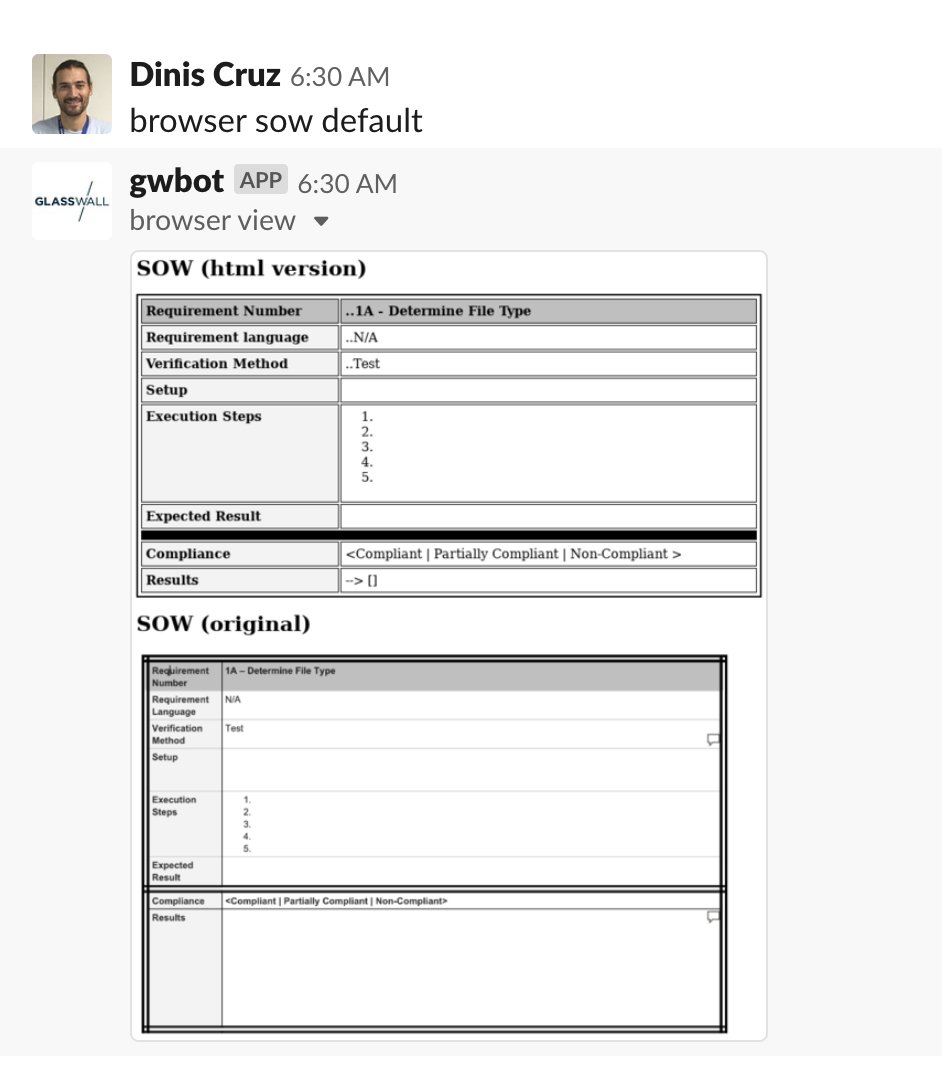
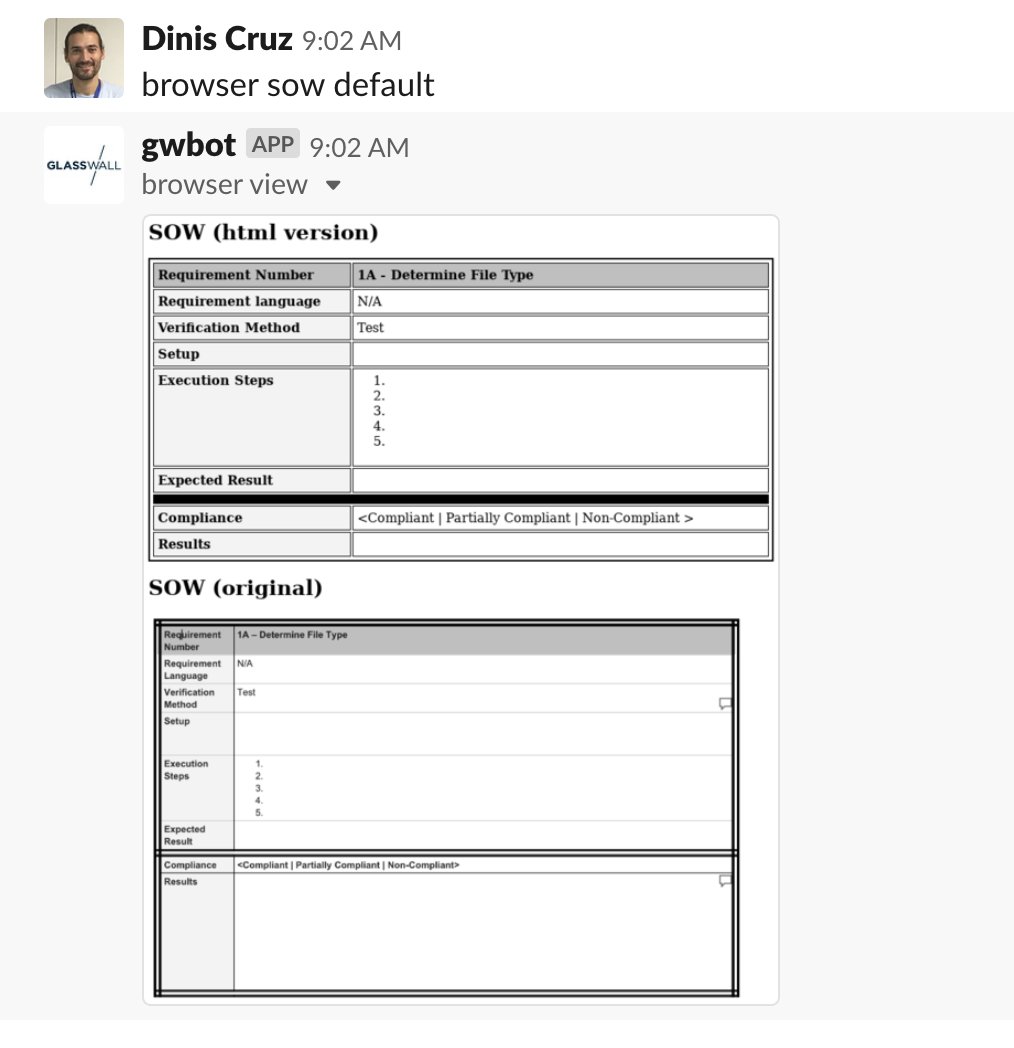
In the twitter thread I got to the point where I needed a new Lambda function,
In this thread I'm going to show how I create, update and invoke lambda functions in 1 to 2 seconds (which makes a massive difference in the OODA and REPL lambda dev workflow)
In this thread I'm going to show how I create, update and invoke lambda functions in 1 to 2 seconds (which makes a massive difference in the OODA and REPL lambda dev workflow)
First step is to create two files locally
osbot_browser/lambdas/gw/sow.py - the lambda code
test_QA/lambdas/gw/test_sow.py - test test file
and execute the test file (which invokes the lambda function directly, i.e. locally on my dev box)
osbot_browser/lambdas/gw/sow.py - the lambda code
test_QA/lambdas/gw/test_sow.py - test test file
and execute the test file (which invokes the lambda function directly, i.e. locally on my dev box)

