,
19 tweets,
7 min read
Read on Twitter
AOC is more right than wrong, but it's not because algorithms are made by biased humans. For example, racial disparities in criminal conviction rates make it provably mathematically impossible to eliminate disparities in sentencing algs. See @tnajournal:
thenewatlantis.com/publications/a…
thenewatlantis.com/publications/a…
Algo racism is an input, not a code, issue. Or in human terms: it's a rare case where you can mathematically prove the folly of reposing hope in software to cure entrenched social ills.
Again, read Tafari Mbadiwe's supremely insightful @tnajournal essay: thenewatlantis.com/publications/a…
Again, read Tafari Mbadiwe's supremely insightful @tnajournal essay: thenewatlantis.com/publications/a…
Example: That blockbuster ProPublica investigation damningly found that false positive rates for the COMPAS sentencing algorithm were twice as high for black defendants as white. propublica.org/article/machin… 

(The context here is that these algorithms are used during criminal sentencing to determine how likely an offender is to re-offend in the next few years.)
ProPublica found that among the people who DIDN'T go on to re-offend, those who had been mistakenly labeled "high-risk" by the algorithm were twice as likely to be black as white. Here's how we illustrated that:

Those labeled "high-risk" were (at least anecdotally) more likely to have judges deny them things like pretrial release, parole, probation, and — possibly — shorter sentences. So getting this label based on a mistaken algo assessment that you're likely to reoffend is a big deal.
Here's the problem: There's another way of defining this disparity in sentencing mistakes, which is the share of people labeled "high-risk" who DON'T go on to re-offend. That's the false discovery rate. It sounds conceptually the same as the false positive rate, but it's not.
And in fact the COMPAS algorithm produced (nearly) racially equal false discovery rates -- because its programmers designed it to be fair under this metric:

So you have two ways of thinking about and defining mistaken harshness -- labeling someone "high-risk" when they're actually not going to re-offend. Which of these two definitions sounds like the correct one? I don't know either. It's hard to keep them straight.

And in fact @ProPublica confused this in their article. The numbers in this table are wrong. The first row describes the false discovery rate (not false positive), so the numbers should be 41 white / 37 black. Second row: false omission rate, 29 / 35. Roughly similar for both.

