
,
58 tweets,
8 min read
Read on Twitter
Comme je l'expliquais dans le thread de présentation du projet de recherche, ma thèse se concentre sur une petite partie du problème.
À savoir, transformer une description de position (ex. "je suis sur un chemin et je vois le mont-blanc") en une coordonnée.
ou, pour le dire de façon plus correcte, je cherche à passer d'une position exprimée dans un référentiel indirect (la description) à une position exprimée dans un référentiel direct (les coordonnées).
ça c'est pour la présentation théorique, dans les faits l'objectif n'est pas d'identifier un seul point mais plutôt de construire une zone qui contient la position de la victime.
Mais comment faire ? La première étape consiste à identifier ce que j'appelle des "éléments de localisation".
Les éléments de localisation sont des groupes de mots porteurs d'une information de localisation.
Lorsque qu'une personne décrit sa position elle en donne généralement plusieurs.
Par exemple, si je dis : "Je suis assis à mon bureau, devant mon ordinateur et face à la fenêtre", je donne trois éléments de localisation :
1. "Je suis assis à mon bureau"
2. "[Je] suis devant mon ordinateur"
3. "[Je suis] face à la fenêtre"
1. "Je suis assis à mon bureau"
2. "[Je] suis devant mon ordinateur"
3. "[Je suis] face à la fenêtre"
Chaque élément de localisation sera modélisé indépendamment et différemment.
Une fois que tous les éléments de localisation ont étés modélisés, on peut les combiner pour obtenir une zone, celle où se situe la victime.
Par exemple, ici la position de la victime est représentée par un point (V) et les zones modélisant deux éléments de localisation (E1 et E2) par des polygones. L'intersection de ces deux zones contient V 

Mais il s'agit d'un cas idéal, parfois l'intersection des zones modélisant des éléments de localisation est nulle.
Ce peut être car la victime s'est trompée dans sa description, ou à cause d'une mauvaise calibration de algorithme de spatialisation.
C'est pour cette raison que j'ai adopté une modélisation indépendante des éléments de localisation.
Au tout début de ma thèse j'avais adopté une approche plus naïve, qui ne faisait pas la distinction entre spatialisation des éléments de localisation et leur intersection.
Pour illustrer tout ça je vais reprendre mon exemple précédent :
1. "Je suis assis à mon bureau"
2. "[Je] suis devant mon ordinateur"
3. "[Je suis] face à la fenêtre"
1. "Je suis assis à mon bureau"
2. "[Je] suis devant mon ordinateur"
3. "[Je suis] face à la fenêtre"
En première approche aurait été de modéliser une zone correspondant à l'élément de localisation 1, puis de la réduire en retirant toutes les positions n'appartenant pas aux zones 2 et 3.
Sauf que cette approche est très vulnérable aux erreurs. Si je me trompe en modélisant la zone 1, le résultat des zones 2 et 3 sera impacté, puisque dépendant de l'opération précédente.
La solution retenue a donc été de modéliser les zones 1, 2 et 3 indépendamment, puis de les combiner. Ainsi si une des modélisations est fausse, il est possible de la retirer ou de la modifier sans impacter les autres.
Voila pour la présentation générale de la démarche. Elle se résume en deux étapes :
1. Modéliser les zones correspondant à chaque élément de localisation
2. Combiner les zones entre-elles.
1. Modéliser les zones correspondant à chaque élément de localisation
2. Combiner les zones entre-elles.
Jusqu'ici j'ai présenté le processus de modélisation comme un tout, mais en réalité la démarche varie constamment.
Pour l'illustrer je vais présenter deux modélisations distinctes.
Je vais commencer par expliquer comment on modélise l'élément de localisation "j'ai marché plusieurs heures sur un chemin à partir de Bourg d'Oisans ".
C'est un élément de localisation qui est extrait d'un cas réel.

Dans ce cas on a deux informations :
1. Le point de départ
2. Une durée
1. Le point de départ
2. Une durée
On peut donc envisager la création d'isochrones. C'est à dire de lignes reliant tous les points atteignables en une même durée. Ce qui permet de réaliser ce genre de cartes.

