee's own ineffectiveness (by its members). Economics has seen episodes of ideological discrimination resulting in a narrowing of its own scope, but (2/n)
it's not in the direction alleged in the quoted thread. I imagine other disciplines have seen this as well. These rants that keep popping into my feed strike me as, by & large, ahistorical nonsense. I see these as an effort to cultivate another round of red scares & purges. (3/n)

Why did Prophet Sulayman (AS) ask Allah for a kingdom instead of simply waiting?
The answer will change how you understand tawakkul.
The answer will change how you understand tawakkul.
Many people misunderstand tawakkul.
They think trusting Allah means doing nothing and simply waiting.
But the Prophets taught us something different.
They made du’a and took the means.
They think trusting Allah means doing nothing and simply waiting.
But the Prophets taught us something different.
They made du’a and took the means.
Prophet Sulayman (AS) made a remarkable du’a:
“My Lord, forgive me and grant me a kingdom such as will not belong to anyone after me. Indeed, You are the Bestower.” (Qur’an 38:35)
He asked Allah directly for something عظِيم (great).
“My Lord, forgive me and grant me a kingdom such as will not belong to anyone after me. Indeed, You are the Bestower.” (Qur’an 38:35)
He asked Allah directly for something عظِيم (great).
You’re drowning.
Empty bank account. Unpaid bills. Endless job applications. Zero responses.
You’re exhausted.
But there’s one simple act that many people overlook:
Empty bank account. Unpaid bills. Endless job applications. Zero responses.
You’re exhausted.
But there’s one simple act that many people overlook:
Rizq is more than money.
It includes wealth, opportunities, good health, righteous family, beneficial knowledge, peace of heart, and every blessing Allah provides.
One of the greatest keys Allah teaches us to seek it is istighfar - a key many people overlook.
It includes wealth, opportunities, good health, righteous family, beneficial knowledge, peace of heart, and every blessing Allah provides.
One of the greatest keys Allah teaches us to seek it is istighfar - a key many people overlook.
Taking the means is essential.
But many of us overlook one of the greatest spiritual causes of barakah and provision: istighfar.
Allah says:
“Ask forgiveness of your Lord. Indeed, He is ever a Perpetual Forgiver.” (Surah Nuh 71:10)
But many of us overlook one of the greatest spiritual causes of barakah and provision: istighfar.
Allah says:
“Ask forgiveness of your Lord. Indeed, He is ever a Perpetual Forgiver.” (Surah Nuh 71:10)

🚨Alejandro Garnacho WILL leave on loan from Chelsea this summer🤯
[@TheLogeViewer]
a thread...
[@TheLogeViewer]
a thread...

Morgan Rogers has just joined Chelsea for an English player record fee of £117m.
That equates to roughly £109m of realized profit.
That equates to roughly £109m of realized profit.

However, buying Garnacho pushes down Aston Villa's amortized profits from Rogers
Whereas a loan option allows them to retain £104m
Whereas a loan option allows them to retain £104m

7 signs you’re closer to your dream than you think
Sometimes, the biggest breakthrough comes just after the hardest season.
If you’ve been making dua, working hard, and trusting Allah, don’t lose hope.
Here are 7 signs to reflect on:
If you’ve been making dua, working hard, and trusting Allah, don’t lose hope.
Here are 7 signs to reflect on:
1. Your priorities have changed.
You no longer chase every opportunity.
You’re more concerned with what pleases Allah than what impresses people.
You no longer chase every opportunity.
You’re more concerned with what pleases Allah than what impresses people.

Cortisol was completely stopped under stress with a simple & cheap supplement, according to a fascinating study.
(🧵1/7)
(🧵1/7)


This study was published in 2016, evaluating the anti-stress properties of L-THEANINE.
This is an amino acid found naturally in green tea.
People were given either a mix of:
➠ L-theanine (200 mg)
➠ L-alpha glycerylphosphorylcholine (alpha GPC; 25 mg),
➠ Phosphatidylserine (1 mg)
➠ Micronized chamomile (10 mg)
Or placebo, alongside a cognitive assessment.
While the drink did have these other ingredients, they are far below (<1-10%) their typical dosing - so their impacts were likely small or negligible.
(2/7)
This is an amino acid found naturally in green tea.
People were given either a mix of:
➠ L-theanine (200 mg)
➠ L-alpha glycerylphosphorylcholine (alpha GPC; 25 mg),
➠ Phosphatidylserine (1 mg)
➠ Micronized chamomile (10 mg)
Or placebo, alongside a cognitive assessment.
While the drink did have these other ingredients, they are far below (<1-10%) their typical dosing - so their impacts were likely small or negligible.
(2/7)

People consuming the L-Theanine drink reported markedly lower stress within the first hour.
They actually felt less stressed with the L-theanine, than they did prior, even though they were taking this assessment.
(3/7)
They actually felt less stressed with the L-theanine, than they did prior, even though they were taking this assessment.
(3/7)


ALERT: Todd Blanche submits answers to written questions from Senators
And he appears to leave the door WIDE OPEN to giving taxpayer money to convicted Jan 6 cop beaters
And he appears to leave the door WIDE OPEN to giving taxpayer money to convicted Jan 6 cop beaters

Senators asked Todd Blanche if there are ongoing conversations about giving taxpayer $$ to Jan 6 rioters
The response is ...... "less than transparent"
The response is ...... "less than transparent"

The Senate Judiciary Committee vice chair Todd Blanche about Blanche's role in arranging Trump's sweetheart immunity deal with the I.R.S.
Here was Blanche's non-response =====>
Here was Blanche's non-response =====>


Just in: In lengthy, unanimous opinion, CA3 reverses district court on both TIX and breach of contract counts in @Princeton acc'd student case. Judge Krause (Obama nominee) with the opinion.

CA3: Need to "accommodate both the vital protection of victims’ rights and the essential fairness owed to respondents. Yet in their worthy quest to erase the scourge of assault, particularly sexual assault, from their campuses, many universities have struggled to find the proper balance between these countervailing interests. Princeton University is among them."

One of the unusual facts about the Princeton case: accuser had allegedly made a nearly identical--and false--allegation against student at another university. Princeton refused to hear from him.


The R&D compute gap between, say, Anthropic and Zai is huge.
Yet the ECI/benchmark gap is roughly on the order of 6 months. I can think of 3 kinds of explanations for this:
Yet the ECI/benchmark gap is roughly on the order of 6 months. I can think of 3 kinds of explanations for this:
(1) Researchers at Zai are way more compute efficient. This could be due to talent, or to optimizing for compute efficiency more (eg, having more employees per unit of compute).
(2) There's spillover effects that make catching up much cheaper

🧵1/ You'd expect the Thirty Years' War (1618–1648) to have wiped out German printing. It's stranger than that. The cities that were sacked or besieged saw their presses collapse, but neutral cities boomed. The trade didn't die. It moved.

2/ Magdeburg, sacked in 1631, fell from about 430 German editions a decade to 40. Neutral Hamburg rose about 26-fold to nearly 2,000. And not just those two, across the sacked cities (Augsburg, Heidelberg, Frankfurt/Oder) presses collapsed. The neutral ones (Köln, Gdańsk, Zürich) soared.
3/ But the more interesting thing is, zoom out to the whole war zone and total print didn't fall at all, it grew. What collapsed was what they printed.


Aquí va, el hilo DEFINITIVO de los llantos y conspiraciones ridículas de los argentinos (con millones de reproducciones) tras la derrota en la final. Diviértanse y compartan. Se van a reír.
Empecemos con: POLICÍA, ESTÁN CELEBRANDO SER CAMPEONES FRENTE A MÍ
Empecemos con: POLICÍA, ESTÁN CELEBRANDO SER CAMPEONES FRENTE A MÍ
ME SIENTO RARA Y NADIE LO INVESTIGA
NO GANAMOS PERO LAS MALVINAS SON ARGENTINAS

To jest wątek o moich bieżących obserwacjach dotyczących AI i LLM-ów w programowaniu i o tym dokąd to wszystko zmierza. W dwóch słowach: nie wiem. W pięciu słowach: nie wiem, ale się wypowiem. A więc tak: LLM-y tu są i z nami zostaną, bo
czynią wybrane aspekty pracy programisty szybszymi i efektywniejszymi. Klepią kod jak wściekłe. Są coraz lepsze w tym, by realizować wytyczne i trzymać się zalecanej architektury - choć w projektowaniu owej architektury nadal niedomagają.
Z oczywistych powodów nie pomogą w komunikacji z innymi ludźmi i nie odgadną żadnej z rzeczy, które członkowie zespołu obgadali przy obiedzie ale jeszcze nie zapisali w firmowym Slacku czy Confluence (dystopię zakładającą noszenie wszędzie AI-owych kamer/mikrofonów wkładam

🧵 (1/7) We find ourselves in an unprecedented moment. Our state is mourning the loss of Senator Lindsey Graham while preparing for a special election unlike any we've seen before. The timeline is short. The stakes are high. There will seemingly be several candidates, passionate supporters, spirited debate, and strong opinions. That's exactly why Republican primaries exist.
(2/7) Filing for this special election opens today, and from this point forward, things are going to move quickly. The rhetoric will heat up, campaigns will take shape, and emotions will run high. We haven't even buried Senator Graham yet, and already this process is underway. That makes it all the more important that we remember what matters most.
(3/7) Let me say this: Over the last year and a half, we fought one of the most competitive Republican gubernatorial primaries in South Carolina history. We campaigned hard. We debated the issues. We made our case to the voters. And when it was over, we came back together because we understood something bigger was at stake than any one campaign. As we head into this historic U.S. Senate primary, we must not lose sight of that.

🚨 BREAKING: Claude can now build you a full AI YouTube channel like a $10,000/month creator agency.
For free.
Here are 7 prompts to go from 0 → monetized AI channel in 90 days:
For free.
Here are 7 prompts to go from 0 → monetized AI channel in 90 days:

Prompt 1 — Niche & Positioning
"Analyze the top 10 YouTube niches with high CPM, low competition, and strong evergreen demand. For each, give me: average CPM, content difficulty, monetization paths beyond AdSense, and a 3-word channel concept."
"Analyze the top 10 YouTube niches with high CPM, low competition, and strong evergreen demand. For each, give me: average CPM, content difficulty, monetization paths beyond AdSense, and a 3-word channel concept."
Prompt 2 — Channel Identity
"I'm starting a YouTube channel about [NICHE]. Create a full channel identity: channel name (5 options), tagline, target audience persona, content pillars (4), and a 'unique mechanism' that differentiates me from existing creators."
"I'm starting a YouTube channel about [NICHE]. Create a full channel identity: channel name (5 options), tagline, target audience persona, content pillars (4), and a 'unique mechanism' that differentiates me from existing creators."

Geolocation| Yellow block, reportedly placed by the Israeli military, in eastern Deir Al-Balah, Central #Gaza
31.402464, 34.371394
🗓️18 July 2026
@GeoConfirmed
Approx. 330m west of the official yellow line.
31.402464, 34.371394
🗓️18 July 2026
@GeoConfirmed
Approx. 330m west of the official yellow line.


@GeoConfirmed (1:00-1:04) Other videos show another block on the same street.
GEP satellite imagery dated 11 Jan. 2026 appears to show a block at the approx. location, but I'm not sure its the yellow block.
31.404918, 34.372229
Video: (0:58-1:05) anadoluimages.com/p/palestinian-…
x.com/AJA_Palestine/…
GEP satellite imagery dated 11 Jan. 2026 appears to show a block at the approx. location, but I'm not sure its the yellow block.
31.404918, 34.372229
Video: (0:58-1:05) anadoluimages.com/p/palestinian-…
x.com/AJA_Palestine/…

@GeoConfirmed Visual changes, likely Israeli military activity, appear visible in the area on 18 July Sentinel imagery, in comparison with the 15 July imagery.
Link: link.dataspace.copernicus.eu/v3vv
Link: link.dataspace.copernicus.eu/v3vv

Bagaimana SOP penutupan rekening yang benar @HaloBCA? Saya sangat kecewa dengan pelayanan oknum petugas di BCA KCP Graha Pena Surabaya pada Jumat, 17/07/26. Janjinya Senin rekening tertutup otomatis, tapi sampai hari ini (Selasa di 21/07/26) masih aktif. Sebuah utas. 🧵 👇
Kronologi: Jumat (17/7), saya ke BCA Graha Pena Surabaya untuk tutup rekening @HaloBCA. Di sana saya dilayani oleh petugas yang duduk di dekat tangga (memakai blazer cokelat). Di sini keanehan dan dugaan pelanggaran SOP dimulai. #BCA #HaloBCA
@HaloBCA Petugas tersebut bukannya mempermudah malah mengeluarkan berbagai dalih:
1. Bilang rekening tidak bisa ditutup karena ada transaksi di hari yang sama (tidak ada aturan ini di web/brosur BCA).
2. Meminta saya tutup di cabang asal karena saya tidak pegang kartu ATM
@ojkindonesia
1. Bilang rekening tidak bisa ditutup karena ada transaksi di hari yang sama (tidak ada aturan ini di web/brosur BCA).
2. Meminta saya tutup di cabang asal karena saya tidak pegang kartu ATM
@ojkindonesia

1. ICE is lying about body cams and I have the documents that prove it.
On July 14, Tom Homan, who oversees ICE's immigration crackdown at the White House, said that ICE purchased body cams as soon as Democrats approved funding for DHS in April.
That is a lie.
On July 14, Tom Homan, who oversees ICE's immigration crackdown at the White House, said that ICE purchased body cams as soon as Democrats approved funding for DHS in April.
That is a lie.

2. Homan argued ICE officers weren't using body cams when they killed two people in six days is that Democrats held up DHS funding
But did ICE not purchase body cams in April.
ICE purchase them LAST FRIDAY & YESTERDAY.
popular.info/p/ice-is-lying…
But did ICE not purchase body cams in April.
ICE purchase them LAST FRIDAY & YESTERDAY.
popular.info/p/ice-is-lying…
3. Documents unearthed by Popular Information reveal ICE purchased $30 million worth of body cams on July 17 and July 20 (yesterday). The orders were place AFTER ICE came scrutiny for killing two people in six days — with no body cams recording either incident.


His fighter had been struck by twenty-one cannon shells. He was burned, wounded and almost blinded by hydraulic fluid. His canopy was jammed, leaving him unable to escape.
Then another German fighter found him over the Channel and attacked again and again, until its guns finally fell silent.
The American flew home anyway.
This is the story of Robert Johnson..🧵1/7
Then another German fighter found him over the Channel and attacked again and again, until its guns finally fell silent.
The American flew home anyway.
This is the story of Robert Johnson..🧵1/7

🧵 2/7
Nothing about Robert Samuel Johnson suggested he would become one of the deadliest fighter pilots America ever produced.
He arrived in England in January 1943 with the 56th Fighter Group, sailing over on the Queen Elizabeth, crammed into a two-man cabin shared with thirteen other officers.
He had originally been classified as a bomber pilot, and had never completed the gunnery qualification required of a fighter pilot. He had never fired the Thunderbolt's guns at all. So he was packed off to a gunnery course in Wales to put that right.
Bad weather grounded the training flights, and he came back to his squadron still officially unqualified.
In his memoir, Thunderbolt!, Johnson recalled that he was regarded as one of the pilots in the outfit most likely to get himself shot down.
Nothing about Robert Samuel Johnson suggested he would become one of the deadliest fighter pilots America ever produced.
He arrived in England in January 1943 with the 56th Fighter Group, sailing over on the Queen Elizabeth, crammed into a two-man cabin shared with thirteen other officers.
He had originally been classified as a bomber pilot, and had never completed the gunnery qualification required of a fighter pilot. He had never fired the Thunderbolt's guns at all. So he was packed off to a gunnery course in Wales to put that right.
Bad weather grounded the training flights, and he came back to his squadron still officially unqualified.
In his memoir, Thunderbolt!, Johnson recalled that he was regarded as one of the pilots in the outfit most likely to get himself shot down.
🧵 3/7
The unit he had landed in was extraordinary.
The 56th Fighter Group was commanded by Colonel Hubert Zemke, and the Germans came to know it as Zemke's Wolfpack. It flew the Republic P-47 Thunderbolt, a seven-ton monster of an aircraft that veteran RAF pilots warned the Americans would be no match for the nimble Focke-Wulf 190.
They were wrong.
The Wolfpack would finish the war credited with more aerial victories than any other fighter group in the Eighth Air Force.
Johnson scored his first kill on June 13 1943, and he did it by ignoring orders. He was supposed to be flying top cover. Instead, as he later put it himself, he broke all the rules and regulations to do it, flying straight past his own colonel to shoot down the leader of an eight-plane formation of Fw 190s.
Thirteen days later, it very nearly killed him.
The unit he had landed in was extraordinary.
The 56th Fighter Group was commanded by Colonel Hubert Zemke, and the Germans came to know it as Zemke's Wolfpack. It flew the Republic P-47 Thunderbolt, a seven-ton monster of an aircraft that veteran RAF pilots warned the Americans would be no match for the nimble Focke-Wulf 190.
They were wrong.
The Wolfpack would finish the war credited with more aerial victories than any other fighter group in the Eighth Air Force.
Johnson scored his first kill on June 13 1943, and he did it by ignoring orders. He was supposed to be flying top cover. Instead, as he later put it himself, he broke all the rules and regulations to do it, flying straight past his own colonel to shoot down the leader of an eight-plane formation of Fw 190s.
Thirteen days later, it very nearly killed him.

