,
56 tweets,
17 min read
Read on Twitter
bon, sur quoi je finis la semaine ? je peux mettre un lien vers ma page freakonometrics.github.io et mon blog freakonometrics.hypotheses.org pour ceux qui auraient des questions... Bon, je pourrais revenir 5 minutes sur un autre travail de recherche rss.onlinelibrary.wiley.com/doi/epdf/10.11… avec @coulmont 

allez, je reviens sur la petite histoire... en fait, on avait déjà travaillé un peu avec @coulmont (et @joelgombin)... sur le vote par procuration, en France... Il y a une version sur halshs.archives-ouvertes.fr/halshs-0094523…, et sur washingtonpost.com/news/monkey-ca…
le point de départ était un courriel, le 14 juin 2016
"salut Arthur, une question de modélisation assez simple, je crois. Je cherche à estimer la proportion d'homonymes en France (...) à partir des listes électorales"
"salut Arthur, une question de modélisation assez simple, je crois. Je cherche à estimer la proportion d'homonymes en France (...) à partir des listes électorales"
oui, comme on en parlait hier, il n'existe pas, en France, de "base de données exhaustive des habitants", genre état-civil. Sinon ça serait trop facile... Bref, on a une sous-population, en l'occurrence assez grosse, puisqu'on a le nom et le prénom de tous les votants sur Paris
(les listes électorales c'est amusant, j'en parlerais sur mon blog cet été je pense). Et la question est : peut-on estimer le nombre d'homonymes...? C'est amusant, parce qu'assez vite (en quelques heures) je lui fais remarquer que c'est comme le paradoxe des anniversaires

on a un groupe de taille fini (le nombre de jours dans l'année, ou les couples {prénom, nom}) et on veut des probas d'avoir deux personnes dans un très gros groupe (une classe ou un pays) qui ont le même anniversaire, ou le même nom...
Bref, je commence à essayer de faire des maths, en partant sur du paradoxe des anniversaires généralisé (avec une distribution non uniforme des anniversaires, mais c'est pas pareil pour les noms et les prénoms)... mais c'est l'enfer... en gros c'est de la combinatoire
mais des factorielles de plusieurs milliers de noms et prénoms, ça explose... Je tente alors des simulations... Au début, je tente des trucs du genre "proba d'avoir aucun homonymes" mais c'est pas très malin, et @coulmont suggère de regarder la proportion de gens qui ont un
homonymes. De mémoire j'en parle un peu avec @a_bh aussi, dès le retour des vacances d'été... En fait, on tente de partir sur un modèle paramétrique : on a un liste de k objets (k couples {prénom,nom}) et on en tire n : quelle est la proportion de personnes qui ont le même nom
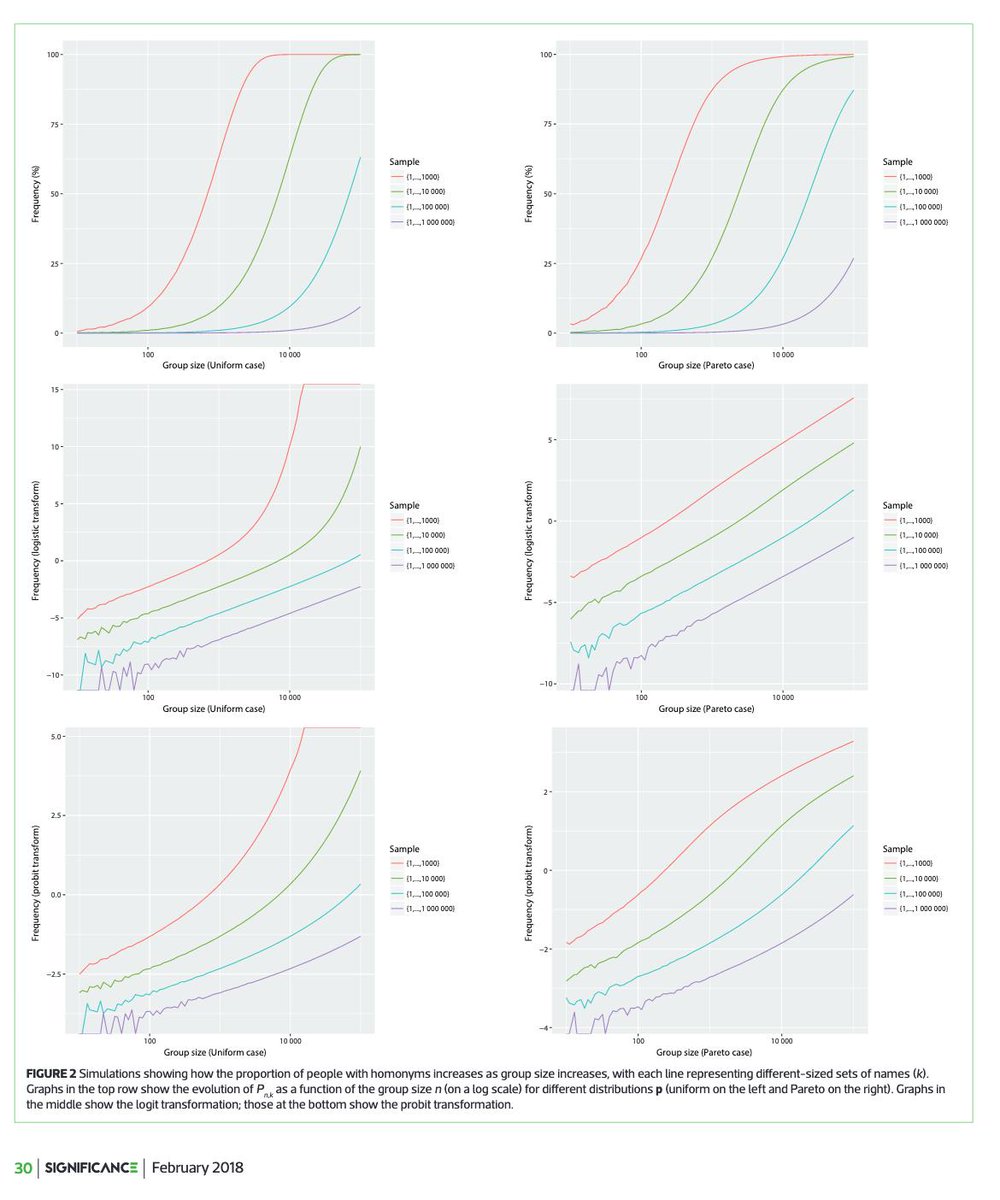
et je tente plusieurs distribution sur les k objets : uniforme, Zipf... et sur des simulations, j'obtiens les graphs suivants, pour la proportion d'homonymes