Let's break this down in the separate components and actions:
The file at the top is a very simple lambda function which returns a string
The "def run(event, context):" is the normal lambda callback structure
The file at the top is a very simple lambda function which returns a string
The "def run(event, context):" is the normal lambda callback structure

The test file simply invokes the run function directly
This means that we are able to invoke the function just like AWS will (I've already configured my local dev box using AWI CLI)
Note: the "self.result" setUp and tearDown code is something I tend use a lot
This means that we are able to invoke the function just like AWS will (I've already configured my local dev box using AWI CLI)
Note: the "self.result" setUp and tearDown code is something I tend use a lot

executing the test confirms that this part is working

of course that in "production code" we would change that to an assert
See below an passing and an failing assert
See below an passing and an failing assert


Before I setup the lambda function let's look at AWS console Lambda and S3 folders and confirm that there are no sign of SOW files in there


Next step is to create the Lambda function using the multiple helper methods from the OSS_AWS (github.com/owasp-sbot/OSB…) api
The code below (which was executed in 4s) created the lambda by:
- zipping current project code
- uploading zip file to s3
- creating lambda function
The code below (which was executed in 4s) created the lambda by:
- zipping current project code
- uploading zip file to s3
- creating lambda function
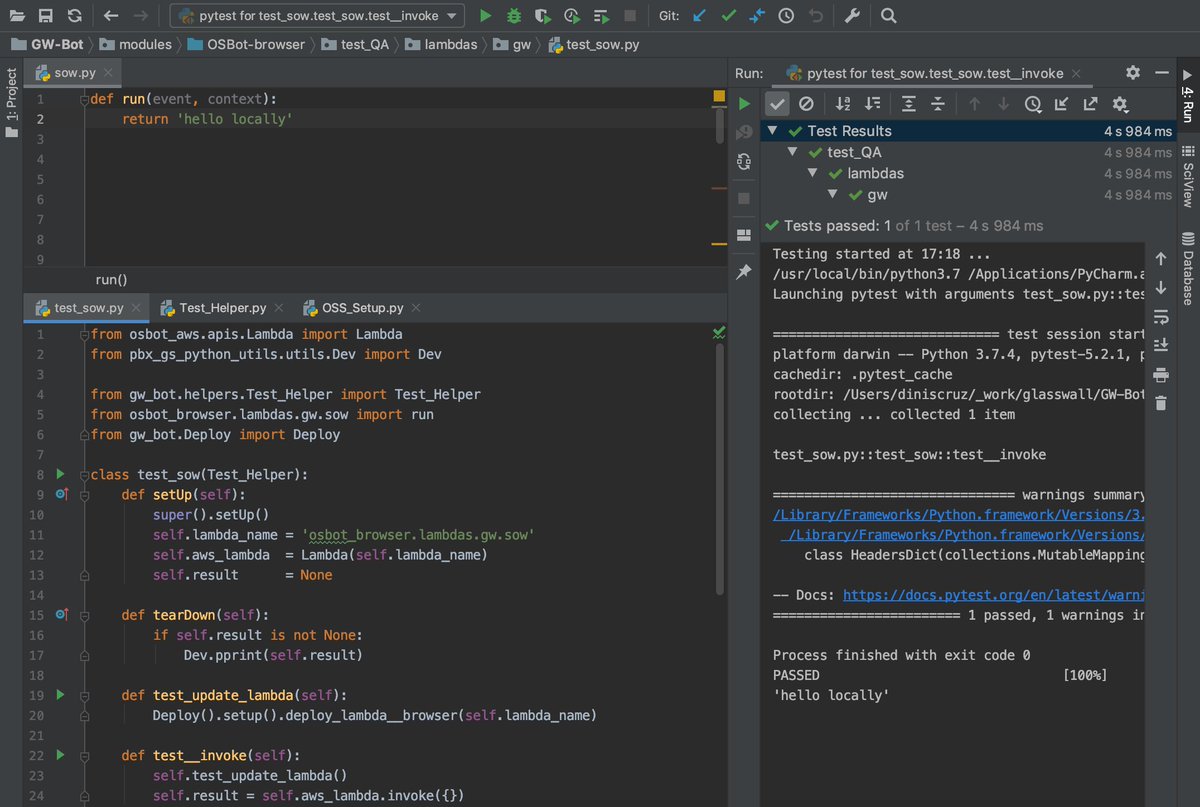
Here is the main function
setup() - sets the variables and objects
test_update_lambda() - creates or updates the lambda function
test__invoke() - executes the lambda function
setup() - sets the variables and objects
test_update_lambda() - creates or updates the lambda function
test__invoke() - executes the lambda function

