
,
10 tweets,
7 min read
Read on Twitter
OK. I promised a thread about the paper and promises must be kept.
Let's use this thread to talk about #DNAdatastorage in general and finish up with our work and some thoughts about the future of the field.
1/10
Let's use this thread to talk about #DNAdatastorage in general and finish up with our work and some thoughts about the future of the field.
1/10
Why use DNA to store data?
As the burden of the #BigData era on data storage infrastructure is becoming too heavy we need to explore alternatives.
DNA was optimized as an information carrier by billions of years of evolution. It's dense, stable, and energetically efficient.
2/10
As the burden of the #BigData era on data storage infrastructure is becoming too heavy we need to explore alternatives.
DNA was optimized as an information carrier by billions of years of evolution. It's dense, stable, and energetically efficient.
2/10
Back in 2012 we saw two important studies demonstrating MB scale data storage on synthetic DNA. @geochurch was the first with an elegant straight forward approach. @Nick_Goldman followed with a more robust encoding.
Since, others has shown encoding/technological improvements
3/10
Since, others has shown encoding/technological improvements
3/10
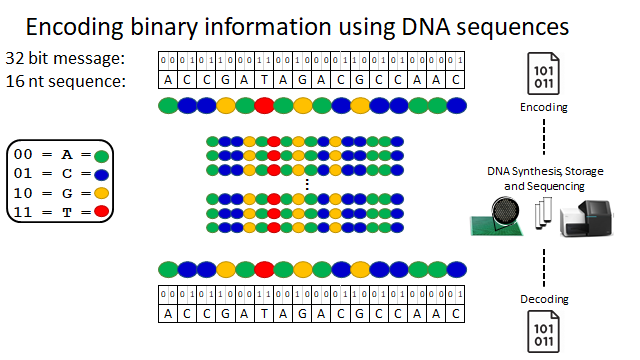
The idea is to translate a binary message into a sequence of As, Cs, Gs and Ts. Then use #DNAsynthesis to get DNA molecules of that sequence, store them in the fridge, #DNAsequencing them and decode the original message. Excellent review by @luisceze rdcu.be/bRzQu
4/10
4/10
DNA synthesis is the most challenging step in this process. It's slow (~day for writing 10MB), very limited in the length of the synthetic DNA molecules (~200 letters in every molecule) and very expensive (~10K$ for writing 10MB).
This is where our work comes in.