en gros, avec 10,000 personnes et 1,000 noms, la proportion d'homonymes est proche de 100%, mais avec 10,000 noms, c'est plutôt 70%, et 15% si on a 100,000 noms possibles... bref, on a des choses, mais nous on a vraiment beaucoup de monde (60 millions) et de couples noms, prénoms
assez vite, on fait une représentation logarithmique en abscisses, mais on reste sur la proba en ordonnées.... @coulmont suggère un passage au log sur la proba, mais je suis pas fan, parce que rien ne le justifie vraiment... et je tente plein de transformation...
dont un truc bizarre : représenter la transformée probit de la probabilité d'avoir un homonyme, en fonction du log de la taille de la population... et étrangement, quand on a une loi puissance pour la distribution des noms... on a un modèle qui semble linéaire...

dans le papier, on fait du probit et du logistique... et avec du logistique, c'est encore plus magique ! rss.onlinelibrary.wiley.com/doi/epdf/10.11… autrement dit log(p/1-p) = a+b log(n)
j'ai tenté assez longuement de le prouver, avec des développements asymptotiques dans tous les sens... en vain... Ça me dérangeait un peu en terme de stratégie de publication... mais bon, on tenait le bon bout... sur des simulations, ça marchait....
Sauf qu'en vrai, c'est un peu compliqué... on observe des couples {prénom,nom} : comment on peut les tirer au hasard ? j'ai tenté des lois paramétriques sur les deux (fonctions puissances) mais le soucis, c'est que les deux sont très corrélés...
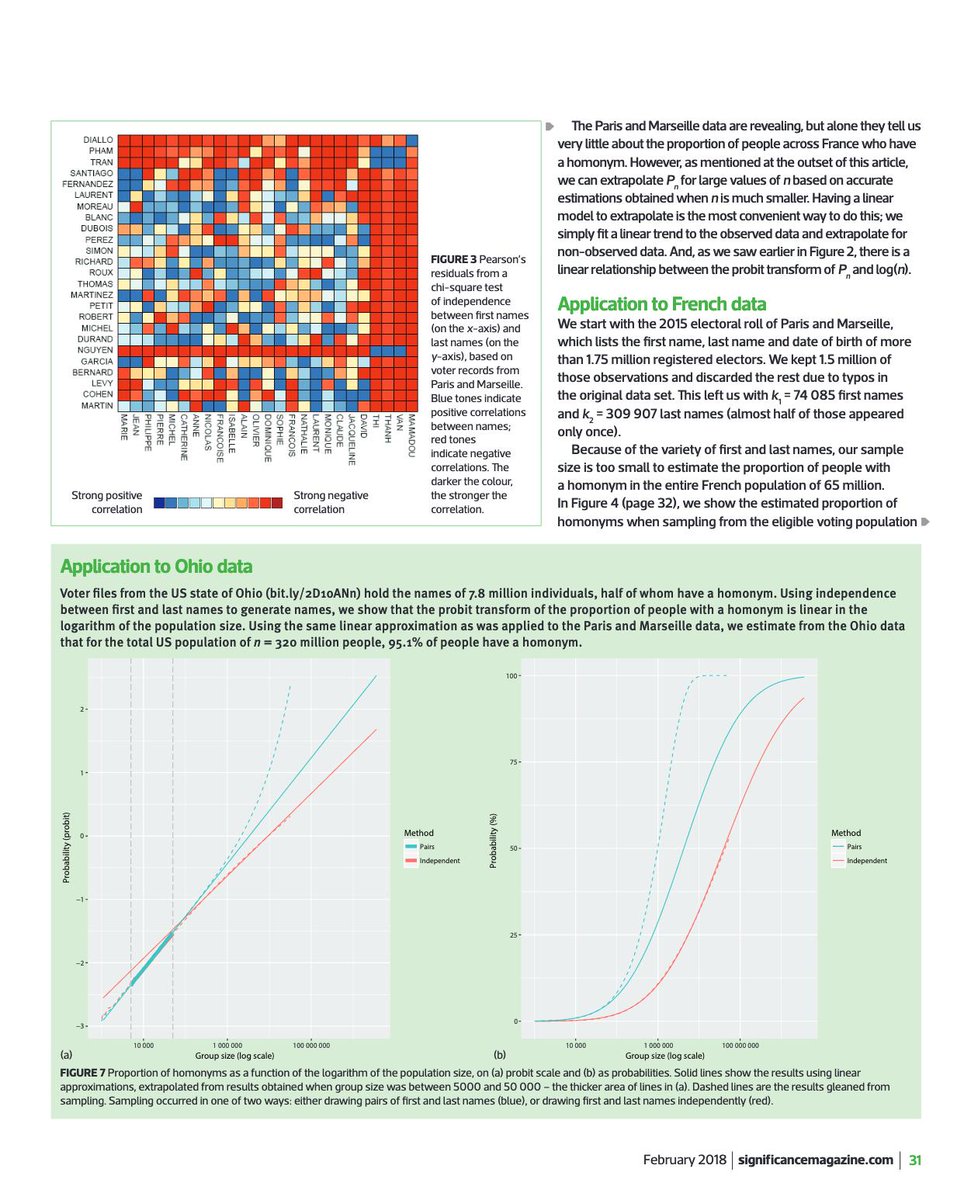
on avait fait un test d'indépendance (chi-deux) entre nom et prénom sur les plus populaires.... (contribution négartive en rouge et positive en bleu : genre David Cohen = bleu, David Nguyen = rouge, Thanh Lévy = rouge, Thanh Pham = bleu, etc)

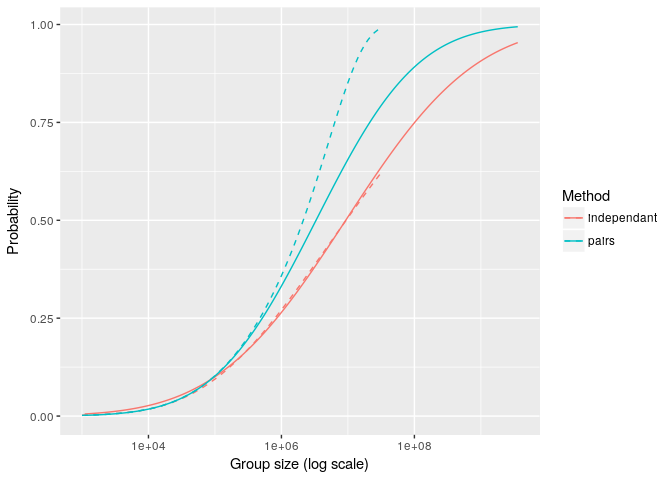
je pouvais tirer dans les couples observés, mais ça limitait forcement les choix... J'ai tenté les deux : je tire le couple {prénom, nom} dans la base, ou je tire le prénom dans la base, je tire le nom, et je les colle...