At AWS what happened was that a new zip file was uploaded to S3
This zip file is 400k because the code includes the OSBot-Browser code (this could be optimised if needed)
This zip file is 400k because the code includes the OSBot-Browser code (this could be optimised if needed)

And the lambda function was created

which looks like this

Let's see the workflow in action by making a change to the return value of the lambda function

Here is what happened in the pic above:
- the return value from the lambda function was changed
using the test:
- the deploy_lambda__browser function will:
a) re zip code
b) upload zip to s3 and
c) reconfigure lambda
- invoke the lambda function
all in 2.5 secs :)
- the return value from the lambda function was changed
using the test:
- the deploy_lambda__browser function will:
a) re zip code
b) upload zip to s3 and
c) reconfigure lambda
- invoke the lambda function
all in 2.5 secs :)
Refreshing the lambda function will confirm that the source code was updated

The way to pass values/data to the lambda function is via the `event` field which receives the value passed via the `invoke` function

Here is what is happening:
The lambda function now uses the `name` param from `event`
The lambda function now uses the `name` param from `event`

The invoke is given a python object

The test execution shows the param in action

note that on every execution the main lambda function is being updated and executed (all in 2.3 secs)

If needed, we can also execute the lambda function directly via the AWS console UI


ok, let's now take this up a notch and run chrome_headless in the lambda function (using the apis from github.com/owasp-sbot/OSB…)
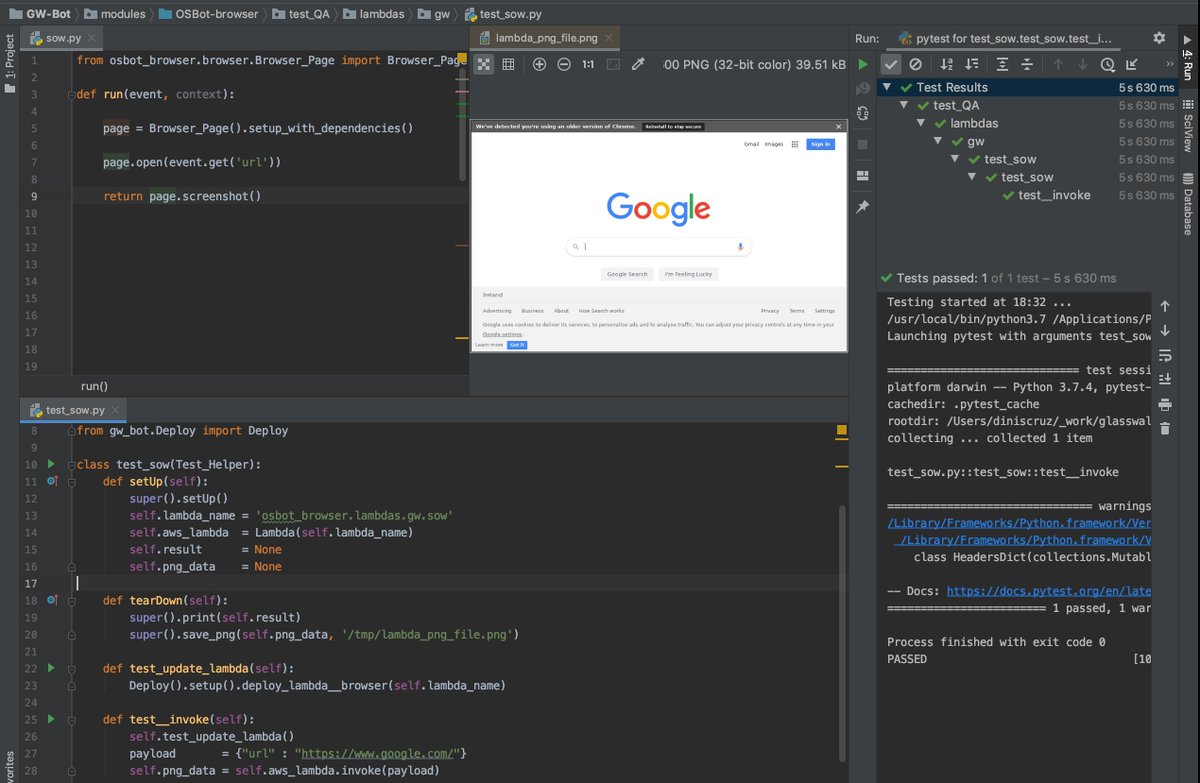
The lambda code:
1) sets up chrome_headless (on first lambda invoke this will download a zip from s3 containing the chrome binary and extract it to /tmp, this is not needed on next calls)
2) open the url (passed in a param) in chrome
3) take a screenshot and return its png
1) sets up chrome_headless (on first lambda invoke this will download a zip from s3 containing the chrome binary and extract it to /tmp, this is not needed on next calls)
2) open the url (passed in a param) in chrome
3) take a screenshot and return its png