A med student asked me today:
"If every breath contains thousands of microbes, why aren't we constantly sick?"
It's one of the most fascinating questions in microbiology. Let me explain.🧵
"If every breath contains thousands of microbes, why aren't we constantly sick?"
It's one of the most fascinating questions in microbiology. Let me explain.🧵
First, the numbers are real.
You inhale roughly 10,000–100,000 microbial cells per breath–bacteria, fungi, viruses. That's ~10⁶–10⁸ per day. If every one caused disease, we'd be dead in hours.
You inhale roughly 10,000–100,000 microbial cells per breath–bacteria, fungi, viruses. That's ~10⁶–10⁸ per day. If every one caused disease, we'd be dead in hours.
So why aren't we?
Because infection ≠ exposure. Disease requires three things to align:
· A pathogen (not just a microbe)
· A virulent dose (enough to overwhelm defenses)
· A vulnerable site (with broken barriers or suppressed immunity)
Most airborne microbes fail at least one of these.
Because infection ≠ exposure. Disease requires three things to align:
· A pathogen (not just a microbe)
· A virulent dose (enough to overwhelm defenses)
· A vulnerable site (with broken barriers or suppressed immunity)
Most airborne microbes fail at least one of these.

1-Els 10 principis més importants de l’Escola Austríaca d’Economia, Menger, Böhm-Bawerk, Mises, Hayek, Kirzner, són aquests:
L’acció humana és el punt de partida
estudia persones que prenen decisions amb objectius concrets, no agregats impersonals com la demanda o el PIB.
L’acció humana és el punt de partida
estudia persones que prenen decisions amb objectius concrets, no agregats impersonals com la demanda o el PIB.

2 -El valor és subjectiu
Els béns no tenen un valor intrínsec.
Valen allò que cada persona està disposada a pagar segons les seves preferències i necessitats.
Els béns no tenen un valor intrínsec.
Valen allò que cada persona està disposada a pagar segons les seves preferències i necessitats.

3- Els preus transmeten informació.
El sistema de preus coordina milions de decisions individuals sense necessitat d’un planificador central.
Quan un preu puja o baixa, envia informació sobre escassetat o abundància.
El sistema de preus coordina milions de decisions individuals sense necessitat d’un planificador central.
Quan un preu puja o baixa, envia informació sobre escassetat o abundància.


A family paid the same car insurance company for 11 years.
Never filed a claim. Never called except to add a car. $19,800 paid over a decade for two vehicles, on autopilot.
Their neighbor — a former insurance adjuster who spent 6 years pricing policies before switching careers — asked to see their declarations page over coffee.
He read it for 90 seconds and put his mug down.
"You're paying for a coverage limit that's illegal in some states to even sell, it's so far below what a real accident would cost you. You've had zero tickets and zero claims in eleven years and you're still on the 'new customer' rate, because loyalty discounts here don't exist — they only give the good rate to people who threaten to leave. Your teenager is on this policy at the same rate as an adult with a clean record, when good-student and defensive-driving discounts would cut that in half. You're paying for rental car coverage you've never used and roadside assistance you already have for free through your credit card. And nobody has run your ZIP code against a competitor in over a decade."
He didn't tell them to switch. He told them to call and say four words.
The dad said "eleven years, same company, and I've never once questioned the bill."
The neighbor said "That's exactly how they want it. Insurance companies build their whole profit model around people who never ask twice."
Here's everything he found, and the exact script he had them use 🧵
Never filed a claim. Never called except to add a car. $19,800 paid over a decade for two vehicles, on autopilot.
Their neighbor — a former insurance adjuster who spent 6 years pricing policies before switching careers — asked to see their declarations page over coffee.
He read it for 90 seconds and put his mug down.
"You're paying for a coverage limit that's illegal in some states to even sell, it's so far below what a real accident would cost you. You've had zero tickets and zero claims in eleven years and you're still on the 'new customer' rate, because loyalty discounts here don't exist — they only give the good rate to people who threaten to leave. Your teenager is on this policy at the same rate as an adult with a clean record, when good-student and defensive-driving discounts would cut that in half. You're paying for rental car coverage you've never used and roadside assistance you already have for free through your credit card. And nobody has run your ZIP code against a competitor in over a decade."
He didn't tell them to switch. He told them to call and say four words.
The dad said "eleven years, same company, and I've never once questioned the bill."
The neighbor said "That's exactly how they want it. Insurance companies build their whole profit model around people who never ask twice."
Here's everything he found, and the exact script he had them use 🧵
Check if your liability limits would actually protect you
A lot of policies default to state-minimum liability limits, which in many states cover as little as $25,000 per person for injuries — nowhere close to what a serious accident actually costs.
He said: "Pull up your declarations page and look at your liability numbers. If a bad accident happened tomorrow and someone sued you for the difference between your limit and the real cost, would you be covered, or would that come out of your house and your savings?"
Raising this limit is often only a few dollars more a month. Being underinsured is the expensive part.
A lot of policies default to state-minimum liability limits, which in many states cover as little as $25,000 per person for injuries — nowhere close to what a serious accident actually costs.
He said: "Pull up your declarations page and look at your liability numbers. If a bad accident happened tomorrow and someone sued you for the difference between your limit and the real cost, would you be covered, or would that come out of your house and your savings?"
Raising this limit is often only a few dollars more a month. Being underinsured is the expensive part.
Call and say the four words that get you a better rate
Most insurers don't automatically apply their best available rate to existing customers — new-customer promotional pricing and loyalty pricing are often two completely different numbers.
He said: "Call and say: 'I'm considering other quotes.' That single sentence routes you to a retention specialist who has more room to adjust your rate than the standard rep answering the main line. It costs you a five-minute phone call."
Most insurers don't automatically apply their best available rate to existing customers — new-customer promotional pricing and loyalty pricing are often two completely different numbers.
He said: "Call and say: 'I'm considering other quotes.' That single sentence routes you to a retention specialist who has more room to adjust your rate than the standard rep answering the main line. It costs you a five-minute phone call."

i think a lot about that guy in the early 1900s who went to bosnia to the last illiterate communities in europe and found out they were still reciting homer epic-length poems to each other from memory.
but when they became literate they lost the ability to remember the poems
but when they became literate they lost the ability to remember the poems
milman party i think was his name
one thing i read that stuck with me was how he recorded their poems on wax cylinders and the bosnian storytellers at first got really annoyed at how frequently they had to stop to let him change the cylinder. 1/

🚨 SHOCKING 🚨
A recent study took healthy women with 0 history of breast cancer.
Then, they removed ONE single thing from their routine.
After only 28 days?
A cancer-related gene in their normal breast tissue was GONE.
Here’s what they removed from the routine: 🧵
A recent study took healthy women with 0 history of breast cancer.
Then, they removed ONE single thing from their routine.
After only 28 days?
A cancer-related gene in their normal breast tissue was GONE.
Here’s what they removed from the routine: 🧵
Here’s how the study was conducted:
The researchers collected fine needle aspirates (pre and post) from healthy volunteers.
Those were women with no cancer diagnosis who were regularly using everyday products, just like most of us.
The researchers collected fine needle aspirates (pre and post) from healthy volunteers.
Those were women with no cancer diagnosis who were regularly using everyday products, just like most of us.
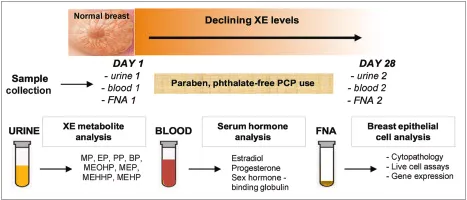
Same diet. Same exercise. Same lifestyle. Same EVERYTHING else.
Only ONE thing changed.
And after 28 days, cancer-related genes in their breast tissue reverted to normal.
Genes that promote cancer growth were literally switched OFF.
Only ONE thing changed.
And after 28 days, cancer-related genes in their breast tissue reverted to normal.
Genes that promote cancer growth were literally switched OFF.

karena banyak yg nanya "kak gimana sih caranya war tiket di sevel?"
berikut aku kasih tau caranya beli tiket di sevel
(biasanya utk event SF atau konser domundi) bisa dibookmark 😚
1. bangun jam 6 pagi
kalau hari ini misal war di sevel jam 12, itu kamu dari pagi harus uda keliling cari sevel.
kenapa harus pagi? biar dapat antrian pertama guys.
soalnya gini aku jelasin. biarpun beli di sevel, itu ga kita dateng terus "kak aku mau beli tiket" terus bisa langsung beli terus dapat, gak guys, itu ada warnya jugaaaaaa. karena sevel di thai itu banyak dan semua juga mau beli. jadi dalam 1 menit aja uda habis loh itu.
berikut aku kasih tau caranya beli tiket di sevel
(biasanya utk event SF atau konser domundi) bisa dibookmark 😚
1. bangun jam 6 pagi
kalau hari ini misal war di sevel jam 12, itu kamu dari pagi harus uda keliling cari sevel.
kenapa harus pagi? biar dapat antrian pertama guys.
soalnya gini aku jelasin. biarpun beli di sevel, itu ga kita dateng terus "kak aku mau beli tiket" terus bisa langsung beli terus dapat, gak guys, itu ada warnya jugaaaaaa. karena sevel di thai itu banyak dan semua juga mau beli. jadi dalam 1 menit aja uda habis loh itu.

2. datang dan ambil antrian
pagi km ke sevel terus tunjukin fotonya kalau nanti kamu mau beli tiket ini, terus tanya, kamu antrian berapa?
klo 1 km book kakaknya.
klo gak nomer 1 cari sevel lainnnn.
nah itu tanyain bisa book gak, klo bisa km book dan bisa back lagi sekitar 30 menit sebelum war, TAPI ada bbrp sevel yg ga bisa, nah itu kalian harus nungguin disitu dari pagi ya sampe siang tergantung warnya jam brp.
3. pastiin sevel yg kamu datangin itu pc nya baru
jadi itu ga semua sevel pc nya baru. banyak yg lama.
yg baru gimana sih?
itu biasanya layarnya dia udah model gepeng dan warnanya putihhhh. klo lama itu uda menguning gtu, nah itu berpengaruh untuk kecepatan pc nya. soalnya suka ngelagggg klo yg lama
pagi km ke sevel terus tunjukin fotonya kalau nanti kamu mau beli tiket ini, terus tanya, kamu antrian berapa?
klo 1 km book kakaknya.
klo gak nomer 1 cari sevel lainnnn.
nah itu tanyain bisa book gak, klo bisa km book dan bisa back lagi sekitar 30 menit sebelum war, TAPI ada bbrp sevel yg ga bisa, nah itu kalian harus nungguin disitu dari pagi ya sampe siang tergantung warnya jam brp.
3. pastiin sevel yg kamu datangin itu pc nya baru
jadi itu ga semua sevel pc nya baru. banyak yg lama.
yg baru gimana sih?
itu biasanya layarnya dia udah model gepeng dan warnanya putihhhh. klo lama itu uda menguning gtu, nah itu berpengaruh untuk kecepatan pc nya. soalnya suka ngelagggg klo yg lama
4. tulis nomer paspor kamu di kertas
jangan lupa tulis dikertas yg jelas. terus taruh aja depan kakaknya sebelum war itu
5. siapkan cash
biasanya kalau pembayaran tiket gini, sevelnya suka ga nerima card. jadi lebih aman sediain cash.
6. H-1 war simpan barcode yang ada di akun allticket or SF
barcodenya kaya dipic ⬇️
gunanya itu nanti pas jam .00
misal warnya jam 12.00 itu kakaknya bisa scan, jadi bisa langsung kebuka itu pagenya. jadi dia ga perlu cari2 di pc nya guys biar lebih cepat
jangan lupa tulis dikertas yg jelas. terus taruh aja depan kakaknya sebelum war itu
5. siapkan cash
biasanya kalau pembayaran tiket gini, sevelnya suka ga nerima card. jadi lebih aman sediain cash.
6. H-1 war simpan barcode yang ada di akun allticket or SF
barcodenya kaya dipic ⬇️
gunanya itu nanti pas jam .00
misal warnya jam 12.00 itu kakaknya bisa scan, jadi bisa langsung kebuka itu pagenya. jadi dia ga perlu cari2 di pc nya guys biar lebih cepat




Harvard lleva 85 años siguiendo la vida de las mismas personas. Es el estudio más largo de la historia sobre la felicidad.
Su conclusión descolocó a todos: no es el dinero, ni la fama, ni el éxito.
7 hallazgos que deberías conocer antes de los 40:
1. La soledad te quita años.
Su conclusión descolocó a todos: no es el dinero, ni la fama, ni el éxito.
7 hallazgos que deberías conocer antes de los 40:
1. La soledad te quita años.
El estudio lo dice sin rodeos: la soledad crónica es tan tóxica como fumar o el alcoholismo.
Los más aislados eran menos felices, su salud caía antes, su cerebro declinaba antes… y vivían menos.
No es poesía. Es biología.
Los más aislados eran menos felices, su salud caía antes, su cerebro declinaba antes… y vivían menos.
No es poesía. Es biología.
2. Las relaciones lo predicen todo.
Empezaron en 1938 con 724 hombres. Los siguieron toda la vida: análisis, cerebros, carreras, matrimonios.
El mejor predictor de llegar sano y feliz a los 80 no fue el colesterol ni el dinero.
Fue lo satisfechos que estaban con sus relaciones a los 50.
Empezaron en 1938 con 724 hombres. Los siguieron toda la vida: análisis, cerebros, carreras, matrimonios.
El mejor predictor de llegar sano y feliz a los 80 no fue el colesterol ni el dinero.
Fue lo satisfechos que estaban con sus relaciones a los 50.

El acetato de GLATIRAMER (Copaxone y genéricos) es uno de los tratamientos más usados contra la esclerosis múltiple.
Como tantos otros fue descubierto por casualidad en los años 60 en Israel.
Como tantos otros fue descubierto por casualidad en los años 60 en Israel.