C'est très différent, hein ? ben en fait, quand on regarde à gauche, dans une petite population, pas tant que ça ! en fait, les courbes sont assez parallèles à gauche...
J'ai donc proposé de gardé la partie de gauche pour extraire la tendance, et puis on prolongeait ensuite linéairement...

ce qui, ramenait à une échelle de probabilité en ordonnées donne le graphique suivant (avec la conclusion qu'en France, on peut estimer que 80% des français ont un homonyme)

Histoire de tester la robustesse, on a tenté une base un peu plus grande pour la partie linéaire de gauche...

good news, on reste avec un ordre de grandeur de l'ordre de 80%...

Bref, on était content.. on a tout mis sur github.com/freakonometric… et on a regardé deux autres choses ! on a regardé sur un autre pays (en l'occurrence aux Etats-Unis) et cette histoire de linéarité sur la transformée logistique semble aussi valide)
(dans le papier, j'avais refait les graphs avec #ggplot2) On s'était aussi demandé sur la probabilité d'avoir un homonyme augmentait ou baissait avec le temps...
Heuristiquement, pour les personnes nées entre 1916 et 1940 le top 10 des prénom était porté par 25.17%, contre 12.59% quand on est né entre 1966 et 1990... bref, on a un étalement de la distribution (plus de prénoms rares) et donc moins d'homonymes...
Bref, on s'était bien amusé avec @coulmont ! on était prêts à faire des billets sur nos blogs respectifs (coulmont.com/blog/ pour ceux qui ne connaîtraient pas), et on s'est dit "et si on essayait une publication ?"
et mine de rien, quand on commence vraiment à faire des trucs transdisciplinaires, ben c'est pas simple de publier (ou d'avoir des financements, de la reconnaissance... etc) Bref, soit on fait une publication de socio en mettant les maths sous le tapis (i.e. en annexes ou en...
complément, mais c'est un peu frustrant, parce que je trouvais ça marrant, moi, c'est histoire de relation linéaire entre le log de la côte - c'est ce qu'on regarde ici - et le log de la taille de la population...
ou alors on tente une revue de statistique, mais j'en parlais l'autre jour avec mes histoires de naissance les jours de pleine lune, c'est un peu "pas assez mathématique pour une revue de statistique"
et là, juin 2017, je suis avec @3wen à Boston, on rend visite à @PierreEJacob et là, je tombe sur un exemplaire de @signmagazine qui traîne, sur une table... pour ceux qui ne connaissent pas @signmagazine, c'est le magazine de statistique le plus lu au monde !