Here is the test file that updates and invokes the lambda function
note the payload variable (that now passes in an url), and save_png command that will save png data into the file path provided
note the payload variable (that now passes in an url), and save_png command that will save png data into the file path provided

By saving the png locally we get an easy way to see what is happening in the headless chrome (running in the lambda function)

All this (including the installation) happened in 5 seconds :)

if we comment the update_lambda method and just invoke the lambda function

the chrome execution will happen in 1.6 seconds

that is because there is a bit of time required to send the png to my dev box
running the same command directly in AWS will return the png file in 800ms
running the same command directly in AWS will return the png file in 800ms

one of the really cool features of chrome is the ability to take full page screenshots
Here is the full page of the BBC news
Here is the full page of the BBC news




Although it is really cool and powerful to be able to update a lambda function in a couple seconds and get a screenshot of the execution, when developing a new browser automation capability/script, it is better to actually run the browser locally
The Browser_Page already supports the detection of AWS execution, and when running the same code outside AWS, the full version of Chromium will be used, which give us access to the full Chrome environment (including the Chrome developer tools)
Let's see this in action
Let's see this in action
Without any code changes on the lambda code if we invoke the `run` function directly using

we will get the same workflow (as when running it on a lambda), which is:
- open chrome headless (now locally)
- open the url (in this case google)
- return png of screenshot
- save png locally in /tmp
- open png in pycharm (which monitors file changes and reloads automatically)
- open chrome headless (now locally)
- open the url (in this case google)
- return png of screenshot
- save png locally in /tmp
- open png in pycharm (which monitors file changes and reloads automatically)


The only problem with this approach is that we are starting and closing a new instance of chrome on every request, so to make it faster (and more usable) what we want is to run this with headless=false
which is a parameter you can pass to the `Browser_Page` class
which is a parameter you can pass to the `Browser_Page` class

Running the test again will result in a visible Chromium window to show up

To make it easier and more usable (specially on laptops) I tend to use the Screen Split feature in OSX

to create a UI that looks like this

You can also use the new_page=False to reuse the previous tab
If you don't do this, you either get dozens of tabs (one per execution) or you need to manually close the tab between test executions (which causes context switching)
What is cool with this workflow is the REPL speed
If you don't do this, you either get dozens of tabs (one per execution) or you need to manually close the tab between test executions (which causes context switching)
What is cool with this workflow is the REPL speed