A finales de la década de 1960, científicos del Instituto Weizmann (Israel) investigaban polímeros sintéticos de aminoácidos para crear un modelo animal de inflamación cerebral (encefalomielitis autoinmune experimental).
En vez de provocar la enfermedad… la protegían.
En vez de provocar la enfermedad… la protegían.
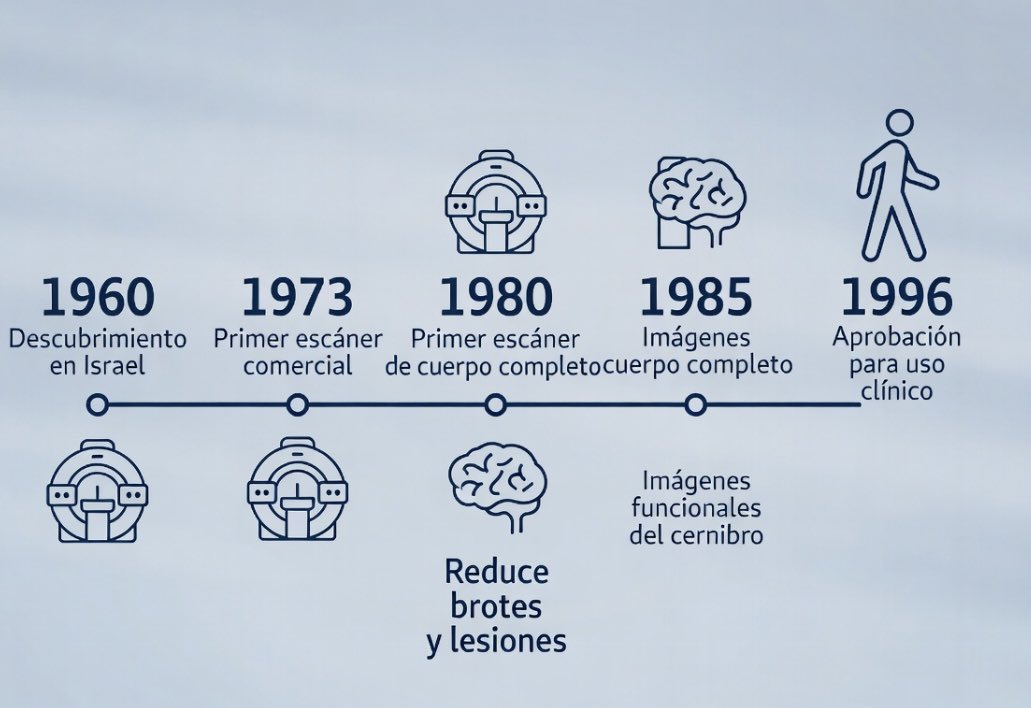
La esclerosis múltiple (EM) es una enfermedad autoinmune que ataca la vaina de mielina, la capa protectora de las neuronas en cerebro y médula espinal.
Se le llama “la enfermedad de las mil caras” porque sus síntomas pueden aparecer en cualquier parte del cuerpo.
Se le llama “la enfermedad de las mil caras” porque sus síntomas pueden aparecer en cualquier parte del cuerpo.


Thread no: 7 (tel)
Voluptuous Cheating #MILF Whore 😈
Curvy neglected housewife Mrunal Thakur sultry face, plump lips, bedroom eyes, massive heaving tits, thick juicy ass
Bhartha bulli modda tho satisfy kaka
Couch meeda legs spread fingers sloppy ga puku lo petti kaamam tho
Voluptuous Cheating #MILF Whore 😈
Curvy neglected housewife Mrunal Thakur sultry face, plump lips, bedroom eyes, massive heaving tits, thick juicy ass
Bhartha bulli modda tho satisfy kaka
Couch meeda legs spread fingers sloppy ga puku lo petti kaamam tho


M:"Fuck… pedda stranger modda kavali ra, naa married puku ni chadadengadam kosam"
Delivery guys knocks. Door open lo vundani lopaliki vachi chuste legs wide, three fingers knuckle-deep karuthunna wet puku lo, juices couch meeda drip avuthunnayi
🔥 #MILFWhore #DeliveryBreed
Delivery guys knocks. Door open lo vundani lopaliki vachi chuste legs wide, three fingers knuckle-deep karuthunna wet puku lo, juices couch meeda drip avuthunnayi
🔥 #MILFWhore #DeliveryBreed

D:"Eve ni married puku ni kaamam tho abuse chestunnava? Ni mogudu di panikirani modda?"
Mrunal gasp, slick fingers bayata teesi
"Evadranuvvu bayatikipora! Get out you perv!"
Kaani vaadi bulge meeda eyes lock ayinayi 😈
Vaadu wrist pattukoni dripping fingers clean ga chikadu "Ah!"
Mrunal gasp, slick fingers bayata teesi
"Evadranuvvu bayatikipora! Get out you perv!"
Kaani vaadi bulge meeda eyes lock ayinayi 😈
Vaadu wrist pattukoni dripping fingers clean ga chikadu "Ah!"



Das muss man sich mal geben. Da sagt ein Geschäftsführer indirekt zur Prime Time, dass @mueller_sepp die Bevölkerung belügt. Die Verunsicherung hat den Markt bei WP einbrechen lassen. Der Beitrag ist Gold wert gegen jede Argumentation von der Union. Fürs Protokoll: der GF im…
Video ist von WOLF. Zu der Firma habe ich schon mal was geschrieben, Tweet anbei. @Markus_Soeder und die ganze Union haben BEWUSST (!!!) für ihren Populismus in Kauf genommen dass eine Firma VOR ORT den Bach runtergehen könnte. Wenn das Produkt von Wolf nicht so gut wäre!
@Markus_Soeder An der Stelle sei noch mal an die Posts von der @CSU Fraktion erinnert!


Lilith im Glück: "Ihre erste Einstweilige Verfügung nach dem Presserecht". 1300 Seiten.
Was hier so lustig wirkt, als würde ich stolz meine Doktorarbeit in die Kamera halten, ist leider bitterer ernst.
Was hier so lustig wirkt, als würde ich stolz meine Doktorarbeit in die Kamera halten, ist leider bitterer ernst.

Der Staat Malta bzw. die Maltesische Glücksspielaufsicht gehen momentan per SLAPP-also mit Gerichtsverfahren die primär der Einschüchterung dienen-gegen mich vor.
Investieren hunderttausende für Großkanzleien wie Bird&Bird oder Privatdetektive, die mir wochenlang nachschnüffeln.
Investieren hunderttausende für Großkanzleien wie Bird&Bird oder Privatdetektive, die mir wochenlang nachschnüffeln.
Erst dachte ich, so eine völlig ungerechtfertigte einstweilige Verfügung würde das Landgericht Berlin niemals erlassen - ganz besonders nicht, weil die Frist für den einstweiligen Rechtsschutz schon verstrichen war. Und weil sie aus meiner Sicht eben rechtsmissbräuchlich ist.

My framing of the $SOXX semiconductor investment - with no view on short term bounce trades - today:
This is ~2.25 beta to the general market. The general market itself seems riskier than average today. So this is a very risky bet right now.
In order for this investment to be worth the risk, someone should truly think the forward return is 20%+/year over the next 5 years. So you make +150% in the good outcome. In the bad outcome, you lose say 60%. On coinflip odds, that seems pretty good, not great.
This is ~2.25 beta to the general market. The general market itself seems riskier than average today. So this is a very risky bet right now.
In order for this investment to be worth the risk, someone should truly think the forward return is 20%+/year over the next 5 years. So you make +150% in the good outcome. In the bad outcome, you lose say 60%. On coinflip odds, that seems pretty good, not great.
In 5 years your $100 turns into either $250 or $50. Expected return: double your money.
If $TSM doubles earnings in 5 years, and still trades for the same ~30x multiple, you double your money.
is $TSM going to double earnings from here? Based on current growth, that seems likely. Maybe it could even triple earnigns? But man that is coming off an awfully strong base, right? There's not really room for companies like $GOOG to increase capex even 50% from here, right?
is $TSM going to double earnings from here? Based on current growth, that seems likely. Maybe it could even triple earnigns? But man that is coming off an awfully strong base, right? There's not really room for companies like $GOOG to increase capex even 50% from here, right?

@SammyTherese @BDorr @BasedSamParker @RealCandaceO @ProjectConstitu These close up videos showing behind the tables were all manipulated with AI. He (or stunt double) was guided back by Dan, helped by microphone cable, & onto a crash pit.
@SammyTherese @BDorr @BasedSamParker @RealCandaceO @ProjectConstitu
@SammyTherese @BDorr @BasedSamParker @RealCandaceO @ProjectConstitu

Yevhen Khmara appointed acting Defence Minister of Ukraine. Here is what we know about him.
Khmara, 40, led the liberation of Snake Island, helped plan Operation “Spider Web,” and commanded one of the top 3 most effective units in the army — Special Operations Center “A”.
1/
Khmara, 40, led the liberation of Snake Island, helped plan Operation “Spider Web,” and commanded one of the top 3 most effective units in the army — Special Operations Center “A”.
1/

At the start of the full-scale invasion, Khmara served in the liberation of Kyiv region and carried out combat missions in Donetsk.
On January 5, 2026, he was appointed acting head of the Ukrainian Security Service, replacing Vasyl Maliuk.
2/
On January 5, 2026, he was appointed acting head of the Ukrainian Security Service, replacing Vasyl Maliuk.
2/
Khmara is a full recipient of the Order of Bohdan Khmelnytsky, and has also been awarded the Order ‘For Courage’, 3rd class, and the President of Ukraine’s ‘Cross of Military Merit’.
3X
3X

#SPECIALREPORT
𝐓𝐡𝐞 𝐒𝐡𝐚𝐝𝐨𝐰𝐲 𝐎𝐩𝐞𝐫𝐚𝐭𝐨𝐫𝐬: 𝐈𝐧𝐬𝐢𝐝𝐞 𝐭𝐡𝐞 𝐄𝐥𝐢𝐭𝐞 𝐂𝐚𝐦𝐩 𝐨𝐟 𝐆𝐞𝐧𝐞𝐫𝐚𝐥𝐬 𝐏𝐨𝐰𝐞𝐫𝐢𝐧𝐠 𝐑𝐞𝐬𝐢𝐬𝐭𝐚𝐧𝐜𝐞 𝐀𝐠𝐚𝐢𝐧𝐬𝐭 𝐌𝐧𝐚𝐧𝐠𝐚𝐠𝐰𝐚’𝐬 𝐄𝐱𝐭𝐞𝐧𝐝𝐞𝐝 𝐓𝐞𝐧𝐮𝐫𝐞
🔴Nine former army commanders lead mobilisation against Mnangagwa
🔴Become the new centre of gravity for centrifugal opposition forces
A GROUP of former army commanders led by retired air vice-marshal Henry Muchena linked to Vice-President Constantino Chiwenga's faction has now crystalised into a nucleus of audacious internal resistance to President Emmerson Mnangagwa’s extended rule in the aftermath of Constitution Amendment Act No.3 amid calls for mass action on July 31 and pushback by civil society and opposition groups, insiders say.
Security sources say the group is now the driver of centrifugal forces drifting away from the centre of Zanu PF power politics to coalesce with civil society and opposition groups to fight Mnangagwa in the aftermath of far-reaching political, electoral and governance changes.
At the forefront of this resistance clique is Muchena, who formally emerged as the public face for the coalition of former military commanders, war veterans, and senior civil servants.
The group made official written submissions to parliament in March, warning that altering key constitutional provisions without a public referendum subverts the core ideals of the liberation struggle — one man one vote or universal adult suffrage right and direct power to elect President belonging to the masses.
The pushback by liberation-era veterans represents a significant fracture in the fractious civil-military alliance that has historically defined Zimbabwe's political landscape.
Muchena and his shadow coalition of fellow retired commanders claim that the new constitutional amendments heavily centralise executive authority and disenfranchise voters.
By bypassing a public referendum and transferring the power to elect a head of state to parliament, they say, the changes create a situation where a sitting president is signicantly insulated from direct popular accountability.
The ex-commanders bloc itself is a real, coordinated group whose membership has been closely held, a deliberate operational-security choice that keeps participants out of the public record while leaving the convenor as the single named face.
After some checks and verification, The NewsHawks has confirmed that the group features a number of retired generals whose names have been bandied about in the media, but not confirmed until now.
An investigation report on the issue done by party and state actors driving the recent constitutional amendments, titled A Report on the Figures Named in Zimbabwe’s 2026 Constitutional Amendment (No.3) Resistance, seen by NewsHawks, names nine retired commanders as the core team battling Mnangagwa's leadership.
Besides Muchena, the retired generals cohort include Lieutenant-General Martin Chedondo, Major-General Mike Nicholas Sango, Major-General Paul Chima, Chris Mupande, Etherton Shungu, Livingstone Chineka, Richard Ncube and war veteran Frederick Mutanda.
Muchena was deputy Air Force of Zimbabwe commander and former principal director in the Zanu PF commissariat department.
Chedondo was chief-of-staff in the Zimbabwe National Army and former ambassador to China, while Sango was headed of military intelligence and ex-ambassador to Russia.
Chima served as the commander of the Mechanised Brigade at Inkomo Barracks, whereas Mupande was the Director-General of Policy, Public Relations, and International Affairs at the Ministry of Defence.
Shungu was Commander of the Artillery Brigade.
Also a former army commander, Chineka was Zanu PF MP for Zaka East after winning a 2007 by-election.
Ncube was a top Zipra commander as chief of operations during the liberation struggle, while Mutanda was the late Zapu leader Joshua Nkomo's close aide.
The generals want Mnangagwa to go over state power dynamics and succession.
𝐓𝐡𝐞 𝐒𝐡𝐚𝐝𝐨𝐰𝐲 𝐎𝐩𝐞𝐫𝐚𝐭𝐨𝐫𝐬: 𝐈𝐧𝐬𝐢𝐝𝐞 𝐭𝐡𝐞 𝐄𝐥𝐢𝐭𝐞 𝐂𝐚𝐦𝐩 𝐨𝐟 𝐆𝐞𝐧𝐞𝐫𝐚𝐥𝐬 𝐏𝐨𝐰𝐞𝐫𝐢𝐧𝐠 𝐑𝐞𝐬𝐢𝐬𝐭𝐚𝐧𝐜𝐞 𝐀𝐠𝐚𝐢𝐧𝐬𝐭 𝐌𝐧𝐚𝐧𝐠𝐚𝐠𝐰𝐚’𝐬 𝐄𝐱𝐭𝐞𝐧𝐝𝐞𝐝 𝐓𝐞𝐧𝐮𝐫𝐞
🔴Nine former army commanders lead mobilisation against Mnangagwa
🔴Become the new centre of gravity for centrifugal opposition forces
A GROUP of former army commanders led by retired air vice-marshal Henry Muchena linked to Vice-President Constantino Chiwenga's faction has now crystalised into a nucleus of audacious internal resistance to President Emmerson Mnangagwa’s extended rule in the aftermath of Constitution Amendment Act No.3 amid calls for mass action on July 31 and pushback by civil society and opposition groups, insiders say.
Security sources say the group is now the driver of centrifugal forces drifting away from the centre of Zanu PF power politics to coalesce with civil society and opposition groups to fight Mnangagwa in the aftermath of far-reaching political, electoral and governance changes.
At the forefront of this resistance clique is Muchena, who formally emerged as the public face for the coalition of former military commanders, war veterans, and senior civil servants.
The group made official written submissions to parliament in March, warning that altering key constitutional provisions without a public referendum subverts the core ideals of the liberation struggle — one man one vote or universal adult suffrage right and direct power to elect President belonging to the masses.
The pushback by liberation-era veterans represents a significant fracture in the fractious civil-military alliance that has historically defined Zimbabwe's political landscape.
Muchena and his shadow coalition of fellow retired commanders claim that the new constitutional amendments heavily centralise executive authority and disenfranchise voters.
By bypassing a public referendum and transferring the power to elect a head of state to parliament, they say, the changes create a situation where a sitting president is signicantly insulated from direct popular accountability.
The ex-commanders bloc itself is a real, coordinated group whose membership has been closely held, a deliberate operational-security choice that keeps participants out of the public record while leaving the convenor as the single named face.
After some checks and verification, The NewsHawks has confirmed that the group features a number of retired generals whose names have been bandied about in the media, but not confirmed until now.
An investigation report on the issue done by party and state actors driving the recent constitutional amendments, titled A Report on the Figures Named in Zimbabwe’s 2026 Constitutional Amendment (No.3) Resistance, seen by NewsHawks, names nine retired commanders as the core team battling Mnangagwa's leadership.
Besides Muchena, the retired generals cohort include Lieutenant-General Martin Chedondo, Major-General Mike Nicholas Sango, Major-General Paul Chima, Chris Mupande, Etherton Shungu, Livingstone Chineka, Richard Ncube and war veteran Frederick Mutanda.
Muchena was deputy Air Force of Zimbabwe commander and former principal director in the Zanu PF commissariat department.
Chedondo was chief-of-staff in the Zimbabwe National Army and former ambassador to China, while Sango was headed of military intelligence and ex-ambassador to Russia.
Chima served as the commander of the Mechanised Brigade at Inkomo Barracks, whereas Mupande was the Director-General of Policy, Public Relations, and International Affairs at the Ministry of Defence.
Shungu was Commander of the Artillery Brigade.
Also a former army commander, Chineka was Zanu PF MP for Zaka East after winning a 2007 by-election.
Ncube was a top Zipra commander as chief of operations during the liberation struggle, while Mutanda was the late Zapu leader Joshua Nkomo's close aide.
The generals want Mnangagwa to go over state power dynamics and succession.

