,
19 tweets,
10 min read
Read on Twitter
Single-Cell RNA-seq data is notoriously noisy. There are dozens of methods for cleaning it, but how do you know when they’re working right?
How clean is too clean?
Presenting...Molecular Cross-Validation
biorxiv.org/content/10.110…
How clean is too clean?
Presenting...Molecular Cross-Validation
biorxiv.org/content/10.110…
Where does the noise come from? If a cell has 500k molecules and a droplet experiment nets you 5k, then you’re looking at just 1% of what was there. Lots of lowly-expressed genes will be missing by chance (the phenom formerly known as "dropout"). 

Luckily you can get a lot of cells now. Hundreds of thousands. Millions. Some of them are doing similar things to each other.
If you could somehow combine the individual sketchy pictures in the right way, you might learn better what each cell was doing.
If you could somehow combine the individual sketchy pictures in the right way, you might learn better what each cell was doing.

At one extreme, you average all the cells. This is called bulk sequencing, and there are cheaper ways to do it.
Instead, you can average each cell with the most similar cells from the same dataset. This is the core of graph-diffusion methods like MAGIC.
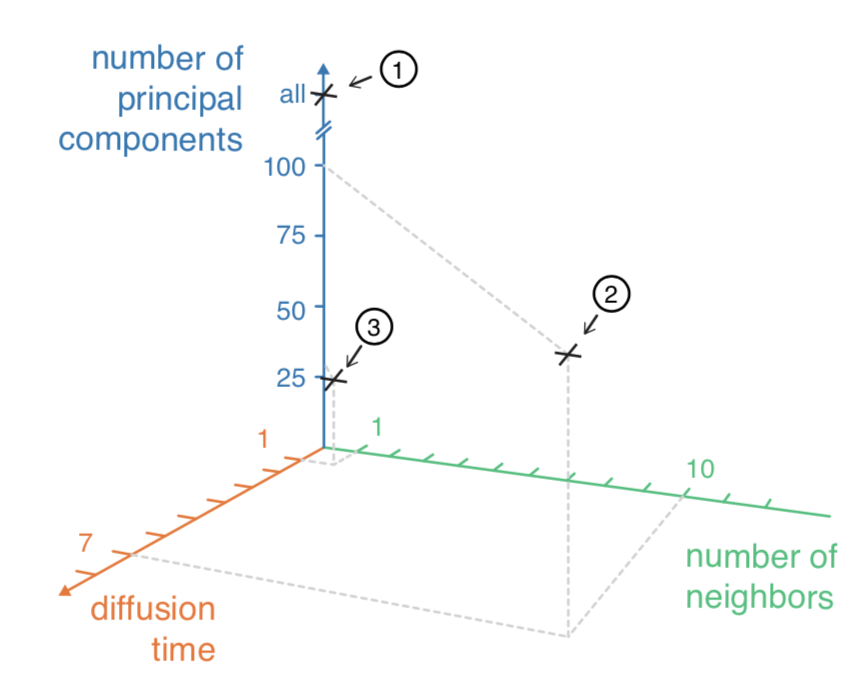
How big do you make the neighborhood? How long do you diffuse?
How big do you make the neighborhood? How long do you diffuse?
Principal Components Analysis is also a kind of denoiser. (h/t @satijalab). When you take your cells in 20k-dimensional gene space and project down to say 20 PCs, you keep common directions of variation and throw out the cruft.
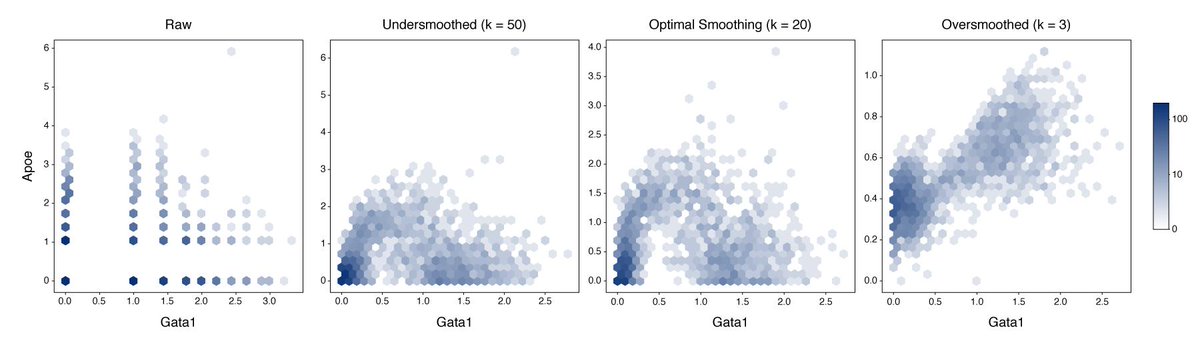
But why 20 PCs? Why not 3? Or 50?
