
Talking about #compositionality opens a giant can of worms. One worm: what is it that we compose and where does it come from? What is it that does composition, and where does it come from? I've tried to put some thoughts together on #innateness. /1
This thread has three parts: a) how some approaches to compositionality deal with innateness; b) why we should think about innateness in relation to computational models; c) why we should think about innateness in relation to data. /2
PART 1 - HISTORY. I previously mentioned that different approaches to composition have different relations to innateness. Let's get back to some obvious protagonists -- Chomsky, Katz & Fodor... And let's start with a turning point in the historical debate on innateness... /3
In 1959, Chomsky writes a damning review of Skinner's book 'Verbal behaviour' (1957). Skinner is an #empiricist who believes that knowing one's language involves having a set of verbal dispositions (saying things in response to stimuli) which are acquired by conditioning. /4
Chomsky makes several arguments against Skinner, including the poverty of the stimulus, and the fact that "composition and production of an utterance is not simply a matter of stringing together a sequence of responses under the control of outside stimulation". /5
Instead, Chomsky proposes the #rationalist notion of a universal grammar (UG), which all speakers are born with. A UG is a set of constraints which must be specialised for the particular language the speaker acquires, using the particular performance data they're exposed to. /6
Katz & Fodor (1963), porting Chomsky to semantics, don't actually commit to a story about how acquisition happens: "(by conditioning? by the exploitation of innate mechanisms? by some combination of innate endowment and learning?)" (ft 3). But they later make separate claims. /7
Katz (w/ Chomsky): #empiricists & #rationalists need innateness. But for empiricists, it is (just) "a machinery for instituting associative bonds"; for rationalists, it imposes "severe restrictions on what a simple idea can be and in what ways simple ideas can combine" (1975) /8
Fodor himself will end up being the representative of an extreme stance on innateness and concepts, claiming in 'The Language of Thought' (1975) that all lexical concepts are innate and are simply 'triggered' by performance data. /9
(No need to say, some people get upset at the idea that one might be born with the concept of wi-fi, or for that matter with the concept of that fantastic teleportation device that is yet to be invented.) /10
How about other approaches? E.g. Fillmore (1985) doesn't commit, suggesting that in frame semantics, some frames are innate (e.g. shape of faces), others acquired (social institutions), others completely dependent on the linguistic system of a language (units of measurement). /11
And logicians? Well, they don't care. In Montague, the meaning of life is life prime, its extension in some world. The intension of life is a function from possible worlds to extensions. Which begs the question: how do we get to have possible worlds in our linguistic system? /12
PART 2 - MODELS. Now, when modelling, we implicitly commit to different notions of innateness. If we use models for the purpose of studying language, we should be clear on what they actually learn, and what was already there. How, for instance, might one do acquisition in UG? /13
One approach is called Optimality Theory (OT). OT has links to connectionist models and claims that UG gets tuned to a language via a process of 'optimisation' (Alan Prince & Paul Smolenski: "Optimality: From Neural Networks to Universal Grammar" (1997). /14
But perhaps we'd like to be truth-theoretic. Combining script-like regularities à la Fillmore, and formal semantics à la Montague, Rational Speech Act theory lets you sample worlds with Bayesian models (Goodman & Frank, 2016), solving the question: "where do worlds come from?"/15
The point is that the model we choose commits us to some theoretical priors. Just as #empiricists need innate behavioural responses (see Chomsky & Katz argument), NNs require a lot of hard-coding: architecture, shape of input, hyperparameters, etc. /16
Take a trendy model like BERT. It makes huge assumptions in terms of architecture and underlying theories, favouring linguistic principles such as extreme contextualism and cognitive principles such as attention (vs incrementality). It also has a very particular shape. /17