The detailed report on this securocratic group of generals said:
"The nine figures in this report are a real, coordinated group.
All nine are members of the bloc that opposes Constitutional Amendment No.3, and all were present at the two consecutive meetings with the President in May.
This is established from first-hand sources with direct knowledge of the meeting; public reporting has not disclosed the membership, naming only convener Air Vice-Marshal (Rtd) Henry Muchena, and the group’s anonymity is a deliberate operational choice rather than evidence that it does not exist.
The figures named in this report are real and traceable officers with documented service records.
Part of the wider resistance narrative, however, is carried by self-titled 'retired general' voices whose claimed rank and service have no verifiable record predating 2026.
Such unverifiable personas should not be counted as confirmed officers, and their amplification inflates the apparent seniority and breadth of the bloc."
Further, the report, which sheds light and throws insight on the issue, adds:
"The bloc sits within the wider Chiwenga succession matrix and overlaps in aim with the faction of the war-veterans’ association, which is the most visible organised channel of internal opposition. The coordinated action of this group is therefore one expression of a broader split in the liberation-war establishment rather than an isolated initiative.
The bloc’s most explosive public claim, that US$31 million was raised to buy MP votes for CAB3 (now CA3), is its own allegation against government, not a charge against the bloc.
It is unsubstantiated: it appears only in the bloc’s 2 June 2026 statement, with no evidence produced and the accused silent, and is best read as bloc propaganda rather than established fact.
Defining the coalition as 'retired generals, senior civil servants and war veterans' is most likely a deliberate legal and moral posture: it shields participants from subversion or mutiny charges that would attach to serving soldiers and lays claim to liberation-war legitimacy. The deliberate anonymity of the membership is consistent with this shielding logic."
Profiling the generals, the document says "the resistance narrative travels through a measurable information ecosystem, and assessing it is as important as profiling the individuals".
It adds:
"Two distinct phenomena should not be conflated. The bloc is a real, coordinated group whose membership is closely held, a deliberate operational-security choice that keeps participants out of the public record while leaving the convener as the single named face. Separately, the broader anti-Mnangagwa conversation and mobilisation also features self-titled 'retired Lieutenant-General-figures' whose claimed rank and service have no record predating 2026 and cannot be verified; whether or not real individuals sit behind such accounts, that borrowed authority can inflate the apparent seniority of the opposition and should not be treated as part of the verified membership."
Sources told NewsHawks that the camp of generals, some of them remnants of the late former army commander retired General Solomon Mujuru's Zanu PF faction but now loyal to Chiwenga, is currently behind the scenes mobilising around the contentious constitutional changes which they strongly oppose and want urgent further measures against.
Some of them like Muchena were loyal to Mujuru, but now support Chiwenga in the intensifying Zanu PF succession power struggle which sits at the heart of the infighting that has drawn civil society and opposition groups into its volatile vortex.
The generals behind Chiwenga are drifting away from the centre of state power to coalesce with the opposition to form a united front against Mnangagwa.
They want to join forces with a new civil society and opposition organisation, the People's Coalition - Sungano yeVanhu/Ubumbano loMphakathi - formed recently under the convenorship of Reverend Dr. Kupa Mtata.
"The nine figures in this report are a real, coordinated group.
All nine are members of the bloc that opposes Constitutional Amendment No.3, and all were present at the two consecutive meetings with the President in May.
This is established from first-hand sources with direct knowledge of the meeting; public reporting has not disclosed the membership, naming only convener Air Vice-Marshal (Rtd) Henry Muchena, and the group’s anonymity is a deliberate operational choice rather than evidence that it does not exist.
The figures named in this report are real and traceable officers with documented service records.
Part of the wider resistance narrative, however, is carried by self-titled 'retired general' voices whose claimed rank and service have no verifiable record predating 2026.
Such unverifiable personas should not be counted as confirmed officers, and their amplification inflates the apparent seniority and breadth of the bloc."
Further, the report, which sheds light and throws insight on the issue, adds:
"The bloc sits within the wider Chiwenga succession matrix and overlaps in aim with the faction of the war-veterans’ association, which is the most visible organised channel of internal opposition. The coordinated action of this group is therefore one expression of a broader split in the liberation-war establishment rather than an isolated initiative.
The bloc’s most explosive public claim, that US$31 million was raised to buy MP votes for CAB3 (now CA3), is its own allegation against government, not a charge against the bloc.
It is unsubstantiated: it appears only in the bloc’s 2 June 2026 statement, with no evidence produced and the accused silent, and is best read as bloc propaganda rather than established fact.
Defining the coalition as 'retired generals, senior civil servants and war veterans' is most likely a deliberate legal and moral posture: it shields participants from subversion or mutiny charges that would attach to serving soldiers and lays claim to liberation-war legitimacy. The deliberate anonymity of the membership is consistent with this shielding logic."
Profiling the generals, the document says "the resistance narrative travels through a measurable information ecosystem, and assessing it is as important as profiling the individuals".
It adds:
"Two distinct phenomena should not be conflated. The bloc is a real, coordinated group whose membership is closely held, a deliberate operational-security choice that keeps participants out of the public record while leaving the convener as the single named face. Separately, the broader anti-Mnangagwa conversation and mobilisation also features self-titled 'retired Lieutenant-General-figures' whose claimed rank and service have no record predating 2026 and cannot be verified; whether or not real individuals sit behind such accounts, that borrowed authority can inflate the apparent seniority of the opposition and should not be treated as part of the verified membership."
Sources told NewsHawks that the camp of generals, some of them remnants of the late former army commander retired General Solomon Mujuru's Zanu PF faction but now loyal to Chiwenga, is currently behind the scenes mobilising around the contentious constitutional changes which they strongly oppose and want urgent further measures against.
Some of them like Muchena were loyal to Mujuru, but now support Chiwenga in the intensifying Zanu PF succession power struggle which sits at the heart of the infighting that has drawn civil society and opposition groups into its volatile vortex.
The generals behind Chiwenga are drifting away from the centre of state power to coalesce with the opposition to form a united front against Mnangagwa.
They want to join forces with a new civil society and opposition organisation, the People's Coalition - Sungano yeVanhu/Ubumbano loMphakathi - formed recently under the convenorship of Reverend Dr. Kupa Mtata.

Besides Mtata, the People's Coalition includes opposition veterans like former Finance minister Tendai Biti, Jameson Timba, Lovemore Madhuku, Jacob Ngarivhume, and many others.
Former main opposition CCC leader Nelson Chamisa is not involved in this initiative.
Although previously linked to Chiwenga’s military faction as part of behind the scenes political realignment between the ruling party and opposition forces, Chamisa is currently battling to shake off accusations of tacitly supporting Mnangagwa for political, ethnic and financial reasons, something that he denies.
He went on a two-year political hiatus in January 2024 and returned in January this year, but has not been in the trenches against Mnangagwa's 2030 project, which he described as a sideshow while claiming there is no constitution to defend in Zimbabwe.
The new coalition, a convergence point for the generals, civic society groups and the opposition, was created to oppose the Constitutional Amendment Act.
It brings together Defend the Constitution Platform, Constitution Defence Forum, National Constitutional Assembly, Zimbabwe Congress of Trade Unions, Zimbabwe Constitution Movement, and part of the war veterans association.
Former commanders also want veteran opposition leader Job Sikhala's National Democratic Working Group to play a key role in the united front.
Some of the generals pushing this initiative are Mujuru's former allies like Muchena, while others are directly close to Chiwenga, for instance Mupande who used to work in his office while he was still Zimbabwe Defence Forces (ZDF) commander before the November 2017 coup.
Mupande, just like the late former Foreign Affairs and International Trade minister retired Lieutenant-General Sibusiso Busi Moyo, worked in Chiwenga's office at ZDF and was his right-hand man.
Chiwenga has deep roots in the army, which he served for 37 years, 14 of those as ZDF commander.
Some of the key former army figures behind him include retired Lieutenant-General Engelbert Rugeje, who is a former Zanu PF political commissar.
Rugeje, who has been sidelined himself like many other former army commanders, has been protesting how Chiwenga and key allies who helped Mnangagwa to take over have been treated.
Chiwenga has a wide network of mainly retired generals who back him, including Sports minister Anselem Sanyatwe, a retired Lieutenant-General who was Zimbabwe National Army (ZNA) commander.
Some of those generals recently gathered at the funeral and burial of Callista Chimhini (née Sanyatwe) on June 10 in Tsvarai Village, Honde Valley, Manicaland Province where Chiwenga was present.
Callista was the wife of human rights activist and former Mutasa North legislator David Anthony Chimhini, and sister to Sanyatwe.
Due to their political fallout with Mnangagwa over extension of his rule from 2028 to 2030, the old commanders are now actively aligned to Chiwenga and fighting the incumbent openly.
The contentious constitutional
changes extend Mnangagwa’s reign by two more years, elongate presidential and parliamentary terms from five to seven years and shift election of President from direct vote to selection by the people's representatives in the legislature.
The changes have drawn intense political fire, pushback and legal challenges from opposition figures, civic organisations, and the retired military veterans who argue they undermine the country's constitution, as well as democratic and institutional framework.
The commanders' intensifying resistance revolves around Zanu PF's succession power struggle as they want Mnangagwa gone to give way to Chiwenga, one of them.
The commanders' collective voice, which carries bigger resonance and political threat than other groups, has replaced that of the late former militant war veteran leader Blessed Geza who fronted Chiwenga’s audacious challenge against Mnangagwa, although he has so far been politically outmanoeuvred at every turn.
Former main opposition CCC leader Nelson Chamisa is not involved in this initiative.
Although previously linked to Chiwenga’s military faction as part of behind the scenes political realignment between the ruling party and opposition forces, Chamisa is currently battling to shake off accusations of tacitly supporting Mnangagwa for political, ethnic and financial reasons, something that he denies.
He went on a two-year political hiatus in January 2024 and returned in January this year, but has not been in the trenches against Mnangagwa's 2030 project, which he described as a sideshow while claiming there is no constitution to defend in Zimbabwe.
The new coalition, a convergence point for the generals, civic society groups and the opposition, was created to oppose the Constitutional Amendment Act.
It brings together Defend the Constitution Platform, Constitution Defence Forum, National Constitutional Assembly, Zimbabwe Congress of Trade Unions, Zimbabwe Constitution Movement, and part of the war veterans association.
Former commanders also want veteran opposition leader Job Sikhala's National Democratic Working Group to play a key role in the united front.
Some of the generals pushing this initiative are Mujuru's former allies like Muchena, while others are directly close to Chiwenga, for instance Mupande who used to work in his office while he was still Zimbabwe Defence Forces (ZDF) commander before the November 2017 coup.
Mupande, just like the late former Foreign Affairs and International Trade minister retired Lieutenant-General Sibusiso Busi Moyo, worked in Chiwenga's office at ZDF and was his right-hand man.
Chiwenga has deep roots in the army, which he served for 37 years, 14 of those as ZDF commander.
Some of the key former army figures behind him include retired Lieutenant-General Engelbert Rugeje, who is a former Zanu PF political commissar.
Rugeje, who has been sidelined himself like many other former army commanders, has been protesting how Chiwenga and key allies who helped Mnangagwa to take over have been treated.
Chiwenga has a wide network of mainly retired generals who back him, including Sports minister Anselem Sanyatwe, a retired Lieutenant-General who was Zimbabwe National Army (ZNA) commander.
Some of those generals recently gathered at the funeral and burial of Callista Chimhini (née Sanyatwe) on June 10 in Tsvarai Village, Honde Valley, Manicaland Province where Chiwenga was present.
Callista was the wife of human rights activist and former Mutasa North legislator David Anthony Chimhini, and sister to Sanyatwe.
Due to their political fallout with Mnangagwa over extension of his rule from 2028 to 2030, the old commanders are now actively aligned to Chiwenga and fighting the incumbent openly.
The contentious constitutional
changes extend Mnangagwa’s reign by two more years, elongate presidential and parliamentary terms from five to seven years and shift election of President from direct vote to selection by the people's representatives in the legislature.
The changes have drawn intense political fire, pushback and legal challenges from opposition figures, civic organisations, and the retired military veterans who argue they undermine the country's constitution, as well as democratic and institutional framework.
The commanders' intensifying resistance revolves around Zanu PF's succession power struggle as they want Mnangagwa gone to give way to Chiwenga, one of them.
The commanders' collective voice, which carries bigger resonance and political threat than other groups, has replaced that of the late former militant war veteran leader Blessed Geza who fronted Chiwenga’s audacious challenge against Mnangagwa, although he has so far been politically outmanoeuvred at every turn.

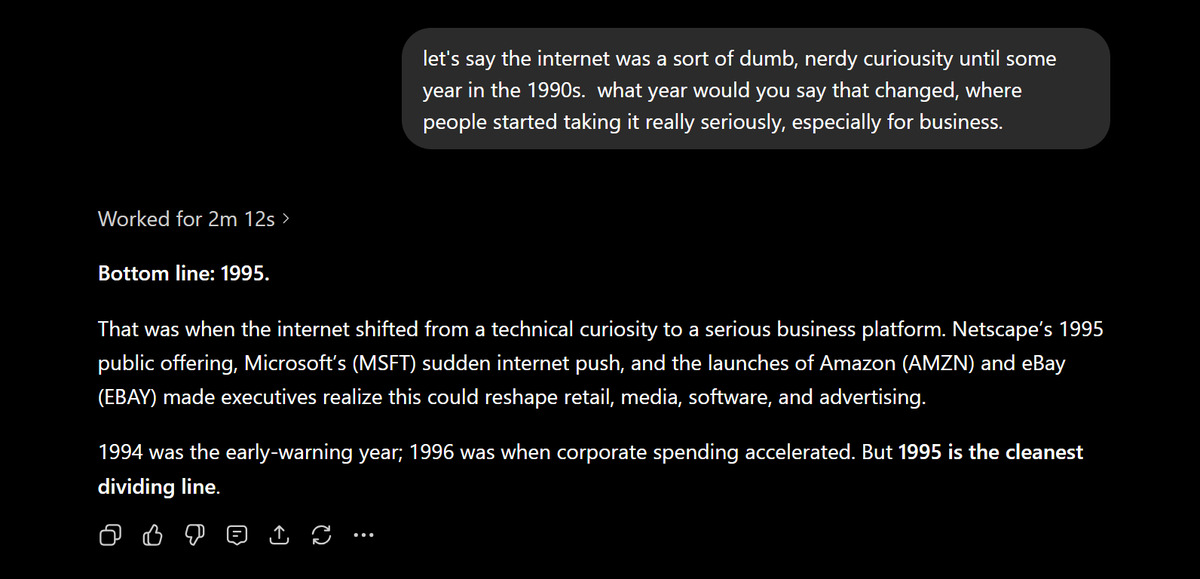
So 4.5 years from dotcom taking off to peaking.
And the "bubble" was fundamentally right until late 1999.
AI took off May 2023. We're 3.25 years in. Semis got to almost +400%, and are currently up ~300% since this began.
And the "bubble" was fundamentally right until late 1999.
AI took off May 2023. We're 3.25 years in. Semis got to almost +400%, and are currently up ~300% since this began.