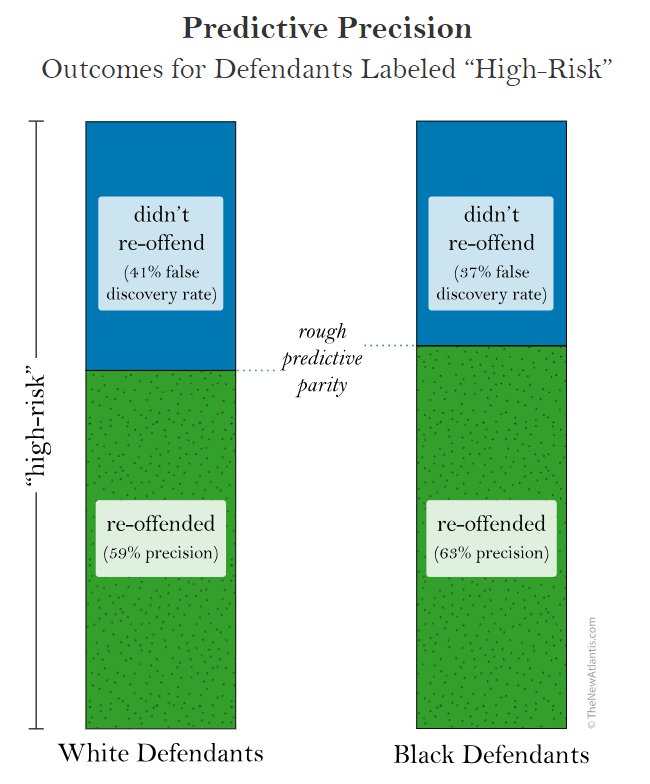
You can find this in their more detailed breakdown. False discovery rate = 1 - positive predictive value, false negative rate = 1 - negative predictive value. Of course, the @ProPublica numbers would be correct if they just swapped the order of the labels.
propublica.org/article/how-we…
propublica.org/article/how-we…
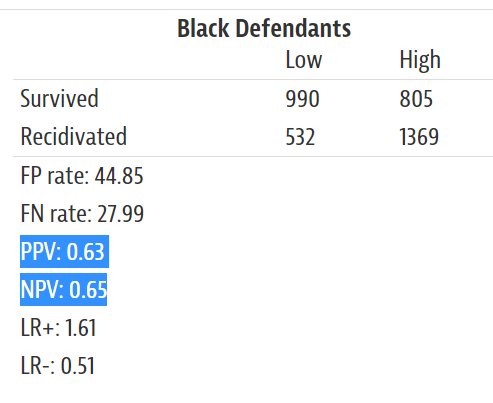
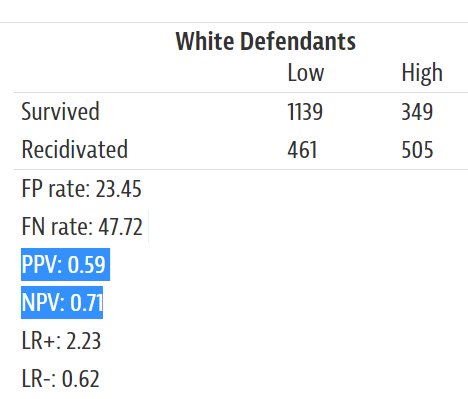
Here's the comprehensive graph we made to illustrate all of this at once -- how these different kinds of error arise out of a process of assigning risk out of the overall pool of defendants:
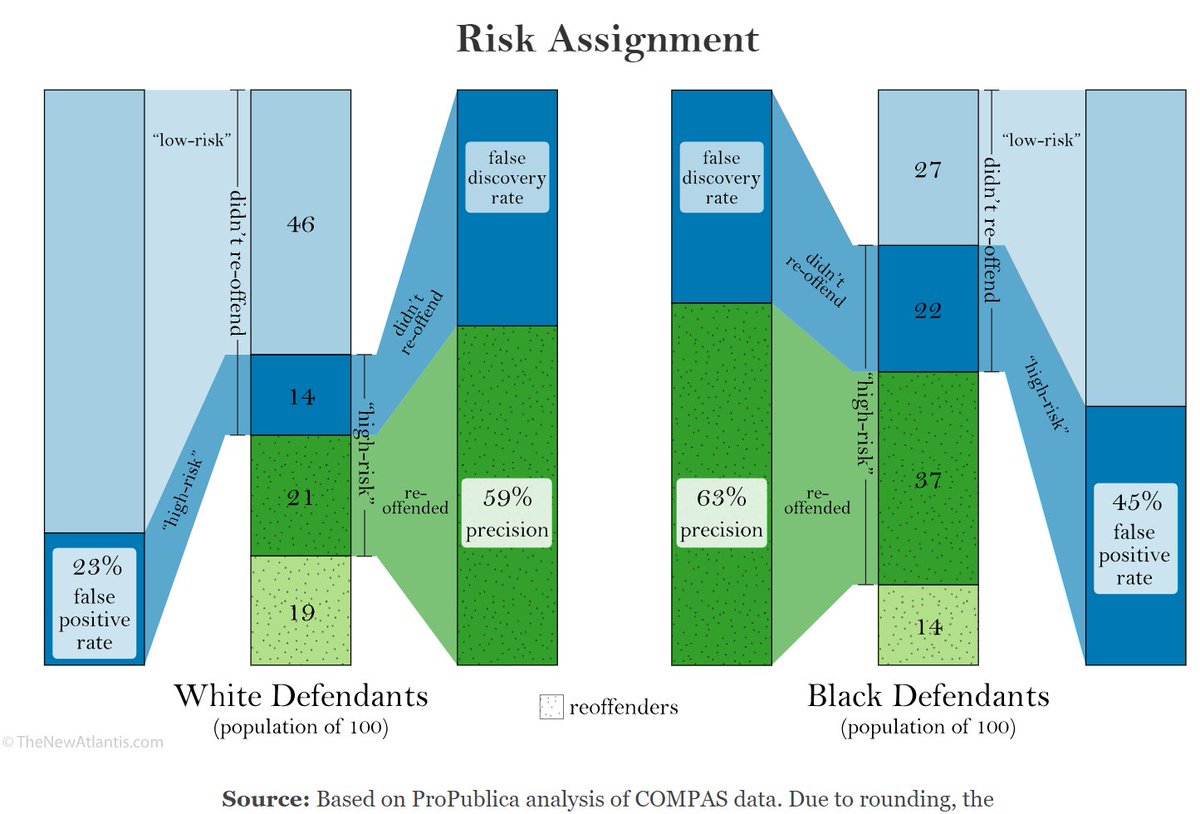
Mbadiwe even went so far as to ask: What would happen if you tried to fix the algorithm to eliminate the disparities highlighted by ProPublica? The answer: you'd introduce disparities under these other definitions:

If you try to make the algorithm mistakenly harsh toward the races at equal rates by one definition, it'll become unequal by another definition -- or now become mistakenly lenient at unequal rates. It's a whack-a-mole game that can't be won.
Working with the author, we put enormous care into trying to help clarify this issue. I would encourage anyone interested to read this as a primer for how easily statistical confusion can lead people in good faith to talk past each other on this: thenewatlantis.com/publications/a…
I could go on. It's a fascinating technical problem, really. And an obvious conclusion is that we urgently need clear public reasoning where technical and moral questions meet — in this case, to decide which statistical terms match our intuitive definition of justice.
...that's the Reasonable Public Policy response to this mess, anyway. I confess I came away from working on this piece deeply skeptical of it.
Because even if you can get philosophers, lawyers, and mathematicians to reach a consensus about what fairness means (jokes for days!)... Will that answer ever be clear and satisfying to defendants, their families, victims, the public? Will they all read through these tables?
I came away fascinated by the technical questions about criminal sentencing algorithms — and convinced we should get rid of them, that justice without judgment is not a step toward fairness but away from moral responsibility.
End thread — but read Tafari: thenewatlantis.com/publications/a…
End thread — but read Tafari: thenewatlantis.com/publications/a…