But why 20 PCs? Why not 3? Or 50?
@satijalab Gene expression is a complex, hierarchical process. Should we use…DeEp LeArNiNg? (e.g. DCA, scVI.)
Parameters matter here, and it’s hard to tell how tweaking things like learning rate, bottleneck width, or the random seed will affect the data.
Parameters matter here, and it’s hard to tell how tweaking things like learning rate, bottleneck width, or the random seed will affect the data.

@satijalab So! We need a way to tell when a denoiser is helping, and to stop it before all the diversity and heterogeneity between cells gets smooshed away (*single* cell* sequencing, right?).
@satijalab We call our approach “molecular cross-validation” (MCV).
In classic cross-validation, you would split the cells into two groups, fit the model on the first group (training), and evaluate its accuracy on the second group (validation).
In classic cross-validation, you would split the cells into two groups, fit the model on the first group (training), and evaluate its accuracy on the second group (validation).
@satijalab In MCV, we split the *molecules* from each cell into two groups.
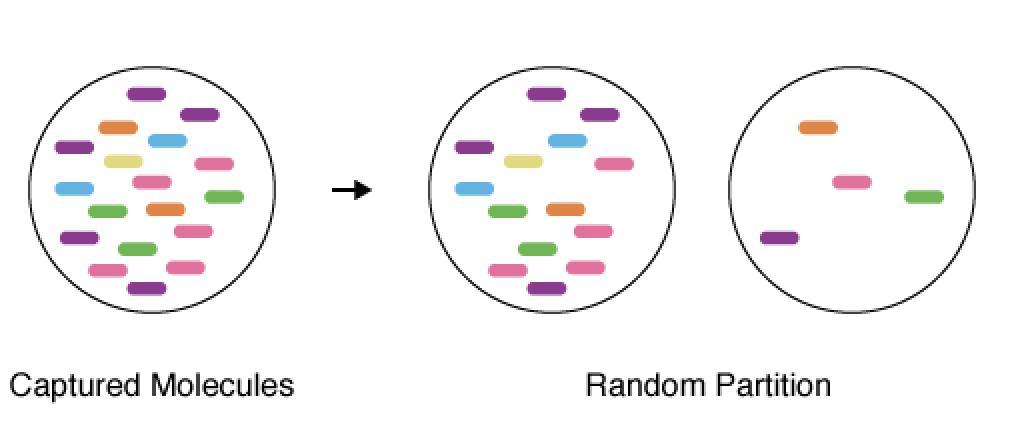
@satijalab We fit the model on the first group (training) and compare the denoised output to the second group (validation).
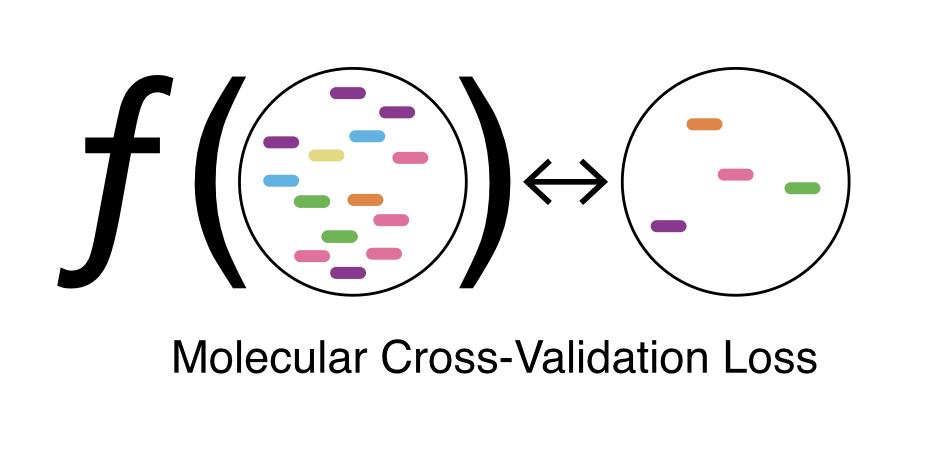
@satijalab We prove that the MCV loss is equal to the ground-truth loss, the one you would get by comparing to all the RNA in the original cell (caveat: up to a constant, in expectation).