Maybe semis go up another 150% from here. Nobody knows. I just think the easy money on that theme has already been made. There's of course a great bull outcome. The issue today is that the downside is way higher than at the start of the year. And for longs, I care most about downside
Thread no:- 7
Mrunal Thakur's sultry face plump cock-sucking lips, bedroom eyes, massive heaving tits, thick juicy ass
fingering sloppy, gaping cunt on couch: "Fuck… need huge stranger dick to ruin this married hole."
Delivery knocks. Door cracked. 🔥 #MILFWhore #DeliveryBreed
Mrunal Thakur's sultry face plump cock-sucking lips, bedroom eyes, massive heaving tits, thick juicy ass
fingering sloppy, gaping cunt on couch: "Fuck… need huge stranger dick to ruin this married hole."
Delivery knocks. Door cracked. 🔥 #MILFWhore #DeliveryBreed


Delivery guy steps in, catches her legs splayed, three fingers buried knuckle-deep in squelching wet pussy, juices dripping to couch
D: "Damn ma'am, abusing that greedy married cunt? Hubby’s tiny prick useless?"
Mrunal: "Get out, you fucking perv!"
But eyes lock on his bulge. 😈
D: "Damn ma'am, abusing that greedy married cunt? Hubby’s tiny prick useless?"
Mrunal: "Get out, you fucking perv!"
But eyes lock on his bulge. 😈


He grabs wrist, sucks her dripping fingers clean: "Mmm, desperate cheating MILF tastes like pure slut. Starving for real cock?"
Mrunal pushes weakly: "No… stop… I'm married!"
Tits strain, nipples poke hard.
He rips blouse open, mauls fat boobs roughly: "Moan like the horny 🥵
Mrunal pushes weakly: "No… stop… I'm married!"
Tits strain, nipples poke hard.
He rips blouse open, mauls fat boobs roughly: "Moan like the horny 🥵



Так, чисто згадалось в світлі нинішніх подій.
В 2014 році росіяни призначили керувати АвтоВАЗом шведа Бо Андерссона, це був досвідчений спеціаліст, який мав досвід і до того вже трохи навів порядок на ГАЗі.
В перший же день Андерссона зустріли купою презентацій і застіллям.
В 2014 році росіяни призначили керувати АвтоВАЗом шведа Бо Андерссона, це був досвідчений спеціаліст, який мав досвід і до того вже трохи навів порядок на ГАЗі.
В перший же день Андерссона зустріли купою презентацій і застіллям.
Але він не став на все це дивитись довго і слухати, а пішов... до заводського сральника.
«В перший день, коли я сюди приїхав, я подивився туалети. Вони були брудні, крани текли, туалетного паперу не було. Мені сказали - це така традиція. І багато років люди з цим погоджувалися».
«В перший день, коли я сюди приїхав, я подивився туалети. Вони були брудні, крани текли, туалетного паперу не було. Мені сказали - це така традиція. І багато років люди з цим погоджувалися».
Андерссон віддав розпорядження навести лад, і до вечора це було зроблено. Далі комісія пішла оглядати цехи.
В підвалах вони зустріли близько тисячі робітників, які нібито мали займатись обслуговуванням, але навіть не змогли пояснити чого саме.
По факту роботяги грали в доміно.
В підвалах вони зустріли близько тисячі робітників, які нібито мали займатись обслуговуванням, але навіть не змогли пояснити чого саме.
По факту роботяги грали в доміно.
@cohaerentiat Tous ces échanges sauce Communautarisme/Tribalisme/Minoritisme arriérée anglosaxonne (et leur hypocrite fédéralo-inclusivité lors "d'EvEnTs") sont lamentables ; tellement dénués de sens & cohérences. Ridicule.
Dire qu'en France nous étions avant-gardistes car Universalistes.
1/2
Dire qu'en France nous étions avant-gardistes car Universalistes.
1/2

@cohaerentiat Et dire qu'en France nous étions avant-gardistes, car Universalistes, jusque fin 80' : tous Citoyens, tous Êtres sensibles .
2/n
2/n
@cohaerentiat Nous étions Universalistes…
Ceux discriminant les "différents" étaient criminalisés & empêchés d'exister ; ceux estimant devoir être traités différement (en prônant une pseudo "égalité") car "différents", faisaient logiquement partie du problème : tout est relatif .
3/n
Ceux discriminant les "différents" étaient criminalisés & empêchés d'exister ; ceux estimant devoir être traités différement (en prônant une pseudo "égalité") car "différents", faisaient logiquement partie du problème : tout est relatif .
3/n

RW was cheering when Zionist were killing and doing genocide in palestine,lebanon,and iran against children.they were sympathizing with evil zionist to k!ll more innocent civilians and children.Most of BJP RSS security establishment is based upon Israeli Evil Zionist doctrines.
They are being trained with same rascal mindset.all security rights organizations export a highly militarized aggressive model to civilians field level police officers prioritizes absolute pacification over public safety, beacuse it their traning doctrine that was handed by jews
They could choose how hard they hit,they could have hited softly but still they prioritizd hard hitting with lathi not differentiating between under 18 child and an adult, their lathis had iron nails , iron rods were used Irrespective of age. Whoever came they just smashed

Ok, I'm going to spend a bit working through the 'report'. Join me 🧵
First para already has two doozies. First, 'infiltrated the highest reaches' sounds like it means the White House. Cuba has had some surprisingly high level spies, but nothing like that. Second, 'backed an unprecedented wave of left-wing terrorism' is an unhinged claim, full stop

Second paragraph is similarly bizarre. They sound like they're basically trying to accuse Cuba of a variant of the color revolution conspiracy theory?

Thread no:- 2 (tel)
Sam Lanja Milking b🔥 Telugu Dom Whore Story
Full nasty dom tale! Sam, supreme dominant sissy lanja...
Petite soft body, flat tits, fat limp modda dead meat la flop
Kasiga bulls ni milk chestu, pachiga roast chestu pinduthadi
#TeluguDomSissy #LanjaMilking
Sam Lanja Milking b🔥 Telugu Dom Whore Story
Full nasty dom tale! Sam, supreme dominant sissy lanja...
Petite soft body, flat tits, fat limp modda dead meat la flop
Kasiga bulls ni milk chestu, pachiga roast chestu pinduthadi
#TeluguDomSissy #LanjaMilking


Bull tied spread-eagle, modda already pre-cum leak
Modda kodutu sam vadi face mida thana lavu limp modda prtti slap!
“Pathetic... ni amma laga cum-dump ki kuda better undi ra”
Balls pattukuni hard squeeze
“Ni lanja amma loads cum mingi ni limp-prick loser ni kannadi ra!Thu.!”
Modda kodutu sam vadi face mida thana lavu limp modda prtti slap!
“Pathetic... ni amma laga cum-dump ki kuda better undi ra”
Balls pattukuni hard squeeze
“Ni lanja amma loads cum mingi ni limp-prick loser ni kannadi ra!Thu.!”


Sam manicured nails tho modda mida rakki slow ga torture strokes istu
“Ni sister kuda bigger slut... mommy saggy puku fingers chestu chusthundi”
Bull groan chestu hips jerk
Modda Head pinch: “No cum ra pig. Ni family trash genes valla nuvvu kasi lanja la edge avuthunnav!chi!”
“Ni sister kuda bigger slut... mommy saggy puku fingers chestu chusthundi”
Bull groan chestu hips jerk
Modda Head pinch: “No cum ra pig. Ni family trash genes valla nuvvu kasi lanja la edge avuthunnav!chi!”



#SupremeCourt hears the suo motu case regarding contamination of Rajasthan's Jojari River
Bench: Justices Vikram Nath and Sandeep Mehta
Bench: Justices Vikram Nath and Sandeep Mehta

J Mehta: we will not allow citizens to be poisoned by the state. Howsoever many jobs may go may go. We will save the 20 lakh citizens.
ASG Raju: the factories have been closed. Action should be taken against erring officers.
J Mehta: and who will take that action? What were you doing when you are officers try to prevent the committee from finding out?
Senior Advocate Abhishek Manu Singhvi: the industries have learnt their lesson
J Mehta: and who will take that action? What were you doing when you are officers try to prevent the committee from finding out?
Senior Advocate Abhishek Manu Singhvi: the industries have learnt their lesson
Kerala High Court is hearing the plea preferred by the foreign crew of MSC Elsa 3 ship seeking to return to their home countries
#KeralaHighCourt #MSC #Elsa3
#KeralaHighCourt #MSC #Elsa3

Bench: Justice Bechu Kurian Thomas
The Court had earlier permitted three out of the seven foreign crew members to leave the country on conditions.

Reminder: Many academics were part of the problem, not the solution, during covid crisis.
For example these social psychologists making deadly false statements in spring 2020 such as "the crisis requires large-scale behaviour change"
1/nnature.com/articles/s4156…
For example these social psychologists making deadly false statements in spring 2020 such as "the crisis requires large-scale behaviour change"
1/nnature.com/articles/s4156…
or "individuals all facing the same risk" which is so ridiculous (where were the peer reveiwers?🤦♂️): one main feature of covid-19 is that individuals face very different risk.
2/n
2/n
For example 18-30 year old healthy individuals had so little risk that an IRB gave approval to make a study requiring non immune people to get inoculated with pre-alpha sars-cov-2:
3/n nature.com/articles/s4158…
3/n nature.com/articles/s4158…


1/ The party that built Israel nearly died. Labor — Ben-Gurion's movement, the party that founded the state — was down to 4 seats. Now, merged into HaDemokratim, it just pulled 112,000+ members and 87% turnout into an open primary. A real sign of life on the Israeli left. 🧵

2/ The slate represents the entire Zionist left. Current MKs Naama Lazimi (2), Gilad Kariv (3), Efrat Rayten (4), then protest leaders Yaya Fink and Moshe Radman, ex-Meretz veterans Gaby Lasky and Michal Rozin, Achim LaNeshek's Omri Ronen, and Arab activist Somaya Bashir.
3/ Ronen's placement is its own statement: days before the vote, the Defense Minister Yisrael Katz moved to strip him of reserve duty for his protest activism. The members put him at #7 anyway, a surprise to many. That's a party answering intimidation with a mandate.

Can Europe win a trade war with China? That may depend on how victory is defined
A long-read from me exploring whether Europe has the tools - and the political will - for what comes next.
A long-read from me exploring whether Europe has the tools - and the political will - for what comes next.
As trade tensions with China reach boiling point, EU officials are ramping up engagement with Beijing in search of an off-ramp.
Quietly behind the scenes, though, Europe is preparing for a trade war.
scmp.com/news/china/dip…
Quietly behind the scenes, though, Europe is preparing for a trade war.
scmp.com/news/china/dip…
In Brussels, a steely determination has set in to ensure the bloc’s manufacturing heartlands are not deindustrialised by the “China Shock 2.0”.
scmp.com/news/china/dip…
scmp.com/news/china/dip…

😳😲😲👏👏👏👌👌
#ஆலயம்_அறிவோம்🙏
#நம்ம_கோயம்புத்தூர்💪🙏
#பட்டீஸ்வரர் !!! அதிசயங்கள் ஐந்து!!!
ஐந்து அதிசயங்களை உள்ளடங்கிய ஆயிரமாண்டு ஆலயம் ஒன்று உள்ளது.
கோயம்புத்தூரில் இருந்து மேற்கு திசையில் ஆறாவது கிலோமீட்டர் தொலைவில் உள்ளது "பேரூர் " என்னும்
N/2 👇
#ஆலயம்_அறிவோம்🙏
#நம்ம_கோயம்புத்தூர்💪🙏
#பட்டீஸ்வரர் !!! அதிசயங்கள் ஐந்து!!!
ஐந்து அதிசயங்களை உள்ளடங்கிய ஆயிரமாண்டு ஆலயம் ஒன்று உள்ளது.
கோயம்புத்தூரில் இருந்து மேற்கு திசையில் ஆறாவது கிலோமீட்டர் தொலைவில் உள்ளது "பேரூர் " என்னும்
N/2 👇

பாடல்பெற்ற ஸ்தலம்.
நால்வரால் பாடல்பெற்ற இவ்வாலயம் மேல சிதம்பரம் என்றும் அழைக்கப்படுகிறது.
இங்கு "நடராஜப்பெருமான்" ஆனந்த தாண்டவம் ஆடியபோது . . . அவர் காலில் அணிந்திருந்த சிலம்பு தெறித்து சிதம்பரத்தில் விழுந்ததாக செவிவழிச் செய்தியும் உண்டு.
இக்கோவிலில் ஐந்து அதிசயங்கள்
N/3 👇
நால்வரால் பாடல்பெற்ற இவ்வாலயம் மேல சிதம்பரம் என்றும் அழைக்கப்படுகிறது.
இங்கு "நடராஜப்பெருமான்" ஆனந்த தாண்டவம் ஆடியபோது . . . அவர் காலில் அணிந்திருந்த சிலம்பு தெறித்து சிதம்பரத்தில் விழுந்ததாக செவிவழிச் செய்தியும் உண்டு.
இக்கோவிலில் ஐந்து அதிசயங்கள்
N/3 👇
எது என்றால்,. . .
*இறவாத "பனை",
*"பிறவாத புளி,"
*"புழுக்காத சாணம்,"
*"எலும்பு கல்லாவது,"
*"வலதுகாதுமேல் நோக்கிய நிலையில் இறப்பது."
"இதுதான் அந்த அதிசயங்கள்"
இறவாத பனை:-
பல ஆண்டுகாலமாக இன்றும் பசுமை மாறாமல் இளமையாகவேஒருபனைமரம் நின்று கொண்டிருக்கிறது.
N/4 👇
*இறவாத "பனை",
*"பிறவாத புளி,"
*"புழுக்காத சாணம்,"
*"எலும்பு கல்லாவது,"
*"வலதுகாதுமேல் நோக்கிய நிலையில் இறப்பது."
"இதுதான் அந்த அதிசயங்கள்"
இறவாத பனை:-
பல ஆண்டுகாலமாக இன்றும் பசுமை மாறாமல் இளமையாகவேஒருபனைமரம் நின்று கொண்டிருக்கிறது.
N/4 👇

A Child Psychiatrist Stopped Fighting Phones.
Instead, Parents Were Told To Show Their Kids These 6 Documentaries.
Many children started seeing social media differently.
Here's what they watched:
Instead, Parents Were Told To Show Their Kids These 6 Documentaries.
Many children started seeing social media differently.
Here's what they watched:

The Social Dilemma (2020)
Former executives from major tech companies explain how social media platforms are designed to maximize engagement.
Former executives from major tech companies explain how social media platforms are designed to maximize engagement.

The documentary explores notifications, recommendation algorithms, and infinite scrolling.
Many parents say it's the first time their teenagers understand why it's so hard to put the phone down.
Many parents say it's the first time their teenagers understand why it's so hard to put the phone down.

1/ Claims by a senior Russian military official that the Russian army's tactical medicine system is efficient and rapid are greeted with incredulity by Russian commentators. They point out that wounded soldiers are often not evacuated for days or weeks. ⬇️
2/ Deputy Minister of Defence Anna Tsivileva – a relative of Putin's who was controversially appointed a lieutenant general despite no previous military experience – has given an upbeat assessment of the performance of Russian tactical medicine.
3/ At a board meeting of the Russian MOD, Tsilvileva said that since December 2025, work has been undertaken as a high priority to improve the speed of evacuations and the quality of primary care on the front lines.