C'est un calcul qui peu être lourd, mais qui n'est pas difficile à mettre en place.
Le calcul est basé sur ce que l'on appelle un algorithme de pathfinding. L'objectif de cette famille d'algorithmes est de trouver le chemin le plus court entre deux points.
Le plus connu est l'algorithme de Dijkstra, mais il en existe d'autres, bien illustrés par cette vidéo.
L’algorithme de Dijkstra est utilisé, par exemple, par les applications de planification d'itinéraire, comme celle du site ratp.fr, ou de votre gps.
En utilisant ce type d’algorithme plusieurs fois on peut déterminer la distance minimale pour atteindre tous les points du réseau à partir d'un même endroit.
Mais encore faut-il avoir un réseau à traiter.
Pour ça il faut disposer d'une base de données géographiques décrivant la voirie.
Par exemple, voici la voirie issue de la base de données BDTopo de l'Ign pour la région de Grenoble

Chaque segment visible est décrit par un ensemble de données, comme la largeur de la route, son nom ou encore son altitude minimale et maximale.
Cette base doit ensuite être transformée en un graphe, ce qui revient à résumer toutes les routes à leurs points initiaux et finaux.

Ce qui compte ce n'est pas la forme des routes, mais les connections entre routes.
Ensuite il faut attribuer à chaque arête du graph un coût. Ce peut être une durée, une distance ou autre.
L'algorithme de pathfinding cherchera à minimiser la valeur cumulée de ces coûts.
Cette carte, par exemple, a été construite à l'aide de cette méthode. L'objectif était de reconstituer des trajets maritimes plausibles alors que seul le point de départ est d'arrivée des navires étaient connus.

Pour la carte ci-dessus, c'est la longueur de chaque arête qui a été choisie comme coût. L’algorithme a donc renvoyé le chemin le plus court entre deux ports.
Mais parfois il est nécessaire d'utiliser un modèle de coût plus sophistiqué.
Par exemple lorsque l'on utilise un GPS en voiture on cherche souvent le trajet le plus rapide (en temps) et non le plus court (en distance).
Il faut alors estimer la durée de parcours de chaque arc du réseau. En première approximation on peut considérer qu'on roule à la vitesse maximale autorisée. Mais on peut également raffiner ce modèle de coût, en faisant l'hypothèse qu'on roule rarement à pleine vitesse.
Sauf que je travaille sur des personnes blessées ou perdues en montagne, et par conséquent le modèle de coût est assez différent de ce que l'on pourrait utiliser pour modéliser le trafic routier.
Déjà il n'y a pas de limite de vitesse, on ne peut donc pas faire une première approximation basée sur cette information.
Ensuite, l'effet de la dénivellation est très important.
Et enfin, la différence de niveau entre randonneurs joue également beaucoup.
Mais il existe quelques modèles de coût pour la marche en montagne. Par exemple les panneaux de signalisation que l'on peut trouver en montagne donnent une durée de marche approximative, qui a été calculée a l'aide d'un modèle de coût (qui peut être empirique)

Mais surtout il y a le modèle de Naismith qui a été proposé en 1892 et qui malgré son âge et sa simplicité et toujours utilisé.