One thing I have not covered (yet) is the ability to run/execute javascript on the webpage before taking the screenshot
THAT is very powerful, since it enables all sorts of amazing workflows: logging in, feeding data to a page, interacting with pages, navigate, and fixing UIs
THAT is very powerful, since it enables all sorts of amazing workflows: logging in, feeding data to a page, interacting with pages, navigate, and fixing UIs
But let's move on to another really powerful workflow created by the ability to run chrome headless in Lambda:
The ability to take screenshots from a locally running webserver
Since lambda is basically just a linux box running python, it is very easy to start a local webserver
The ability to take screenshots from a locally running webserver
Since lambda is basically just a linux box running python, it is very easy to start a local webserver
The next code example is actually more complex than it needs to be (since there are a number of wrappers and util classes that abstract it), but I think it will be easier to understand what is going on if we break it down in parts
(see commit github.com/filetrust/OSBo…)
(see commit github.com/filetrust/OSBo…)
Here is the code that:
- starts chrome locally
- starts a local web server on the current folder (using python http.server)
- opens the main page of the browser
- takes a screenshot and returns the png (base64 encoded)
- starts chrome locally
- starts a local web server on the current folder (using python http.server)
- opens the main page of the browser
- takes a screenshot and returns the png (base64 encoded)

which looks like this
note how what we are seeing is the files that exist on the folder currently running the test (compare the files in highlighted folder on the right, with the contents shown in the browser)
note how what we are seeing is the files that exist on the folder currently running the test (compare the files in highlighted folder on the right, with the contents shown in the browser)

Just to confirm , changing the web_root to `/` will show the files that exist in the root of my current laptop

what is really cool is that we can run the same code in lambda and see what is going on in there
Using the test that updates and invokes the lambda function we get this:
(note that we are now seeing the web page contents via the screenshot returned from the lambda function)
Using the test that updates and invokes the lambda function we get this:
(note that we are now seeing the web page contents via the screenshot returned from the lambda function)

What is also very important is that, from a performance point of view, when not running the update step (i.e. copying the zip to s3 and telling AWS that the lambda function has been updated) the function will run in 1.3 seconds

And if we run the same function directly in Lambda

The conversion takes about 800ms

Just to confirm that it is working as expected, I copy and pasted the result from the lambda execution in the AWS console into the onlinepngtools.com/convert-base64… tool and got the same screenshot
To understand why we see those 3 folders , take a look at the structure of the code in the lambda function (which btw, is the contents of the zip file uploaded to s3 and used by Lambda)

For reference here is the location of the lambda function entry point

What is cool is that we can now navigate up the directory structure and see what kind of files exist in the linux distribution used by lambda
Here is one folder up
Here is one folder up

Here is two folders up (which happens to be the root of the linux distribution)

Here is the contents of the /tmp folder

ok, but what can we do with this?
If you take a look at the osbot_browser folder you will notice a web_root folder
If you take a look at the osbot_browser folder you will notice a web_root folder


which contain a number of folders

which are all sort of UI visualisations

before we continue, let's add the ability to open a particular web page in the browser
note the changes in 8 and 22 of the lambda code
The reason why we have a 404 'Error Response' error is because in the test below I asked to open the page 'aaa'
note the changes in 8 and 22 of the lambda code
The reason why we have a 404 'Error Response' error is because in the test below I asked to open the page 'aaa'

If we now set the page value to 'wardley-maps' we see its directory listing
Note how it matches the files that I have locally on my box (btw if I change those locally files and update the lambda function, those changes will be available in the lambda function)
Note how it matches the files that I have locally on my box (btw if I change those locally files and update the lambda function, those changes will be available in the lambda function)