सर्वाधिक धावपळ आता सुरु असेल भाजपच्या IT cell च्या ऑफिस मधे. हजारो पेड लेखक आता आजच्या आंदोलनाच्या विरोधात narative set करण्यासाठी असे लेख लिहतील की, जणू देशद्रोही आंदोलन होते. फोटो कुठले कुठले खोटे उचलतील ज्यात एखादा मुलगा गाडी फोडतो आहे, टायर जळतो आहे, मुलींना मारतो आहे,
देशा विरोधात नारे असणारे मॉर्फ केलेले बोर्ड वैगरे वैगरे आणि त्याच्या खाली मोठे लेख असणार की, बघा हे आहेत का विद्यार्थी वैगरे वैगरे. हे तर anti nationalist आहेत, हे तर विदेशी ताकद सोबत मिळून देशात अराजकता निर्माण करायला बघतायत वैगरे वैगरे. आणि हे सर्व मॅसेज मोठ्याप्रमाणावर वायरल
करतील whats app वर, फेसबुक वर वैगरे वैगरे. मग यूट्यूब वर सुपारीबाज पेड यूट्यूबर्स लोकांना हाच अँगल घेऊन खोटे खोटे वीडियो बनवायला लावतील आणि मग वायरल करतील. आता यांचे अंधभक्त आणि स्लीपर सेल वैगरे असतातच मग ते फॉरवर्ड करणार, सामान्य माणसाला काही त्यातले बिलकुल ज्ञान नसते की

SitRep - 20/07/26 - General Command changes are coming
An overview of the daily events in Russia's invasion of Ukraine. While current commander-in-chief Syrskyi is 'unaware' of a conflict, Ukraine's general command will be changed.
REPOST=appreciated
1/X
An overview of the daily events in Russia's invasion of Ukraine. While current commander-in-chief Syrskyi is 'unaware' of a conflict, Ukraine's general command will be changed.
REPOST=appreciated
1/X

Missed the latest?
As usual we start with Russian losses

結局好き嫌い
正攻法か否か
たとえば凄く汚い無愛想店主のラーメン屋でも味に定評があれば、それ目的で行く客は居るし
どんなにダサくても安さ最優先で
ダサさ度外視する場合もあるし
既存客、リピーターか新規か...
そういうのいろいろ悩まんでいい余裕がある店が、こういう好き放題やって遊ぶ(続
正攻法か否か
たとえば凄く汚い無愛想店主のラーメン屋でも味に定評があれば、それ目的で行く客は居るし
どんなにダサくても安さ最優先で
ダサさ度外視する場合もあるし
既存客、リピーターか新規か...
そういうのいろいろ悩まんでいい余裕がある店が、こういう好き放題やって遊ぶ(続
続)ことができるというか。
同調圧かその逆の意外性か、あ〜だから一昔前にGUCCIやVUITTONがgraffitiシリーズ出していた時も、余裕の自信からの遊び心好き放題で、そしてそれを新たな定義とする
トレンドセッター感..
アートだ!と言ってしまえばいそれで突破できる風潮。見た目優先か実用性か(続
同調圧かその逆の意外性か、あ〜だから一昔前にGUCCIやVUITTONがgraffitiシリーズ出していた時も、余裕の自信からの遊び心好き放題で、そしてそれを新たな定義とする
トレンドセッター感..
アートだ!と言ってしまえばいそれで突破できる風潮。見た目優先か実用性か(続
続)...今はAI賛否と、AIが新しいおもちゃ状態で大普及しとるフェーズだから、嫌いな人は気に食わないし、好きな人は何を言われようがお構いなしに使いまくる。
たまたま題材はAIだけど、いろんな流行りで同じようなことは起きるし繰り返されるし、批判され叩かれてもなお貫く人やめる人、さまざま(続
たまたま題材はAIだけど、いろんな流行りで同じようなことは起きるし繰り返されるし、批判され叩かれてもなお貫く人やめる人、さまざま(続

Understanding SWIM Through the Lens of The Odyssey: Odysseus, Penelope and the Long Journey Home 🏊♂️
There are a lot of ways BTS's SWIM can be interpreted, but it still has a defined overarching meaning. The central idea draws from these lines by Rainer M. Rilke that RM shared in his letter* before the release - "Let everything happen to you: beauty and terror. Just keep going. No feeling is final"**. The song gradually walks you through its meaning.
When I found out that the model ship used in the SWIM video is named 'Ulysses' (Latin for Odysseus), I went back and reread the Odyssey. I noticed several thematic parallels, specially with SWIM, but also across all the songs on ARIRANG. I thought about doing separate analyses for the lyrics, the parallels and the MV. But I think bringing all these elements together actually helps map its ambiguity.
With this analysis, I don't intend to solve the song. Rather, I simply want to place these elements side by side to allow them to interact with each other and draw out the interpretation.
🧵 This is going to be a really long thread and a bit heavy, but this is the only way I can come up with to try and explain it.
____________________
Notes:
1. *RM's letter: weverse.io/bts/fanpost/2-…
2. **From the poem 'Go to the Limits of Your Longing' by Rainer Maria Rilke.
(1/54)
There are a lot of ways BTS's SWIM can be interpreted, but it still has a defined overarching meaning. The central idea draws from these lines by Rainer M. Rilke that RM shared in his letter* before the release - "Let everything happen to you: beauty and terror. Just keep going. No feeling is final"**. The song gradually walks you through its meaning.
When I found out that the model ship used in the SWIM video is named 'Ulysses' (Latin for Odysseus), I went back and reread the Odyssey. I noticed several thematic parallels, specially with SWIM, but also across all the songs on ARIRANG. I thought about doing separate analyses for the lyrics, the parallels and the MV. But I think bringing all these elements together actually helps map its ambiguity.
With this analysis, I don't intend to solve the song. Rather, I simply want to place these elements side by side to allow them to interact with each other and draw out the interpretation.
🧵 This is going to be a really long thread and a bit heavy, but this is the only way I can come up with to try and explain it.
____________________
Notes:
1. *RM's letter: weverse.io/bts/fanpost/2-…
2. **From the poem 'Go to the Limits of Your Longing' by Rainer Maria Rilke.
(1/54)

Why approach the interpretation of the song this way?
The album seems to resonate between three expansive frameworks:
🔴 The Odyssey, which is complex and accumulative;
🔴 BTS's own journey, which is complex and accumulative;
🔴 and the folk song Arirang, which is also complex and accumulative.
They sort of bounce off each other and pinning down the meaning without flattening it is really difficult. With SWIM, preserving its ambiguity is not just a stylistic choice. It helps retain its layered meaning.
__________
Notes:
The musical Ari Arari - musicalsofkorea.com/k-musicals-in-…
(2/54)
The album seems to resonate between three expansive frameworks:
🔴 The Odyssey, which is complex and accumulative;
🔴 BTS's own journey, which is complex and accumulative;
🔴 and the folk song Arirang, which is also complex and accumulative.
They sort of bounce off each other and pinning down the meaning without flattening it is really difficult. With SWIM, preserving its ambiguity is not just a stylistic choice. It helps retain its layered meaning.
__________
Notes:
The musical Ari Arari - musicalsofkorea.com/k-musicals-in-…
(2/54)

What is the Odyssey?
The Odyssey is one of the foundational works of Western literature and among the earliest surviving epic poems. It is attributed to Homer, though it likely existed in oral tradition for centuries before being written down.
Originally written in Ancient Greek, there are various translations of the Odyssey in English with slightly different nuances. Though the plot of the Odyssey is fairly concrete, its interpretations can vary considerably between readers.*
It follows Odysseus's arduous ten-year journey back to Ithaca after the Trojan War, delayed by errors, misfortune, monsters, and divine intervention. Meanwhile, his wife Penelope awaits his return, preserving his household and fending off suitors back home.
Is it a love story? In a way, but it is primarily centered on nostos.
______________________________
Notes:
1. *In this analysis, I interpret it as it intersects with the song.
2. Image : Section of the 'Ulixes mosaic' in the Bardo National Museum.
(3/54)
The Odyssey is one of the foundational works of Western literature and among the earliest surviving epic poems. It is attributed to Homer, though it likely existed in oral tradition for centuries before being written down.
Originally written in Ancient Greek, there are various translations of the Odyssey in English with slightly different nuances. Though the plot of the Odyssey is fairly concrete, its interpretations can vary considerably between readers.*
It follows Odysseus's arduous ten-year journey back to Ithaca after the Trojan War, delayed by errors, misfortune, monsters, and divine intervention. Meanwhile, his wife Penelope awaits his return, preserving his household and fending off suitors back home.
Is it a love story? In a way, but it is primarily centered on nostos.
______________________________
Notes:
1. *In this analysis, I interpret it as it intersects with the song.
2. Image : Section of the 'Ulixes mosaic' in the Bardo National Museum.
(3/54)

Delhi High Court to shortly hear appeal filed by activist Sonam Wangchuk’s wife against a single judge order refusing to pass any interim order allowing Wangchuk to be shifted to a private hospital of his choice.
@Wangchuk66 @GitanjaliAngmo @CJP_for_India
@Wangchuk66 @GitanjaliAngmo @CJP_for_India

Yesterday, the Court sought all medical records and health bulletins concerning Wangchuk and requested doctors to remain present today.
Read:
Read:
The matter will be heard by a division bench comprising Chief Justice DK Upadhyaya and Justice Tejas Karia.
Hearing to commence soon. Follow this thread for live updates.
Hearing to commence soon. Follow this thread for live updates.

🧵1/5
Vi siete fatti somministrare un vaccino sperimentale ed avete inveito contro coloro che si sono rifiutati.
Vi siete scagliati contro Putin quando gli stessi oligarchi statunitensi hanno ammesso di aver organizzato e finanziato il colpo di Stato Ucraino in chiave antirussa.
Vi siete fatti somministrare un vaccino sperimentale ed avete inveito contro coloro che si sono rifiutati.
Vi siete scagliati contro Putin quando gli stessi oligarchi statunitensi hanno ammesso di aver organizzato e finanziato il colpo di Stato Ucraino in chiave antirussa.

Avete chiamato terroristi i gazawi, quando gli ebrei occupano illegalmente la Palestina e sterminano i nativi da quasi 80 anni.
Vi scandalizzate per il regime iraniano, quando gli USA fanno carne di porco dei diritti umani e del principio di autodeterminazione dei popoli ovunque.
Vi scandalizzate per il regime iraniano, quando gli USA fanno carne di porco dei diritti umani e del principio di autodeterminazione dei popoli ovunque.

Pensate che l'€ e l'Unione Europea vi abbiano tutelato, quando è proprio tramite questi strumenti di dominio che i popoli europei sono stati progressivamente impoveriti ed umiliati.
Inveite contro il contante quando in realtà la moneta cartacea è l'ultimo baluardo della libertà.
Inveite contro il contante quando in realtà la moneta cartacea è l'ultimo baluardo della libertà.

#SupremeCourt hears the Kerala Wakf Board's plea challenging the Kerala HC's recent order restraining it from taking major policy decisions over absence of 2 non-Muslim members
Bench: CJI Surya Kant, J Joymalya Bagchi and J Vipul M Pancholi
Sr Adv K Parmeswar (for respondents): State appeared and conceded...
J Bagchi: Whatever may be, we will call upon the state to report on compliance
Sr Adv Jaideep Gupta (for State): Order says it's posted for tomorrow. This is an interim order. There is no reason why your lordships should interfere at this stage
J Bagchi: Why should the Board for this reason stand handicapped by this restriction?
Parmeswar: Jt. Secy is part of the statutory Board!
Sr Adv Huzefa Ahmadi (for Waqf Board) - State is supporting the petitioner.
Bench: CJI Surya Kant, J Joymalya Bagchi and J Vipul M Pancholi
Sr Adv K Parmeswar (for respondents): State appeared and conceded...
J Bagchi: Whatever may be, we will call upon the state to report on compliance
Sr Adv Jaideep Gupta (for State): Order says it's posted for tomorrow. This is an interim order. There is no reason why your lordships should interfere at this stage
J Bagchi: Why should the Board for this reason stand handicapped by this restriction?
Parmeswar: Jt. Secy is part of the statutory Board!
Sr Adv Huzefa Ahmadi (for Waqf Board) - State is supporting the petitioner.

Gupta: In one case, issue is of absence of 2 Non-Muslims...in another, ratio of Shia Muslims has to be determined
Another Sr Adv (for Board): ad-interim order passed in a PIL! Behind the back of the Board
CJI: We are only concerned with para 6 (restraining policy decisions without leave of Court)
Ahmadi: Notification (14.02.2026) originally appointed 9 members. They have term of 5 years. What they want to do is - they want to substitute them with their own people. That's the game. PIL filed by someone who belongs to a political party.
#SupremeCourt #KeralaWaqfBoard
Another Sr Adv (for Board): ad-interim order passed in a PIL! Behind the back of the Board
CJI: We are only concerned with para 6 (restraining policy decisions without leave of Court)
Ahmadi: Notification (14.02.2026) originally appointed 9 members. They have term of 5 years. What they want to do is - they want to substitute them with their own people. That's the game. PIL filed by someone who belongs to a political party.
#SupremeCourt #KeralaWaqfBoard
Ahmadi: Where was the question of saying that Board can't function? And natural justice? I appear before court and say give me time...members of Waqf Board are not served with copy...extraordinary order passed. S. 14 does not say that if there is any vacancy, then Board becomes defunct
A counsel: The impugned order is in 4 petitions. One was for reconstitution of Board
Ahmadi: The only ground raised in HC order is non-appointment of Non-Muslim members
J Bagchi: This is an ad-interim order. Question of your prejudice can be taken care of by seeking modification of that order. And we can give that liberty. The extent to which it becomes egregious interference in day-to-day functioning...we will set aside last line.
#SupremeCourt
A counsel: The impugned order is in 4 petitions. One was for reconstitution of Board
Ahmadi: The only ground raised in HC order is non-appointment of Non-Muslim members
J Bagchi: This is an ad-interim order. Question of your prejudice can be taken care of by seeking modification of that order. And we can give that liberty. The extent to which it becomes egregious interference in day-to-day functioning...we will set aside last line.
#SupremeCourt

Gestern las ich in einer angesehenen deutschen Zeitung: "Ein Ende von Putins Regime ist nicht absehbar“. Warum dieser Satz? Man kann viele Thesen aufstellen, aber dass Putins Zeit abgelaufen ist und viele Eliten ihn nicht mehr ernst nehmen, wird jeden Tag offensichtlicher. /1
Dabei verweisen die vielen Artikel über die angebliche Stabilität von Putins Regime doch genau darauf: Der Mythos der Stabilität wird immer unglaubwürdiger und ist nicht Resultat eines realitätsfremdem westlichen Wunschdenkens, sondern kommt von den russischen Eliten selbst./2
Momentan können nur wenige Leute ein Zukunftsszenario Russlands zeichnen, denn niemand weiß genau, was kommt. Dieser Mangel an Zukunft, an Vertrauen in die Zukunft und an Vorstellungskraft ist es, was so verräterisch in der Gegenwart ist./3

Co se dá stihnout za 1 den v Bologni? 🇮🇹
Pojďte se mnou na výlet 👇vlákno:
Pojďte se mnou na výlet 👇vlákno:

Začínáme nádherným impozantním kostelem S. Pietro, který potkáte po cestě, pokud se vydáte z autobusového, nebo vlakového nádraží.
Projdete se řadou portiků, které mají mimochodem dokonce od roku 2021 o ochranu UNESCO! 👀🎨
Projdete se řadou portiků, které mají mimochodem dokonce od roku 2021 o ochranu UNESCO! 👀🎨


Kdybyste napočítali všechny portiky v Bologni - můžete se v nich procházet 60 kilometrů, opravdu světové unikum.
Nehledě na to, že jsou krásné a velmi praktické, když prší ☔️😃
Nehledě na to, že jsou krásné a velmi praktické, když prší ☔️😃


🔥 D O Z O R the Destroyer ☠️
This Toonie Tuesday we are supporting “D O Z O R” Special Operations Response Unit of the Ukrainian Defense Forces. We will be raising $13,500 as they are in urgent need of a VW Amarock vehicle for their team. They are the unit that outmaneuvered elite russian Senezh operatives in Sumy!
PP: Bogdan.nelen@gmail.com
Jar: send.monobank.ua/jar/8JstDMfKTy
💳 4874 1000 3031 7088
Donate €2 £2 $2 📬 screenshot in replies & repost
Check out @ky_painter ‘s pinned post, a chance to win a portrait with your fella.
Be sure to watch the video, visit our profile, bookmark the post, like and retweet, quote tweet even better, let’s go!
This Toonie Tuesday we are supporting “D O Z O R” Special Operations Response Unit of the Ukrainian Defense Forces. We will be raising $13,500 as they are in urgent need of a VW Amarock vehicle for their team. They are the unit that outmaneuvered elite russian Senezh operatives in Sumy!
PP: Bogdan.nelen@gmail.com
Jar: send.monobank.ua/jar/8JstDMfKTy
💳 4874 1000 3031 7088
Donate €2 £2 $2 📬 screenshot in replies & repost
Check out @ky_painter ‘s pinned post, a chance to win a portrait with your fella.
Be sure to watch the video, visit our profile, bookmark the post, like and retweet, quote tweet even better, let’s go!

