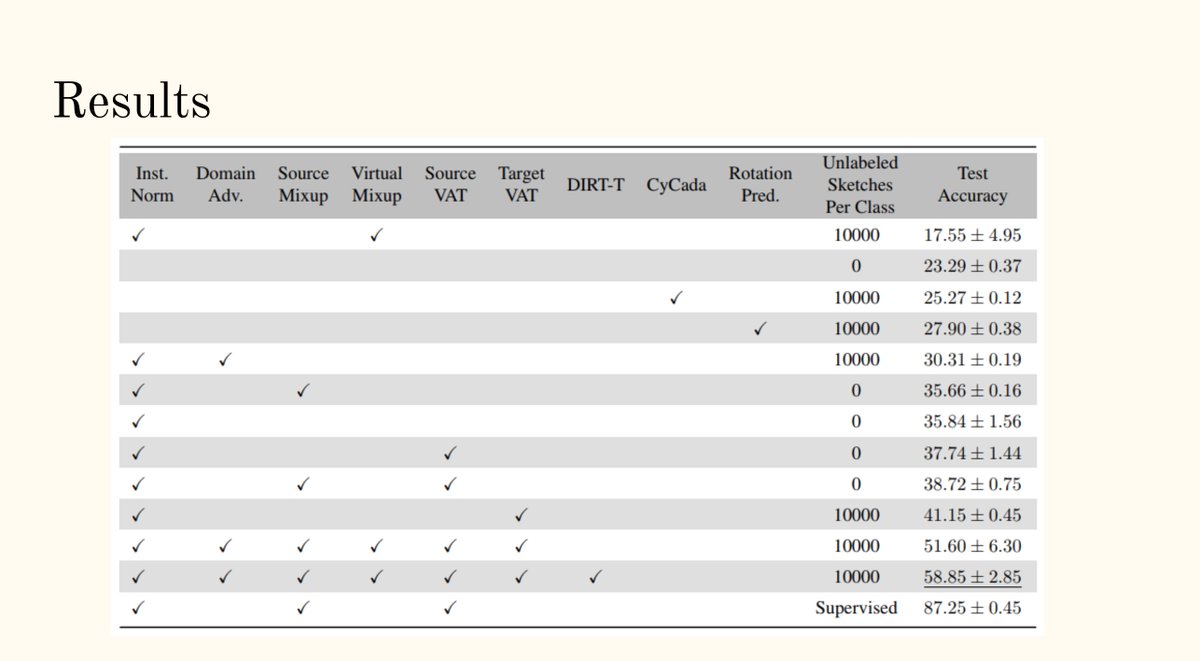
Neuroevolution of Self-Interpretable Agents
Agents with a self-attention “bottleneck” not only can solve these tasks from pixel inputs with only 4000 parameters, but they are also better at generalization!
article attentionagent.github.io
pdf arxiv.org/abs/2003.08165
Read on 👇🏼
Agents with a self-attention “bottleneck” not only can solve these tasks from pixel inputs with only 4000 parameters, but they are also better at generalization!
article attentionagent.github.io
pdf arxiv.org/abs/2003.08165
Read on 👇🏼
Work by @yujin_tang @nt_duong me @googlejapan
The agent receives the full input, but we force it to see its world through the lens of a self-attention bottleneck which picks only 10 patches from the input (middle)
The controller's decision is based only on these patches (right)
The agent receives the full input, but we force it to see its world through the lens of a self-attention bottleneck which picks only 10 patches from the input (middle)
The controller's decision is based only on these patches (right)
The agent has better generalization abilities, simply due to its ability to “not see things” that can confuse it.
Trained in the top-left setting only, it can also perform in unseen settings with higher walls, different floor textures, or when confronted with a distracting sign.
Trained in the top-left setting only, it can also perform in unseen settings with higher walls, different floor textures, or when confronted with a distracting sign.
People who learn to drive during a sunny day can (sort of) also drive at night, on a rainy day, in a different car, or when bird droppings hit the windshield
Without further training, we also test on brighter/darker scenery, or with artifacts such as side bars or background blob
Without further training, we also test on brighter/darker scenery, or with artifacts such as side bars or background blob
So is ‘Attention All We Need’ for Generalization?
Of course not!
If we modify the game by adding a fake lane next to the real lane, the agent prefers to look there and drive over instead—something human drivers with logical reasoning won't do, unless they're in another country!
Of course not!
If we modify the game by adding a fake lane next to the real lane, the agent prefers to look there and drive over instead—something human drivers with logical reasoning won't do, unless they're in another country!
The attention bottleneck doesn't generalize if the background changes dramatically.
Some fun failure cases in the Discussion section:
When we suddenly replace the green background with a YouTube cat video, it stops to look at the cat's fat belly, rather than focus on the road🐈
Some fun failure cases in the Discussion section:
When we suddenly replace the green background with a YouTube cat video, it stops to look at the cat's fat belly, rather than focus on the road🐈
Distract RL agent's attention from driving with “King of Fighters” 🥊🔥
Attention loves noise.
Even if we train our agent from scratch in a noisy background setting, it still attends only to the noise and not to the road.
Surprisingly, it learns to interpret those points as obstacles, and by avoiding them, still manages to wobble through the track!
Even if we train our agent from scratch in a noisy background setting, it still attends only to the noise and not to the road.
Surprisingly, it learns to interpret those points as obstacles, and by avoiding them, still manages to wobble through the track!
Perhaps lowering the number of patches (K) will force the agent to focus on the road.
But when we decrease K to 5, it still attends to noise rather than to the road. Not surprisingly, if we increase K to 20, it performs better.
CarRacingNoise-v0 will make a nice benchmark task.
But when we decrease K to 5, it still attends to noise rather than to the road. Not surprisingly, if we increase K to 20, it performs better.
CarRacingNoise-v0 will make a nice benchmark task.