
Recent Advances in Transferable Representation Learning @RealAAAI
Adaptation is essential.
One key challenge is the vocabulary which may vary drastically across domains. Sentence structure may differ as well and this have heavy consequences on downstream tasks e.g., NER.
One key challenge is the vocabulary which may vary drastically across domains. Sentence structure may differ as well and this have heavy consequences on downstream tasks e.g., NER.
Another example is Semantic Role Labelling where knowing domain knowledge is essential to get roles and right 

In this tutorial authors focus on Cross-lingual and cross-domains transfer and transfer in multi-modal setting.
Cross-lingual transfer: understand a situation described in a language the model does not know (at least not from its training data).
One key task to achieve this broader goal is Cross-lingual Entity Linking (XEL). Given a sentence in English, identify the entities and link them to Wikipedia pages.

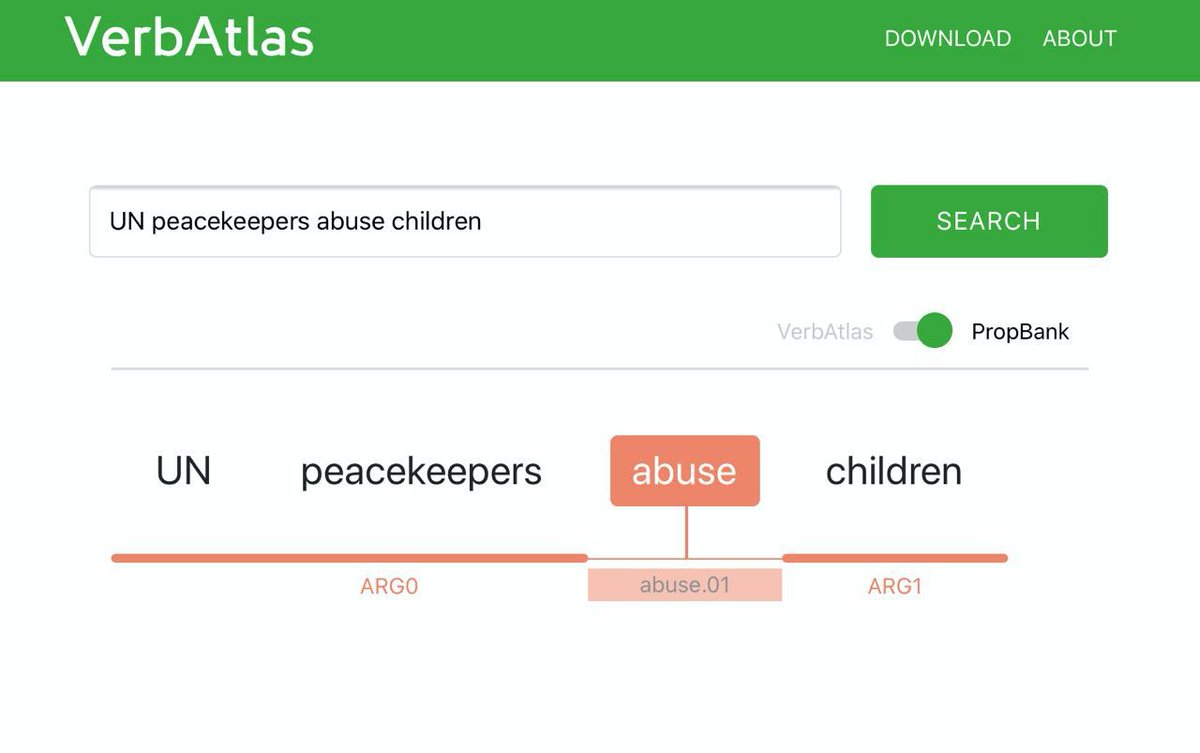
I note that the SRL model that you can reach at verbatlas.org can actually get this example right.
verbatlas.org/search?word=UN…
verbatlas.org/search?word=UN…
Transfer in multi-modality setting: observe example from one modality, e.g., images, and exploit them to perform tasks in other modalities, e.g., answering textual questions.
Questions addressed by the tutorial:
1) Can we utilize recent technologies to address cross-X transfer?
2) How?
Where X can be Language, Modality or Domain.
1) Can we utilize recent technologies to address cross-X transfer?
2) How?
Where X can be Language, Modality or Domain.
Intro is over. Here it is the outline of the tutorial:

The Basics of Embeddings presented by Kay-Wei Chang:
ML framework has changed after deep learning:
ML framework has changed after deep learning:

Features, therefore the representation step in Deep Learning Framework, should be able to provide representations that are transferable.
Word vectors rely on the distributional hypothesis "you shall know a word by the company it keeps", Firth 1957. So words that appear in similar context should have similar vector representations.
Contextualized word representations: the word representations depend on the sentence (text) their are used in. Contextualized embeddings are not static anymore and depend on the input context

language modelling proved to be an effective task that can be used to learn contextualized word representations that can be used in different tasks.
While ELMO was among the firsts proving that, others followed this way and implemented transformer-based models, e.g., BERT aclweb.org/anthology/N19-…, XLM arxiv.org/abs/1901.07291, RoBERTa , etc.
Transformer-based models used Masked Language Model as objective. Differently from standard language model objective, the model has to predict the words that are masked within the input sentence.