🔥 D O Z O R the Destroyer ☠️
$495 pushing toward the $13,500 goal
ONE VEHICLE, COUNTLESS MISSIONS - One VW can serve in countless ways, transporting personnel, delivering vital supplies, supporting reconnaissance, and reaching places larger vehicles simply can't.
All it takes is €2, £2, or $2. Every toonie brings us one step closer. Can't donate today? Please like, share, and leave a comment. Every interaction helps reach more people.
🅿️🅿️: Bogdan.nelen@gmail.com (other $$ options in pinned post)
$495 pushing toward the $13,500 goal
ONE VEHICLE, COUNTLESS MISSIONS - One VW can serve in countless ways, transporting personnel, delivering vital supplies, supporting reconnaissance, and reaching places larger vehicles simply can't.
All it takes is €2, £2, or $2. Every toonie brings us one step closer. Can't donate today? Please like, share, and leave a comment. Every interaction helps reach more people.
🅿️🅿️: Bogdan.nelen@gmail.com (other $$ options in pinned post)

🔥 D O Z O R the Destroyer ☠️
$706 pushing toward the $13,500 goal!
ONE VEHICLE, COUNTLESS MISSIONS - One VW can serve in countless ways, transporting personnel, delivering vital supplies, supporting reconnaissance, and reaching places larger vehicles simply can't.
All it takes is €2, £2, or $2. Every toonie brings us one step closer. Can't donate today? Please like, share, and leave a comment. Every interaction helps reach more people.
PP: Bogdan.nelen@gmail.com (other $$ options in pinned post)
Check out @ky_painter ‘s pinned post, a chance to win a portrait of your fella.
$706 pushing toward the $13,500 goal!
ONE VEHICLE, COUNTLESS MISSIONS - One VW can serve in countless ways, transporting personnel, delivering vital supplies, supporting reconnaissance, and reaching places larger vehicles simply can't.
All it takes is €2, £2, or $2. Every toonie brings us one step closer. Can't donate today? Please like, share, and leave a comment. Every interaction helps reach more people.
PP: Bogdan.nelen@gmail.com (other $$ options in pinned post)
Check out @ky_painter ‘s pinned post, a chance to win a portrait of your fella.


@AZoepfgen @JTrittin @Evonik Eigentlich war es nicht Frau Merkel, sondern Herr Scholz !
@AZoepfgen @JTrittin @Evonik Frau Merkel hat die Grenzen damals nicht geschlossen, doch die Völkerwanderung hat die SPD zu verantworten.
@AZoepfgen @JTrittin @Evonik Here is an article that deals with the processing of the refugee crisis, how the Social Democrats sinned against the poorest people, and why immigration policy is not only a question of internal security but also of ethics. threadreaderapp.com/thread/1962652…
How do people interpret the "Composer training and RL" bar here?
I see 3 possibilities:
I see 3 possibilities:
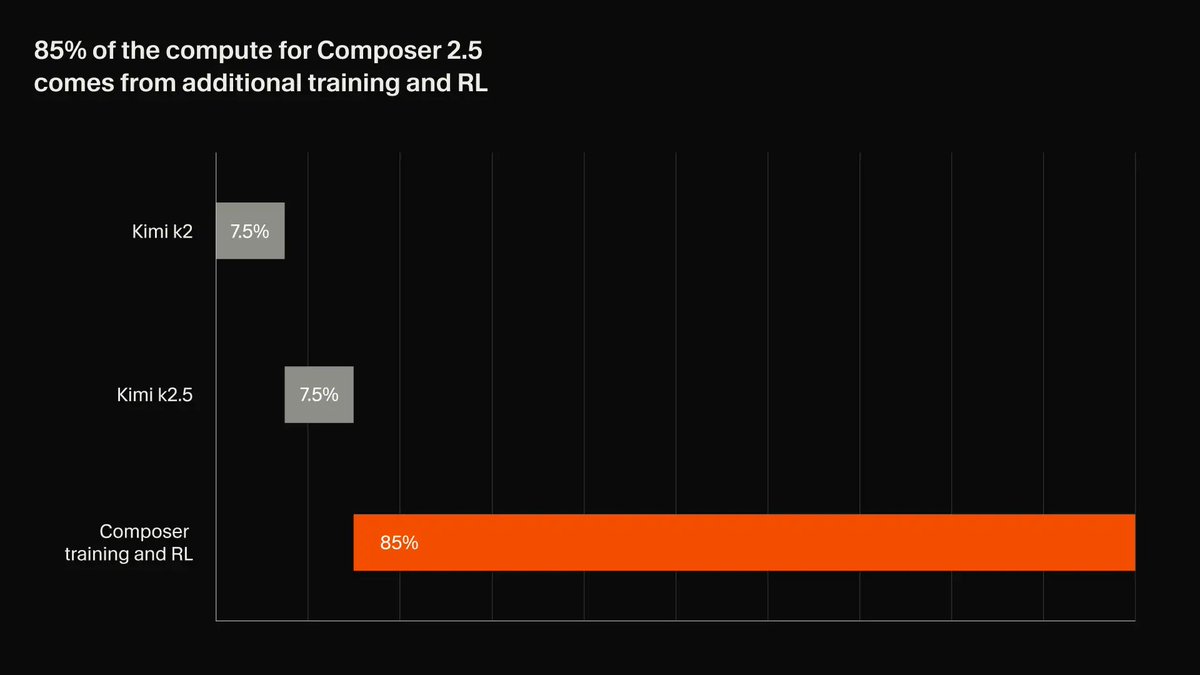
(1) that 85% is confusing/misleading, eg it includes all R&D for Composer training rather than final runs, or it's compute spending rather than FLOPS and RL has way lower MFU
(2) continued pretraining is a >1/2 of these 85%: that means >100T tokens for 32B activated params and 1T total params. I wouldn't have expected as much overtraining (especially given the focus on code).

1/11 NO, you DON'T have actual facts, what you have is BLATANT misinformation that morons like YOU keep spreading around social media sites stating Joe Biden molested his daughter...which is PURE bullshit...which I ALWAYS correct. I'll start with BULLSHIT. Next, I'll ask HOW many
2/11 rapes have Joe Biden been charged with; ZERO. How many allegations from different women of Joe Biden being a sexual predator; ZERO. Trump: A court has ALREADY concluded he raped E. Jean Carroll, and there are about 22 OTHER rape allegations against Trump, PERIOD. You people
3/11 ALWAYS try to refer to Biden when making excuses for the POS you worship. "Trump raped a woman"; "Well Joe Biden raped his daughter!" (BULLSHIT...he showered with her...a HUGE difference; while not appropriate, it is NOT rape, and she has NEVER said he raped her OR fucking
#SupremeCourt to hear today Meghalaya govt's plea challenging the HC order granting bail to Sonam Raghuwanshi, prime suspect in the chilling May 2025 "honeymoon murder" of her husband Raja Raghuwanshi
Bench: Justice MM Sundresh and Justice PB Varale.
Bench: Justice MM Sundresh and Justice PB Varale.

The High Court granted Sonam bail on the ground that grounds of arrest were not fully supplied to her at the time of arrest.
Meghalaya govt has claimed that there was only a typographical error in the grounds supplied, as S.103(1) BNS was mentioned as S.403(1).
Meghalaya govt has claimed that there was only a typographical error in the grounds supplied, as S.103(1) BNS was mentioned as S.403(1).
Matter taken up.
Solicitor General Tushar Mehta: I am challenging the grant of bail. It is not for cancellation of bail. The respondent was married to some person. Immediately they go for honeymoon to Meghalaya. According to our investigation which is supported by the evidence lead her husband to be taken to an isolated place in the hills. 3 persons hired by her through her paramour were following her. Eventually the husband was killed. The wife also participated in the killing and the body was thrown in the ditch.
Solicitor General Tushar Mehta: I am challenging the grant of bail. It is not for cancellation of bail. The respondent was married to some person. Immediately they go for honeymoon to Meghalaya. According to our investigation which is supported by the evidence lead her husband to be taken to an isolated place in the hills. 3 persons hired by her through her paramour were following her. Eventually the husband was killed. The wife also participated in the killing and the body was thrown in the ditch.
4 lies you have been told about volume:
Big green bar means buyers won
Low volume means nobody is interested
A volume spike confirms the breakout
More volume is better
I believed all four for years. Each one cost me money.
Here is how I read it now ↓
Big green bar means buyers won
Low volume means nobody is interested
A volume spike confirms the breakout
More volume is better
I believed all four for years. Each one cost me money.
Here is how I read it now ↓


#BREAKING TMC MP Mahua Moitra moves Calcutta High Court against a compliant filed against her.
Counsel: She was attacked by a mob, eggs were pelted at her. She merely asked the egg pelters to face her directly and not hide in the crowd. Complaint was registered saying she insulted Hindu girls by religion. @MahuaMoitra
Counsel: She was attacked by a mob, eggs were pelted at her. She merely asked the egg pelters to face her directly and not hide in the crowd. Complaint was registered saying she insulted Hindu girls by religion. @MahuaMoitra
Counsel: No offence has been disclosed
Counsel: the word “Hindu” was never uttered by the petitioner. What is bizarre is the repetitive issuance of 35(3) notices. She is attending the monsoon session of parliament. My prayer is to get no coercive steps and so that I can appear before them in virtual mode. I am ready to cooperate

As large Protest Movements, the JP movement (1974-75) and the Anti- corruption movement (2011-13) stand out as good precedents to compare the Cockroach movement.. 1/15
The Cockroach movement is much more unorganized than the other two and relies more on spontaneity and suppressed anxieties. It's also less nationally spread out-- though its reverberations may now be felt beyond Delhi 2/15
In JP movement, there was a slow but sure coming together of constitutional forces and those who always wanted to subvert constitution. It was also a combination of conservative+rightist forces and progressive+ left-of- centre forces 3/15

MODHATI ANUBHAVAM part - 1
First time is very special for Everyone
Adi btech final year time naku Chala free time undedi subjects aypoyi project aypoyi emcheyalo telika laptop ekuva use chesanu ala porn chustu chustu gay, shemale type of things chusanu Chala excited ayanu nenu😩
First time is very special for Everyone
Adi btech final year time naku Chala free time undedi subjects aypoyi project aypoyi emcheyalo telika laptop ekuva use chesanu ala porn chustu chustu gay, shemale type of things chusanu Chala excited ayanu nenu😩

Alaala chustu one day add vachindi sites lo open cheste it's a app Miku telse untundi le.
Grindr Ani install chesi chusa naku entaduram lo entamandi unaro chusi shock Aya inthamandi karuvulo unara ani.
Ah profile names chudali okaokati diamond asala. Apudey ok msg vachindi hi ani
Grindr Ani install chesi chusa naku entaduram lo entamandi unaro chusi shock Aya inthamandi karuvulo unara ani.
Ah profile names chudali okaokati diamond asala. Apudey ok msg vachindi hi ani

Naku ventane em reply ivalo ardamkala. Nenu same hi ananu
Tanu ASL anadu ante age sex location Ani. Chepanu tana age 26 anadu nakana 8 years pedda ananu
👦🏽: Iyte Enti age lo emundi Niku emkavalo adi nadegara undiga inkem undali
Me: blank kasepu videnti intha direct ga anadu ani👀
Tanu ASL anadu ante age sex location Ani. Chepanu tana age 26 anadu nakana 8 years pedda ananu
👦🏽: Iyte Enti age lo emundi Niku emkavalo adi nadegara undiga inkem undali
Me: blank kasepu videnti intha direct ga anadu ani👀


1/n
Every time a Parliament Session Starts... and the INDIA Bloc Immediately Starts Protesting!
Why does productive legislative work in Parliament always get hijacked the moment a session begins?
Look no further than Rahul Gandhi, Arvind Kejriwal, and their INDIA bloc allies.
Instead of debating bills, scrutinizing policies constructively, or letting the House function, they repeatedly choose chaos... walkouts, slogan-shouting, dharna inside the House, and engineered adjournments.
This isn't opposition; this is obstruction. Public money is wasted, important legislation is delayed, and democracy suffers while they play political theatre.
Every time a Parliament Session Starts... and the INDIA Bloc Immediately Starts Protesting!
Why does productive legislative work in Parliament always get hijacked the moment a session begins?
Look no further than Rahul Gandhi, Arvind Kejriwal, and their INDIA bloc allies.
Instead of debating bills, scrutinizing policies constructively, or letting the House function, they repeatedly choose chaos... walkouts, slogan-shouting, dharna inside the House, and engineered adjournments.
This isn't opposition; this is obstruction. Public money is wasted, important legislation is delayed, and democracy suffers while they play political theatre.
2/n
Here’s the pattern - session after session:
2023 Monsoon Session:
The INDIA bloc, led aggressively by Rahul Gandhi and Congress, paralysed proceedings demanding a discussion on Manipur violence. They insisted on a statement from PM Modi and refused to let normal business proceed for days. Slogans, protests, and repeated adjournments became the norm. The government tried to move forward; the opposition chose disruption. Rahul Gandhi was at the forefront, turning Parliament into a protest ground rather than a law-making body.
Here’s the pattern - session after session:
2023 Monsoon Session:
The INDIA bloc, led aggressively by Rahul Gandhi and Congress, paralysed proceedings demanding a discussion on Manipur violence. They insisted on a statement from PM Modi and refused to let normal business proceed for days. Slogans, protests, and repeated adjournments became the norm. The government tried to move forward; the opposition chose disruption. Rahul Gandhi was at the forefront, turning Parliament into a protest ground rather than a law-making body.
3/n
December 2023 Winter Session — The Biggest Disruption Yet:
Two intruders entered Parliament (a serious security breach). Instead of allowing a proper inquiry and debate, the INDIA bloc (Congress, AAP, TMC, and others) turned it into a massive ruckus. They shouted slogans, demanded Amit Shah’s resignation, and created pandemonium. Result? A record 143 opposition MPs (mostly from INDIA bloc) were suspended... the largest such action in history. Parliament’s functioning was severely hampered for days. Rahul Gandhi and the bloc turned a security issue into another opportunity for street-style protest inside the sanctum of democracy.
December 2023 Winter Session — The Biggest Disruption Yet:
Two intruders entered Parliament (a serious security breach). Instead of allowing a proper inquiry and debate, the INDIA bloc (Congress, AAP, TMC, and others) turned it into a massive ruckus. They shouted slogans, demanded Amit Shah’s resignation, and created pandemonium. Result? A record 143 opposition MPs (mostly from INDIA bloc) were suspended... the largest such action in history. Parliament’s functioning was severely hampered for days. Rahul Gandhi and the bloc turned a security issue into another opportunity for street-style protest inside the sanctum of democracy.

The more I learn about Chinese history the more jealous I am for them— they have a much longer, almost overwhelmingly so, tradition of record keeping. In the West, ones antiquity comes out of cosmopolitanism— we must look far afield to find our ancient records.
The West’s much easier time with simply “abandoning tradition” is a benefit of this— to simply “forego having a past” of being concretely determined by Time— it is, ultimately, a sort of delusion, but one that inspires a recklessness that can be fruitful as well as harmful.
In truth, the West since the Bronze Age Collapse has been ruled by Gangsters— this is what Nolan is getting at, I reckon (have not seen it yet). It is the fundamental betrayal of civilization that founds the West, & it even self-consciously understands itself to be anointed to effectively usher in the end of history, which is its own sublation into civilization in the form of Communism.