The proof is 8 lines; check out the methods section if you’re interested.
The proof is 8 lines; check out the methods section if you’re interested.

@satijalab This means that the model minimizing the MCV loss (which you have) is the model minimizing the ground-truth loss (which you want).
MCV lets you calibrate any model (we do PCA, diffusion, and a deep autoencoder), and pick the best one for your dataset.
MCV lets you calibrate any model (we do PCA, diffusion, and a deep autoencoder), and pick the best one for your dataset.
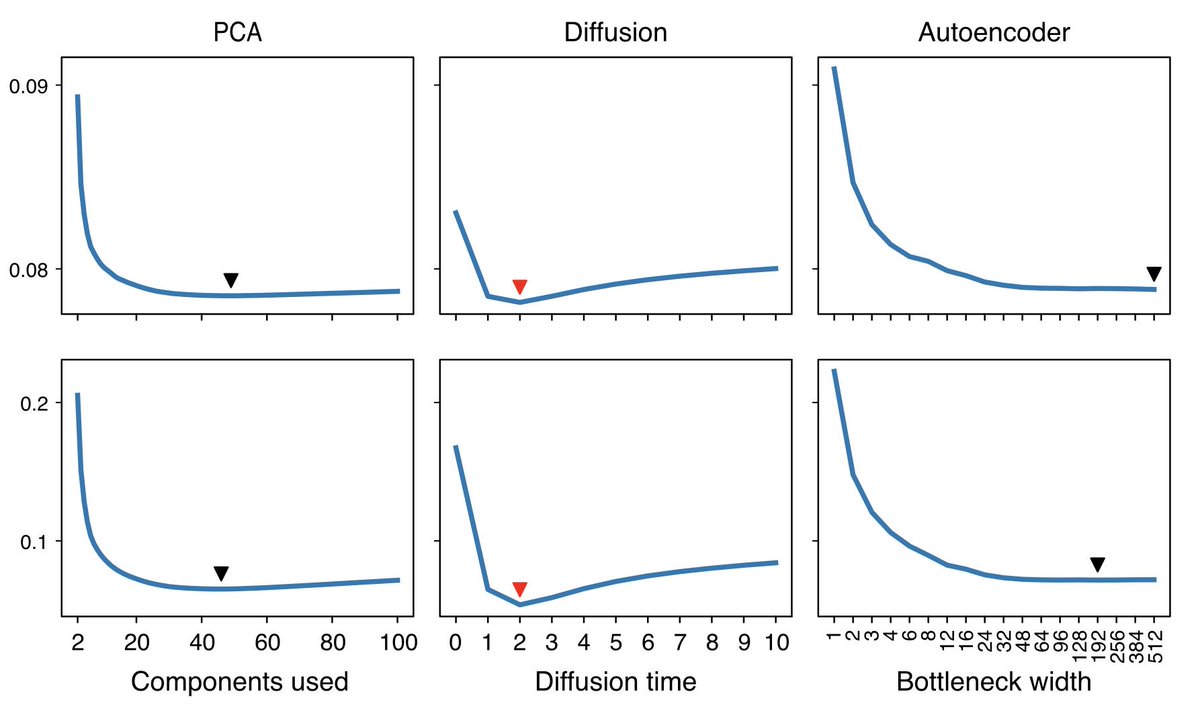
@satijalab Sometimes a fancy model like a deep autoencoder does worse than a simple model like PCA if you’re not very careful with all the knobs. With MCV, you can compare the shiny new thing to a simple baseline.
@satijalab MCV can also be used to calibrate a model with many parameters like MAGIC.
@satijalab In general, we found that the figures which look most pleasing to the eye are oversmoothed. Reality is more heterogeneous than the stories we tell about it.
@satijalab If you’re considering denoising single-cell data, we invite you to use molecular cross-validation to choose the best model for your data.
If you make software which does denoising, we’d love to get MCV inside of it. Looking at you @satijalab, @theislab.
If you make software which does denoising, we’d love to get MCV inside of it. Looking at you @satijalab, @theislab.
@satijalab @THeislab Finally, thanks to @james_t_webber and @loicaroyer for being great collaborators on this project.
It was fun to see this story fill out and mature from the sketch in #Noise2Self, seeing how far the pixel:molecule analogy could take us.
arxiv.org/abs/1901.11365
It was fun to see this story fill out and mature from the sketch in #Noise2Self, seeing how far the pixel:molecule analogy could take us.
arxiv.org/abs/1901.11365