The representations learned via Masked Language Modelling (MLM) objective proved to be effective across several text understanding tasks (Glue and SuperGLUE benchmarks) when finetuned to the target tasks.
Dan Roth is now about to talk about Corss-Lingual Representations and transfer.
Can we understand data given in a language which the model has never seen at training time?

Models proved to work well when large training data are available. The goal, therefore, is not to advance tasks in which annotated data are largely available, but rather to solve those tasks in specific situations (domains, languages etc) in which annotated data are scarce.
some success have been already achieved:

Tasks settings:
- two surprise languages (Odia and Ilocano)
- two weeks to develop a solution
- no annotated data
- minimal remote exposure to native speakers.
- two surprise languages (Odia and Ilocano)
- two weeks to develop a solution
- no annotated data
- minimal remote exposure to native speakers.
results on three tasks are interesting (consider that one week before nothing was known about the two languages).

Models use human knowledge (non-speaker annotations, and declarative knowledge, uses "cheap" translation from automatic systems, and pre-trained representations (extended Multilingual BERT).
Pretrained-Representations however are not sufficient to achieve good transfer as it will be shown in what follows.


Can we use level of supervision (picture) and what are the results?

The performance of a model using the pretrained word representations correlates positively with the level of supervision.

the goal is now to train a single model from data in multiple languages so to have a unified model that can handle texts and recognise named entities in different languages.

In document classification it turned out that the best representations were sparse vectors of TF-IDF of mentions.
This until BERT happened. Indeed, Multilingual BERT (M-BERT) is a single model that has been trained with MLM objective on data in different languages. Therefore there is no ** direct supervision **, i.e., no manually-annotated and task-specific data.
BERT permeated in NLP and models in different tasks started using BERT instead of BiLSTM. Nevertheless, many questions still remain.
The Speaker now start analysing Multilingual NER and different approaches to achieve cross-lingual transfer.

A supervised model in each language is used as upper bound. The tested model is a model from Ratinov & Roth 09.

As one can see from the previous picture the model from 09 beats fastText embeddings trained on Wikipedia and fall behind M-BERT only. This as concern Monolingual Setting
As for corss-lingual results the CT++ model is tested (Xie et al EMNLP 18). M-BERT is still the best in this setting, however CT++ is not that far away (look at average).

To summarise, the different between monolingual and x-lingual results is still large (47 F1 vs 74 F1 in NER). Cross-lingual transfer by it self is not enough yet.
We now move to the second part:

Let's start with a question, can you identify a named entity?
Pyaalestaaina and gaaja (Palestine and Gaza)
Pyaalestaaina and gaaja (Palestine and Gaza)


Humans can still transfer some of their knowledge and recognise NE in foreign language (when script is adjusted)
Here there are research questions we are interested to answer and an experiment that asses the ability of humans to annotate foreign language



When giving pre-annotated data (by non expert) annotators can annotate more and better and models can use better data and attain higher results

This is however still not sufficient:

Multilingual BERT is trained with no specific x-lingual objective. Nevertheless it works.

Why is M-BERT X-lingual? The analysis is carried out on three different dimensions. English is always the source language and 3 languages were considered Spanish, Hindi and Russian.

The hypothesis why M-BERT works is that it is due to the overlapping word-pieces across languages. This is only a hypothesis and we refer to this as word-piece overlap. But what happen if we remove word-piece overlap?
The authors do that by inventing Fake-English which does not share any wordpiece with English

As one can see, when using fake-english (hence no wordpiece overlap) there is no large drop in performance and transfer works and changes are not significant. Therefore the cross-lingual capabilities of BERT ** do not ** depend on the wordpiece overlap!

So where does the transfer of BERT come from?

Experiment show that when eliminating word ordering (by permuting the sentence i.e., swapping random words therein) there is a large change in results. Therefore Word Ordering ** does impact ** significantly.

This also depend on the task. XNLI is less impacted than NER for example.
To summarise

Another key aspect that have a large impact is the depth of the model. ** The transfer is better with deep models **
When changing the number of attention heads, instead, nothing change significantly.

Additionally to the MLM objective, BERT also is trained to predict whether a sentence follows another one. We now wonder, what is the impact of this objective? ** In X-lingual setting this additional lost is actually important **
The tweets cover 1/3 of the entire tutorial