Tag drei nach Jens Spahn und während weite Teile des Landes aufatmen, dass er fürs erste weg ist, strickt die vom Verlust betroffene Döpfner-Gang Legenden. Und versucht so die allzu große Nähe zwischen Springer und Spahn (auf die auch ich hingewiesen hatte) zu vertuschen. 1/x 🧵

Spahn Kritiker sollen entweder “homophob” (die wirklich in jeder Hinsicht allerletzte Verteidigungslinie) sein, der Rücktritt eigentlich ein genialer Move von Spahn, und überhaupt: „Merz ist schuld!“
Kein Take ist zu verrückt, um den Springer-Joker im Bundestag zu schützen. 2/x
Kein Take ist zu verrückt, um den Springer-Joker im Bundestag zu schützen. 2/x
Michael Bröcker, der unabhängige Spahn-Biograf, der noch vor ein paar Tagen auf der Vespa zu Spahns Geburtstag reiste, und seit gestern auch offiziell Springer-Kumpel is, fragte ernsthaft, ob nun auch “alle Fremdgeher” zurücktreten würden? 3/x


🧵When Ukrainian drones ripped the tail off a Russian Tu-95 strategic bomber, the concrete shelters built to protect it were still under construction.
Ukraine is not just striking targets. It is putting its adversaries on a relentless clock. 🇺🇦🦩🇷🇺⬇️1/🧵
Ukraine is not just striking targets. It is putting its adversaries on a relentless clock. 🇺🇦🦩🇷🇺⬇️1/🧵
Concrete hardens according to chemistry, not urgency. Russia knew leaving its nuclear-capable bombers in the open was unacceptable, but Ukraine arrived before the slab cured.
That Tu-95 cannot be replaced. The tail was gone; the shelter was still becoming a shelter. 2/
That Tu-95 cannot be replaced. The tail was gone; the shelter was still becoming a shelter. 2/
This speed forces constant adaptation. Ukraine pioneered using light aircraft to launch interceptor drones, and Russia paid the compliment of copying it, bolting interceptors onto trainer planes designed in the Soviet era. 3/

Indian banks are pitching NRIs in the US and Singapore a “risk free” way to multiply FCNR deposit returns.
You put in $1 million. The bank lends you $9 to 19 million more.
One clause in the loan document changes the entire math. A thread.
You put in $1 million. The bank lends you $9 to 19 million more.
One clause in the loan document changes the entire math. A thread.
First, the product.
FCNR deposits are dollar deposits with Indian banks. No currency risk, interest tax free in India.
The leveraged version: you deposit $1 million, borrow up to $19 million from the bank’s overseas or GIFT City branch, and park the whole amount in FCNR.
FCNR deposits are dollar deposits with Indian banks. No currency risk, interest tax free in India.
The leveraged version: you deposit $1 million, borrow up to $19 million from the bank’s overseas or GIFT City branch, and park the whole amount in FCNR.
Why does this work at all?
The deposit pays slightly more than the loan costs. The spread is just 50 to 80 basis points.
Tiny spread, huge leverage. That is the whole trade. Your return gets multiplied 10x to 20x on a wafer thin margin.
The deposit pays slightly more than the loan costs. The spread is just 50 to 80 basis points.
Tiny spread, huge leverage. That is the whole trade. Your return gets multiplied 10x to 20x on a wafer thin margin.

5 high-stakes medical emergencies that start with subtle "warning signs" people brush off.
Ignoring them leads straight to the ER.
The red flags, the hidden diagnoses, and what you MUST do.
1. The "Thunderclap" Headache
Ignoring them leads straight to the ER.
The red flags, the hidden diagnoses, and what you MUST do.
1. The "Thunderclap" Headache
1. The "Thunderclap" Headache
Warning Sign: Sudden, blinding headache hitting peak intensity within seconds.
The Emergency: Subarachnoid Hemorrhage (bleeding in the brain).
What to do: Don't take a painkiller and sleep it off. Get to the ER immediately for a CT scan.
Warning Sign: Sudden, blinding headache hitting peak intensity within seconds.
The Emergency: Subarachnoid Hemorrhage (bleeding in the brain).
What to do: Don't take a painkiller and sleep it off. Get to the ER immediately for a CT scan.
2. Indigestion... in Your Jaw or Arm
Warning Sign: Pressure or burning in your chest, upper stomach, jaw, or left arm after exertion.
The Emergency: Heart Attack (Myocardial Infarction).
What to do: Call emergency services immediately. Chew an aspirin while waiting. Do NOT drive yourself.
Warning Sign: Pressure or burning in your chest, upper stomach, jaw, or left arm after exertion.
The Emergency: Heart Attack (Myocardial Infarction).
What to do: Call emergency services immediately. Chew an aspirin while waiting. Do NOT drive yourself.

Gedanken zur Tageslosung für Dienstag, den 21.07.2026
Losungswort
Freuet euch mit Jerusalem und seid fröhlich über die Stadt, alle, die ihr sie lieb habt! Freuet euch mit ihr, alle, die ihr über sie traurig gewesen seid.
Jesaja 66,10
Lehrtext
Losungswort
Freuet euch mit Jerusalem und seid fröhlich über die Stadt, alle, die ihr sie lieb habt! Freuet euch mit ihr, alle, die ihr über sie traurig gewesen seid.
Jesaja 66,10
Lehrtext
Als Jesus schon nahe am Abhang des Ölbergs war, fing die ganze Menge der Jünger an, mit Freuden Gott zu loben mit lauter Stimme über alle Taten, die sie gesehen hatten. Lukas 19,37
Die Losungen der Herrnhuter Brüdergemeine
Freude statt Trauer
Die Losungen der Herrnhuter Brüdergemeine
Freude statt Trauer
Das heutige Losungswort stammt aus dem letzten Kapitel des Buches Jesaja. Es ist ein Kapitel, in dem einerseits Gottes Gerichtshandeln über alle Völker beschrieben wird, andererseits wird seine tiefe Liebe für seine Kinder sichtbar. So lesen wir: „Ich selbst werde

Ho boy. Philadelphia DA Larry Krasner is at it again. This time, his own office supervisors are whistleblowing on the office's ethical issues. (And yes, before you ask, this is another attempt by Krasner to free a convicted murderer. This time, a double murderer.) Let's dive in!


First, it makes sense why the attorneys here might be on edge. Not that long ago, the 5-2 Democrat Pennsylvania Supreme Court told Krasner to stop trying to free murderers. And he ordered the Attorney General to get involved. One attorney was on that case
The attorneys here both tried to quietly withdraw from the case--they thought they ethically couldn't say more. But now, they are saying more. First, they repeatedly tried to get the office to withdraw due to a conflict of interest.

El cortisol alto es la verdadera razón por la que te despiertas a las 3 o 4 de la mañana.
Además, te quita 5 años de vida: reduce drásticamente la testosterona, acumula grasa abdominal y, literalmente, encoge el cerebro.
Si quisiera solucionarlo sin medicamentos, estas son 8 cosas que haría a diario:
1. No comer 3 horas antes de acostarme.
Además, te quita 5 años de vida: reduce drásticamente la testosterona, acumula grasa abdominal y, literalmente, encoge el cerebro.
Si quisiera solucionarlo sin medicamentos, estas son 8 cosas que haría a diario:
1. No comer 3 horas antes de acostarme.
Comer tarde provoca un pico de azúcar en sangre. La insulina lo elimina durante la noche. Luego, la glucosa cae en picado entre las 2 y las 3 de la madrugada.
Tu cuerpo libera cortisol para intentar solucionarlo.
Eso no es insomnio, es una emergencia metabólica que provocaste a las 9 de la noche con tu último bocado.
Tu cuerpo libera cortisol para intentar solucionarlo.
Eso no es insomnio, es una emergencia metabólica que provocaste a las 9 de la noche con tu último bocado.

2. El desahogo mental de las 9 PM en papel.
La mayoría de los despertares a las 3 AM son decisiones sin resolver que tu sistema nervioso mantiene activas.
Bolígrafo y papel. 90 segundos. Anota todo lo que no hayas terminado.
Externaliza ese bucle o te controlará a las 2 AM.
La mayoría de los despertares a las 3 AM son decisiones sin resolver que tu sistema nervioso mantiene activas.
Bolígrafo y papel. 90 segundos. Anota todo lo que no hayas terminado.
Externaliza ese bucle o te controlará a las 2 AM.


To Whom(Christians) It May Concern:
Be careful considering one's own & other's Sin
If brother/sister is repentant through CHRIST JESUS, having confessed/forsaken their Sin, & we do talebearing & Commandment breaking(false witness), we're doing Satan's work for him.
1/5 🧵👇👆
Be careful considering one's own & other's Sin
If brother/sister is repentant through CHRIST JESUS, having confessed/forsaken their Sin, & we do talebearing & Commandment breaking(false witness), we're doing Satan's work for him.
1/5 🧵👇👆
To Whom(Christians) It May Concern:
If brother/sister is unrepentant & disobeying CHRIST JESUS, either NOT forsaking their Sin or Lying about it, & we follow NOT CHRIST's methodology for ministering to/for them & others, we still may fall into enemy's trappings...
2/5 🧵👇👆
If brother/sister is unrepentant & disobeying CHRIST JESUS, either NOT forsaking their Sin or Lying about it, & we follow NOT CHRIST's methodology for ministering to/for them & others, we still may fall into enemy's trappings...
2/5 🧵👇👆
To Whom(Christians) It May Concern:
If brother/sister is unrepentant or repentant & disobeying or obeying CHRIST JESUS, & we find out about egregious Sin to their account, we must follow Biblical/CHRIST's methodology to deal with them & others about said Sin.
3/5 🧵👇👆
If brother/sister is unrepentant or repentant & disobeying or obeying CHRIST JESUS, & we find out about egregious Sin to their account, we must follow Biblical/CHRIST's methodology to deal with them & others about said Sin.
3/5 🧵👇👆

THREAD
ENGLISH TRANSLATION THREAD The Story of War 2 Interview with Seyyed Abbas Araqchi and Javad Mogoui
Please forgive any errors in translation
Part 1
ENGLISH TRANSLATION THREAD The Story of War 2 Interview with Seyyed Abbas Araqchi and Javad Mogoui
Please forgive any errors in translation
Part 1
Part 2
Part 3

I found something potentially weird. 🧵
1. Belly of the Beast produced Hasan's Cuba doc. BotB is fiscally sponsored by Center for Independent Documentary (CID), meaning CID handles BotB finances & share tax-exempt status.
BotB routes donations via CID in their site footer.
1. Belly of the Beast produced Hasan's Cuba doc. BotB is fiscally sponsored by Center for Independent Documentary (CID), meaning CID handles BotB finances & share tax-exempt status.
BotB routes donations via CID in their site footer.


2. Belly of the Beast's fiscal sponsor, the CID, is a Massachusetts-based nonprofit. So they have to disclose their top donors and grantors.

3. CID's second-largest funder is 'Foundation to Promote Open Society,' created by George Soros. $250,000.
Here's Soros's foundation's stance on Israel, which, to Hasan, qualifies them as demonic, irredeemable Zionists. (I disagree, it seems like a pretty sane take.)
Here's Soros's foundation's stance on Israel, which, to Hasan, qualifies them as demonic, irredeemable Zionists. (I disagree, it seems like a pretty sane take.)


833 shares. Transferred 37 years ago. And today the man running India’s most powerful boardroom has to explain them to a charity commissioner.
The story everyone is reading is wrong. Let me show you the one that matters.
The story everyone is reading is wrong. Let me show you the one that matters.
First, the facts. In January 1989, the Navajbai Ratan Tata Trust transferred 833 Tata Sons shares to Naval H Tata. The transaction was vetted by Nani Palkhivala and approved by the Tata Sons board of that era.
In 2026, a petitioner named Suresh Patilkhede approached the Maharashtra charity commissioner alleging the transfer was an unlawful movement of public charitable trust assets into private hands.

1/8: $IREN just raised its 2026 AI Cloud ARR target from $3.7B to $4B+. ~85% of it is now said to be under contract (was ~70%). Stock closed +19.57% to $40.20 on the news. Here's the falsifiable read on today's 8-K, slide by slide. 🧵⤵️

2/8: Updated ARR bridge: "under contract" jumps to ~$3.4B (85% of target); the CY26 exit target itself raised $3.7B → $4B+. Real revenue today is still ~$134M annualized. This is the number that matters: how much of the bridge is signed vs. still assumed. The assumed slice just shrank from ~$1.8B to ~$0.6B.

3/8: Updated scorecard: the ARR exit run-rate is now $4B+ target / ~$0.6B (~15%) still not contracted, down from ~$1.8B. NVIDIA's $2.1B investment right is ~43% out-of-the-money (was ~52%) as the stock rallied. Guided vs. contracted vs. estimate, and what breaks each claim.


If you think LDL or ApoB has nothing to do with heart disease, you’re wrong.
If you think LDL is the most important risk factor for heart disease and lowering it helps everyone, you’re also wrong.
I know, I just upset everyone. So if you are still reading, thank you for being curious enough to sit with nuance. Let's talk about it. 🧵
If you think LDL is the most important risk factor for heart disease and lowering it helps everyone, you’re also wrong.
I know, I just upset everyone. So if you are still reading, thank you for being curious enough to sit with nuance. Let's talk about it. 🧵
The data here are clear from a statistical standpoint. ApoB particles are part of the atherogenic process. And a damaged or inflamed vascular wall amplifies that role.
Lowering LDL or ApoB (which I will use interchangeably even though they are not exactly), whether through some medications or through genetic variants, reduces the incidence of heart attacks and strokes. That relationship is well established in the general population.
We can, and should, argue about 1- the absolute vs relative risk/benefit, 2- mortality versus event reduction, 3- why all meds don’t have the same impact, 4- how this plays out differently in metabolically healthy versus unhealthy populations, and other important specifics.
Those details shape the discussion in clinically meaningful ways that are often ignored.
But in the general population, lowering ApoB reduces cardiovascular events, with greater absolute benefit in those at higher baseline risk or with prior cardiac events.
Lowering LDL or ApoB (which I will use interchangeably even though they are not exactly), whether through some medications or through genetic variants, reduces the incidence of heart attacks and strokes. That relationship is well established in the general population.
We can, and should, argue about 1- the absolute vs relative risk/benefit, 2- mortality versus event reduction, 3- why all meds don’t have the same impact, 4- how this plays out differently in metabolically healthy versus unhealthy populations, and other important specifics.
Those details shape the discussion in clinically meaningful ways that are often ignored.
But in the general population, lowering ApoB reduces cardiovascular events, with greater absolute benefit in those at higher baseline risk or with prior cardiac events.
But the data are equally clear that poor metabolic health, like insulin resistance and type 2 diabetes, carry very high relative risks for coronary disease, often higher than for LDL exposure alone. Thus the “CAD equivalent” designation for DM2 in young people. The same increased risk also applies to visceral adiposity and chronic inflammation.
That doesn’t make LDL and ApoB “useless.” But I think it helps us evaluate the emphasis we place on addressing the most important risk factors.
That doesn’t make LDL and ApoB “useless.” But I think it helps us evaluate the emphasis we place on addressing the most important risk factors.

🚨BREAKING NEWS: Most people are sleeping on Claude for stock trading.
Here are 10 powerful Claude prompts for stock analysis, buying, selling, and smarter investing decisions.
Bookmark this 🔖- it may come in useful sooner than you think.
Here are 10 powerful Claude prompts for stock analysis, buying, selling, and smarter investing decisions.
Bookmark this 🔖- it may come in useful sooner than you think.

1. Stock Research Prompt
Act like a professional stock market analyst. Analyze [COMPANY NAME / TICKER] as a possible investment. Break down its business model, main revenue sources, competitive advantages, major risks, recent performance, debt level, profitability, and future growth potential. Explain everything in beginner-friendly language. At the end, give me a simple summary: Bull Case, Bear Case, and Neutral View.
Act like a professional stock market analyst. Analyze [COMPANY NAME / TICKER] as a possible investment. Break down its business model, main revenue sources, competitive advantages, major risks, recent performance, debt level, profitability, and future growth potential. Explain everything in beginner-friendly language. At the end, give me a simple summary: Bull Case, Bear Case, and Neutral View.
2. Buy Decision Prompt
I am considering buying [TICKER] at around [$PRICE]. My investment time horizon is [short-term / 6 months / 1 year / 5 years]and my risk tolerance is [low / medium / high]. Analyze whether this stock looks attractive at the current price. Consider valuation, earnings growth, industry trends, recent news, analyst sentiment, and possible downside risk. Give me a clear “buy now, wait, or avoid” style conclusion, but explain the reasoning carefully.
I am considering buying [TICKER] at around [$PRICE]. My investment time horizon is [short-term / 6 months / 1 year / 5 years]and my risk tolerance is [low / medium / high]. Analyze whether this stock looks attractive at the current price. Consider valuation, earnings growth, industry trends, recent news, analyst sentiment, and possible downside risk. Give me a clear “buy now, wait, or avoid” style conclusion, but explain the reasoning carefully.