In fact, @annargrs and colleagues have shown that BERT works rather well even without pre-training, implying that structure might be playing a huge role in the results (Kovaleva et al 2019). /18
Another striking example relates to learning the meaning of quantifiers in a neural model (@IonutSorodoc, @sandropezzelle, yours truly and others, 2018). Below is the architecture that worked best in our experiments. Linguists, what does it look like to you? /19 
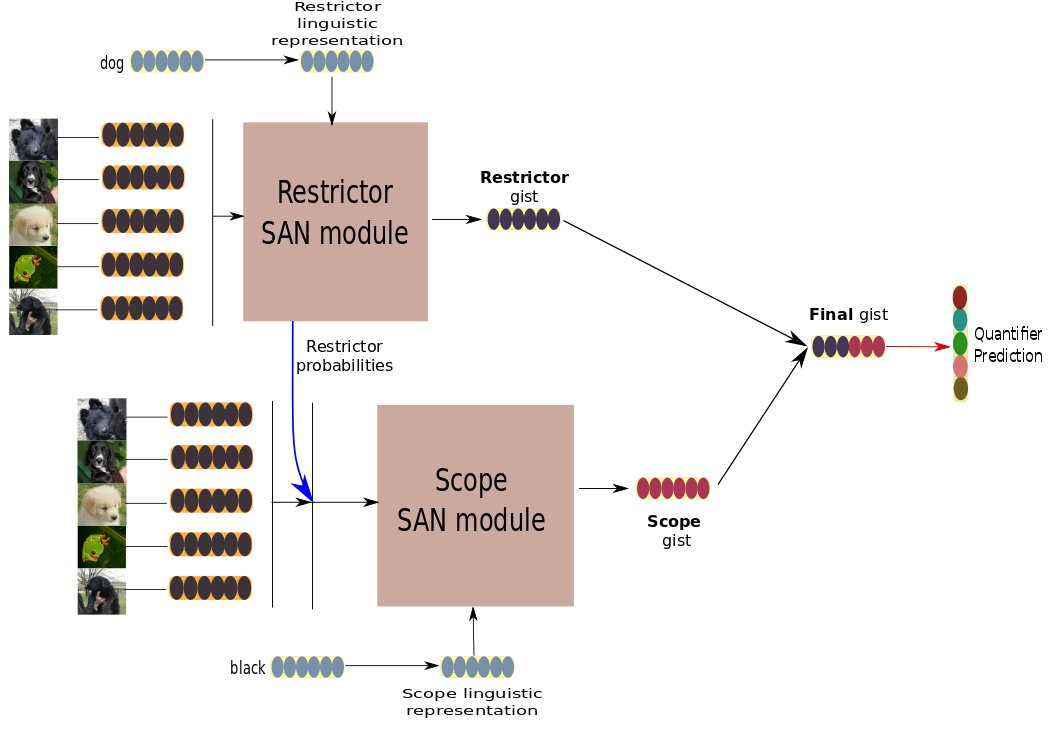
That's right, <<e,t>,<<e,t>,t>>. A determiner with a restrictor and a scope, giving truth values. Morale of the story: we must assume some innate structure for this particular network. When that structure takes the shape of a particular formal semantics type, we learn better. /20
How about Bayesian approaches? We must now explain where priors come from, as well as the event space itself. Computing the probability of X requires having X in the first place, a space of possible concepts over which to distribute probability mass. Fodor is looming. /21
Whichever way we look at it, we need something to learn anything, and that something must be somewhere. Should we be connectionists and need dedicated architectures? Should we be Bayesian and require some prior event space? What if the answer was in the data? /22
PART 3 - THE DATA. Working backwards. If linguistic competence is in the data, ready to be captured by some generic pattern-finding algorithm, it doesn't need to be innate. If competence is not in the data, it needs to be somewhere else. So what is in the data? /23
Well, meaning is in the data, right? Harris (1954)! Distributional Hypothesis! But wait, what did Harris actually say? "To the extent that formal (distributional) structure can be discovered in discourse, it correlates in some way with the substance of what is being said... /24
"... However, this is not the same thing as saying that the distributional structure of language (phonology, morphology, and at most a small amount of discourse structure) conforms in some one-to-one way with some independently discoverable structure of meaning." /25
So if (language) data does not perfectly equal meaning, then meaning minus form corresponds to some non-empty element which, not being data, must be something else. Perhaps non-linguistic stuff, the contextual 'schemas' in Fillmore. And/or perhaps that mysterious innateness. /26
State-of-the-art distributional models of meaning have to apply great amounts of distortion to the input data to perform well. This distortion is a *hard-encoded* part of the model which needs to be there to do anything useful with the input. So what is in the raw data itself?/27
Last year, student Johann Seltmann did a short project in our group to start elucidating "How much competence is there in performance?" (Seltmann et al, 2019) His intention was to understand what exactly was in one of the most basic structures of language: the word bigram. /28
Johann found that word vectors based on bigram probabilities encoded only moderate amounts of lexical semantics. *But* they were extremely good at auto-encoding bags of words, implying that they captured 'contrast': the notion that words that differ in form differ in meaning. /29
Contrast is an early feature of language acquisition (Clark, 1988). The fact that it might be encoded in a very simple structure in language is perhaps no coincidence. If this result holds, it would mean that this particular phenomenon *is* in the data in its rawest form. /30
There is much more experimentation needed to get clear on the role of data vs 'innate' features in a learning algorithm. At present, we only know that certain hard-encoded mechanisms help, but without controlling for the exact contributions of the environment and the learner. /31
And another puzzle: why should there be a mismatch between form and meaning anyway?
We can be Chomskian about this: performance is degraded competence and produces the mismatch.
Another explanation is that language did it on purpose.
But that's a story for another day... /32
We can be Chomskian about this: performance is degraded competence and produces the mismatch.
Another explanation is that language did it on purpose.
But that's a story for another day... /32




