5/10
This is where our work comes in.
5/10
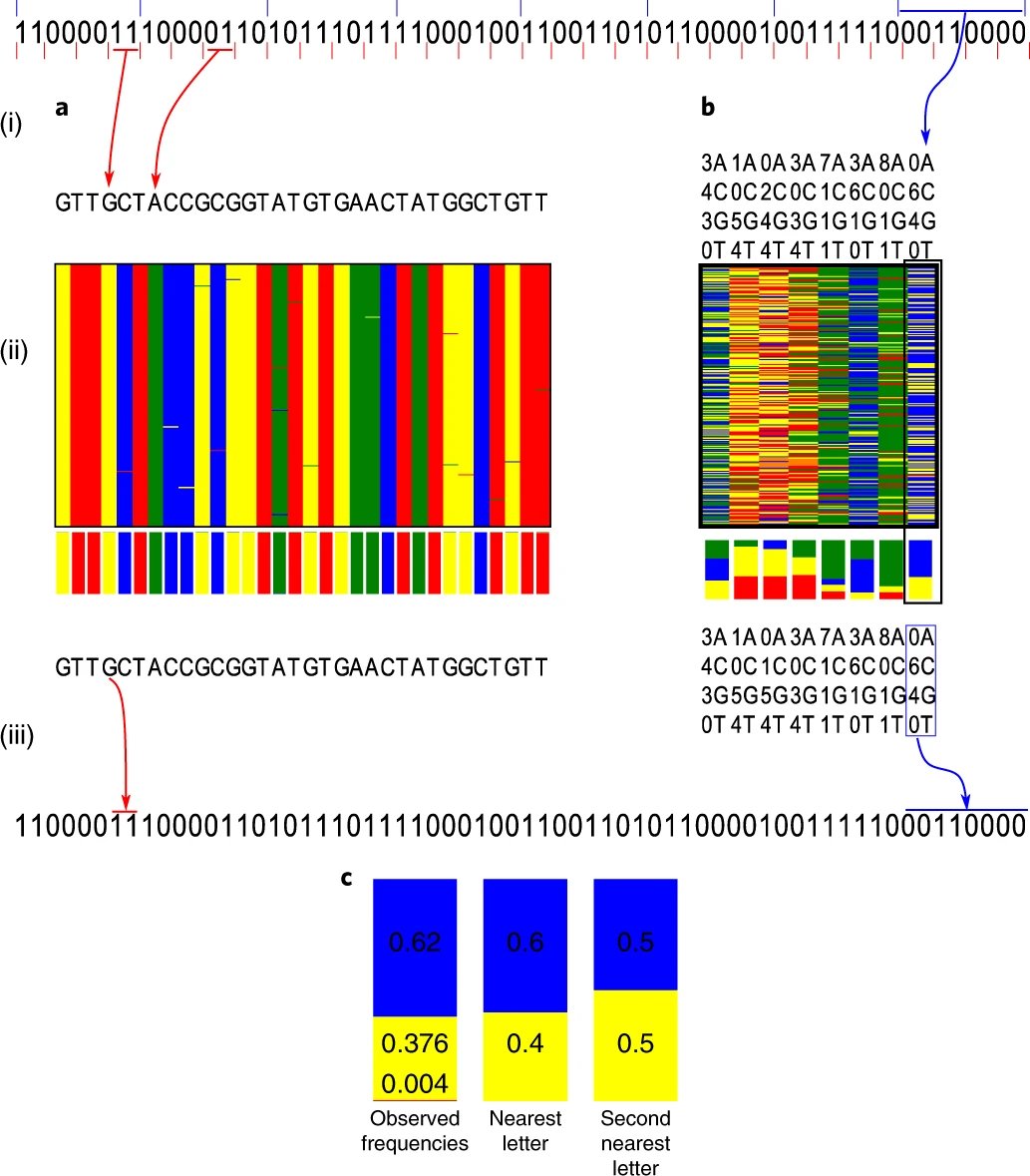
DNA synthesis has inherent redundancy. Every seq is synthesized many time. We trade this redundancy for complexity to generate "new letters".
A composite letter is a mix of the original DNA letters in a position of the seq. example: 1 to 1 ratio of A and C is called M.
6/10
A composite letter is a mix of the original DNA letters in a position of the seq. example: 1 to 1 ratio of A and C is called M.
6/10
Synthesis of M is by mixing As and Cs at the correct step of synthesis. the result is a set of molecules that in that position 50% will contain A and the rest will have C. This can be inferred from sequencing if you sequence enough copies.
7/10
7/10
The additional letters allow for encoding the same binary message using a shorter sequence which means less synthesis cycles. We showed how adding only 2 extra letters saves ~20% of the required synthesis. We did this using the same message and encoding scheme as @erlichya.
8/10
8/10
What's next in @DNAdatastorage
- Using native DNA biorxiv.org/content/10.110…
- More random access
nature.com/articles/nbt.4…
- Enzymatic synthesis
nature.com/articles/nbt.4…
nature.com/articles/s4146…
- Fast reading using nanpore
nature.com/articles/s4146…
and many other open questions
9/10
- Using native DNA biorxiv.org/content/10.110…
- More random access
nature.com/articles/nbt.4…
- Enzymatic synthesis
nature.com/articles/nbt.4…
nature.com/articles/s4146…
- Fast reading using nanpore
nature.com/articles/s4146…
and many other open questions
9/10
I should remember to thank @R_Amit_Lab for a great collaboration. @TwistBioscience for an amazing synthesis work. Many others in @TechnionLive and @IDCHerzliya for great discussions. And @NatureBiotech for a very thorough and thoughtful review process.
10/10
10/10