D'autres modèles ont étés proposés par la suite. La page wikipédia du modèle de Naismith (d'où provient l'image) en donne un bon aperçu
en.wikipedia.org/wiki/Naismith%…
en.wikipedia.org/wiki/Naismith%…
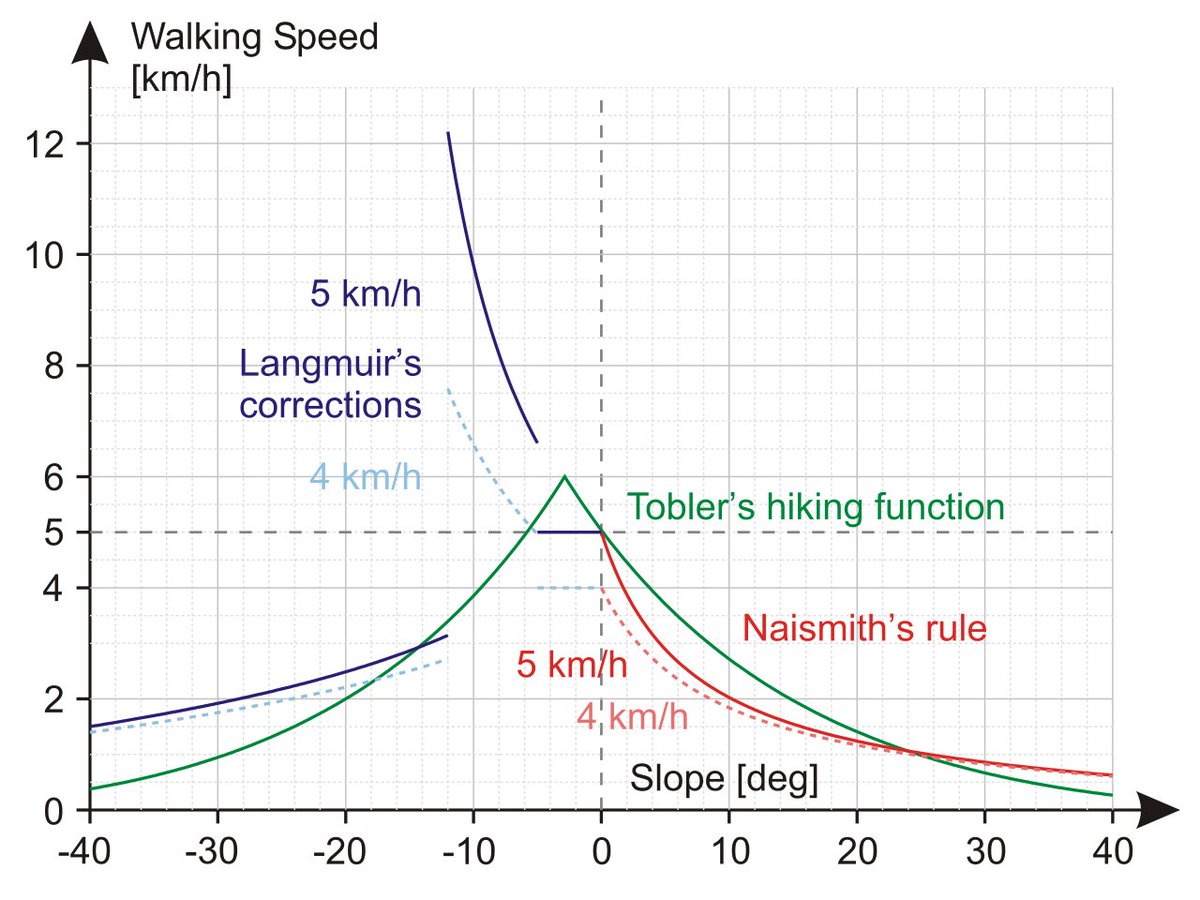
Un fois qu'on a un graph représentant la voirie (+ sentiers) et un modèle de coût adapté à la randonnée en montagne on peut attaquer la modélisation du problème.
Voila ce que peut donner le calcul d'isochrones à l'aide d'un modèle de coût adapté à la marche en montagne (la carte est pas top, mais j'ai rien d'autre sous la main).

Avec tout ça on devrait arriver à modéliser notre exemple de tout à l'heure:
"j'ai marché plusieurs heures sur un chemin à partir de Bourg d'Oisans "
"j'ai marché plusieurs heures sur un chemin à partir de Bourg d'Oisans "
Et ben pas vraiment, où alors d'une façon qui n'est pas très satisfaisante.
Déjà on n'a pas d'informations sur le niveau physique du randonneur, donc sur sa vitesse de marche et par conséquent sur la distance qu'il a pu parcourir.
Ensuite il précise qu'il a marché "plusieurs heures", ce qui est très imprécis et du coup on ne peut pas se contenter de prendre une durée au hasard.
et des informations imprécises comme celle-ci il y en a partout dans les éléments de localisation. La prise en compte des imprécisions est un aspect important de ma thèse (c'est le "raisonnement spatial flou" du titre).