c'est le magazine un peu grand public de l'@AmstatNews et de la @RoyalStatSoc... et je me dis que ça serait en fait le magazine le plus naturel, surtout qu'un article sur la popularité des prénoms venait de paraître... rss.onlinelibrary.wiley.com/doi/10.1111/j.…
bref, retour super positif de l'éditeur... un peu long à publier parce que j'ai du mal à écrire "grand public", j'aime mettre des formules de maths, plus concise, claires et précises que du baratin, mais bon... super aide au sein du comité éditorial, et l'article paraît en 2018
Voilà comment passer du "une question de modélisation assez simple, je crois" par mail à une publication, 2 ans et demi plus tard (sans perte de temps pour publier)... Et oui, comme le notait @joelgombin, c'est cool les questions "assez simple" des sociologues !
ça pose des vraies questions ! on remet ça quand tu veux @coulmont !
je pourrais revenir 5 minutes sur cette histoire de temporalité, pour expliquer un peu à ceux qui ne travaillent pas dans le monde universitaire.... Ce projet peut sembler long, pour un petit papier de 6 pages, au final...
beaucoup de temps a été passé (de mon côté) à comprendre formaliser correctement le problème, le ratacher à d'autres connus, simuler sur mon ordinateur, faire des graphiques, trouver la bonne représentation qui va m'éclairer....
plein de moments où je ne réfléchis pas à mon problème, mais, insconsciemment, il est là... il est sur mon tableau, avec la liste de la quinzaine de projets en cours... par moment, on reprend, avec un regard neuf, et des passages s'éclairent...
et des fois non... Une autre difficulté est : je fais ou je fais faire ? autrement dit, je prends de mon temps, ou je mets un étudiant sur le projet ? mine de rien c'est une question compliquée parce que l'étudiant, en thèse par exemple, il a un financement limité... en trois ans
il doit avoir bouclé... et les problèmes amusants, le plus souvent, on sait pas trop si ça va aboutir... On essaye d'éviter un trop grande prise de risque, on va plutôt mettre sur un sujet où on a l'intuition que "ça va marcher"...
Mais le grand luxe quand on est en poste, c'est d'avoir un peu de temps, du temps pour réféchir à des problèmes, en espérant voir quel fil tirer pour que la pelotte se déméle... une fois @achambertloir parlait de l'importance de la marche à pieds...
et je suis assez d'accord, marcher est un moment parfait pour se plonger dans ses pensées, tourner un problème dans tous les sens.... c'est moins risqué que le faire en vélo par exemple... Mais ces moments de calme sont indispensables, et trop rares...
je rajouterais personnellement quand je fais la cuisine, le samedi... c'est mon moment, je suis plongé dans mes pensées, et souvent ça décante.... Quand je discute avec des voisins, des parents d'amis des enfants, c'est souvent cette partie là qui les dépasse...
le fait que je cherche du temps "libre", où je peux juste me poser, vider mon esprit, et éventuellement reprendre un problème, ou pas...
Mon second point sur cette histoire de temporalité est lié à une réflexion de la conférence où j'étais la semaine dernière, qui finissait avec une table ronde industrie - académique (en l'occurence, on parlait "InsureTech" à l'université de Californie)
et quelqu'un a du dire "tout le monde sait qu'on n'a pas la même notion du temps en entreprise et dans le milieu académique"... et ça m'a interpelé parce que ça me semble beaucoup plus subtile que ça !
Je pourrais citer plusieurs expériences que j'ai pu avoir avec des partenaires (industriels et aussi publics), avec des "on est ok pour te passer des données", et ensuite, ça prend des semaines, voire des mois... Il y a trois semaines, dans un workshop, je croisais quelqu'un
qui m'avait promis des données, et qui m'a dit "c'est ok, on a vu avec les juristes, on te les envoie"... depuis rien, malgré mes deux relances... Et ce sont les universitaires qui ne sont pas réactifs ? Perso, j'ai prévu de bosser cet été sur les données, pour
organiser ensuite un "jeu" à la rentrée ("field-experiment"), et plus ça va, plus je me dit que ça va tomber à l'eau, parce que dans le monde non-universitaire, tout prend un temps fou !
Je pourrais mentionner un autre projet, sur lequel on a travaillé trois ans, en partenariat avec un partenaire industriel... pendant trois ans, on a pas mal avancé sur les questions de départ, publié des papiers.... Au début, on avait fait une réunion avec les partenaires
pour expliquer ce qu'on voulait faire... à la fin, on a fait une autre réunion de bilan. Entre temps, pas mal de monde avait bougé, le chef avait changé, etc... bref, nouvelle réunion, et je me rends compte que eux n'ont pas avancé dans leur réflexion...
Ils se posent les mêmes questions que 3 ans auparavant... ça réinvente la roue, avec des personnes différentes, certes, mais rien n'a avancé de leur côté, et ça me navre un peu...
On avait du dire il y a trois ans, "avec des données, on pourrait regarder ça, et ça", "ah oui, très intéressant", mais en trois ans, on n'a jamais eu les données, nous on a fait le modèle, on a trouvé des données publiques pour le tester, et en le présentant on a le droit à
"ça pourrait être intéressant de le tester sur nos données". Bref, ces histoires de temporalités université vs monde industriel, elles sont complexes ! oui, on a besoin de temps libre pour réfléchir... ce temps que je passe à lire ou penser, j'ai l'impression
que mon partenaire industriel l'a perdu, à sa manière... Même si je suis très lent pour réfléchir à un problème, je n'ai jamais eu l'impression de perdre mon temps sur un problème.... j'avoue aimer prendre mon temps, mais il n'est jamais perdu !
Voilà, c'était le moment coup-de-gueule de l'universitaire du mois de mai, celui à qui on va dire pendant les semaines à venir "bon, les cours sont finis, vous êtes en vacances, hein ?"