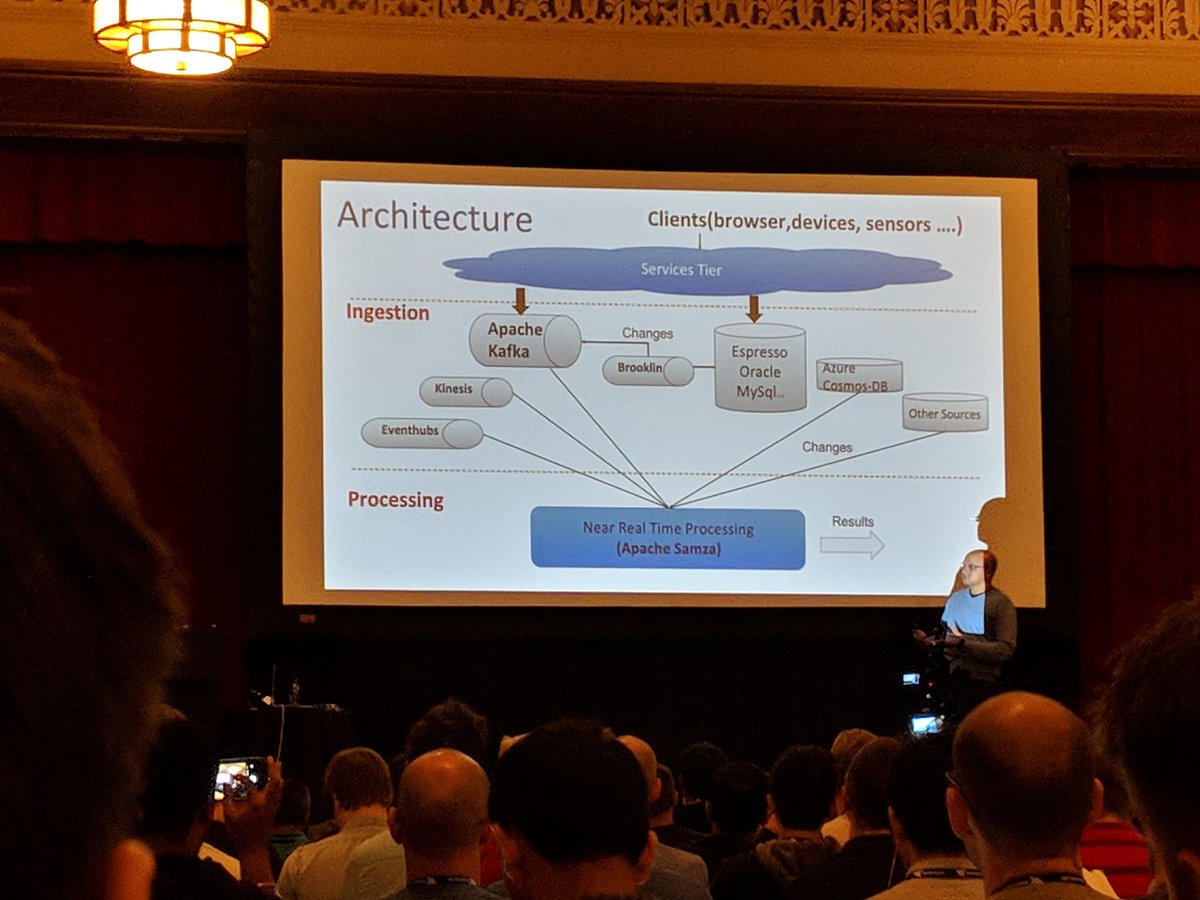
At @apachekafka meetup in Singapore and Agoda, an online travel agency is talking about their Kafka architecture. Should be good!
5bn messages a day, 190TB a day. 9000+ services. 5 data centers. 230 Kafka brokers.
Traffic and search events go through Kafka to Hadoop, to be processed by Spark. App metrics go through Kafka to Cassandra and get queried with Graphana. Application logs go through Kafka to Elastic.
All those get reported by apps directly to Kafka.
Data goes to Kafka cluster on their DC, but their replicate to a global Kafka cluster where they can generate company-wide reports.
They use the famous audit-pattern to guarantee data accuracy. Like Confluent Control Center.
They optimized for resilience, monitoring and throughput - latency wasn't very important. One example: Their producers write to disk and a process reads from disks on the machine and sends to Kafka. This all works in batches - resilient but slower.
Cross-DC replication was using too much traffic. Because we sent from every source to every other DC. Thats a lot of write-amplification.
Not all links are equal! Shanghai to Singapore is cheap, Shanghai to Bangkok is expensive. We decided to send the data in paths that use the cheap links and no longer send the same events more than once.
They had pervasive data quality issues - producers just didn't care about consumers. They started using Avro and Schema Registry to get this under control. They forked Confluent's, added backend DB and web-ui for approval process.
IMO: This is open-source working as intended. Build on other's work. Too bad this wasn't contributed back. Especially the approval-UI. I think others would love that.
They created a unit-tests for compatibility, just a library that everyone uses. Love this :) And they propagate the schemas and metadata all the way to Hadoop. Now Hadoop has exact representation of the message class itself.
Moving Kafka events from JSON to Avro saved 30% on network traffic. Moving to Parquet format in Hadoop made their Impala queries 60% faster.
They also use the serializers and schema registry as a way to drop messages that we don't want to send. They validate much more than just compatibility. "Do we have ID column?" for instance.