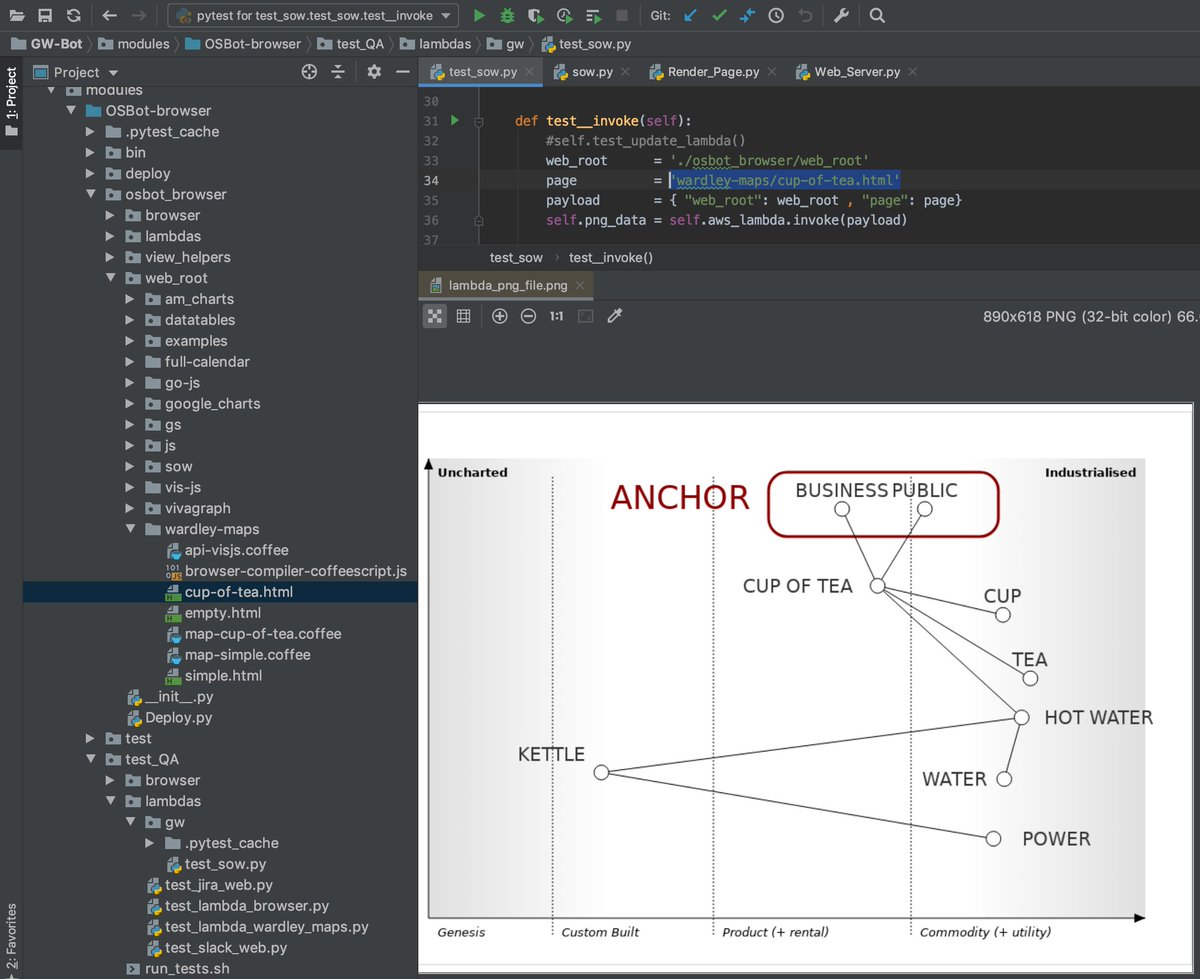
The final step is to open one of the html pages and take a screenshot
in this case, here is the 'wardley-maps/cup-of-tea.html' file which shows the typical example shown by @swardley when explaining wardley maps
in this case, here is the 'wardley-maps/cup-of-tea.html' file which shows the typical example shown by @swardley when explaining wardley maps
to show how we can also manipulate the page from javascript, let's open the same page locally (i.e using a local Python web server and using the local instance of Chromium)

and use the
api_browser.sync__js_execute("alert('hello world')")
function to invoke javascript
api_browser.sync__js_execute("alert('hello world')")
function to invoke javascript

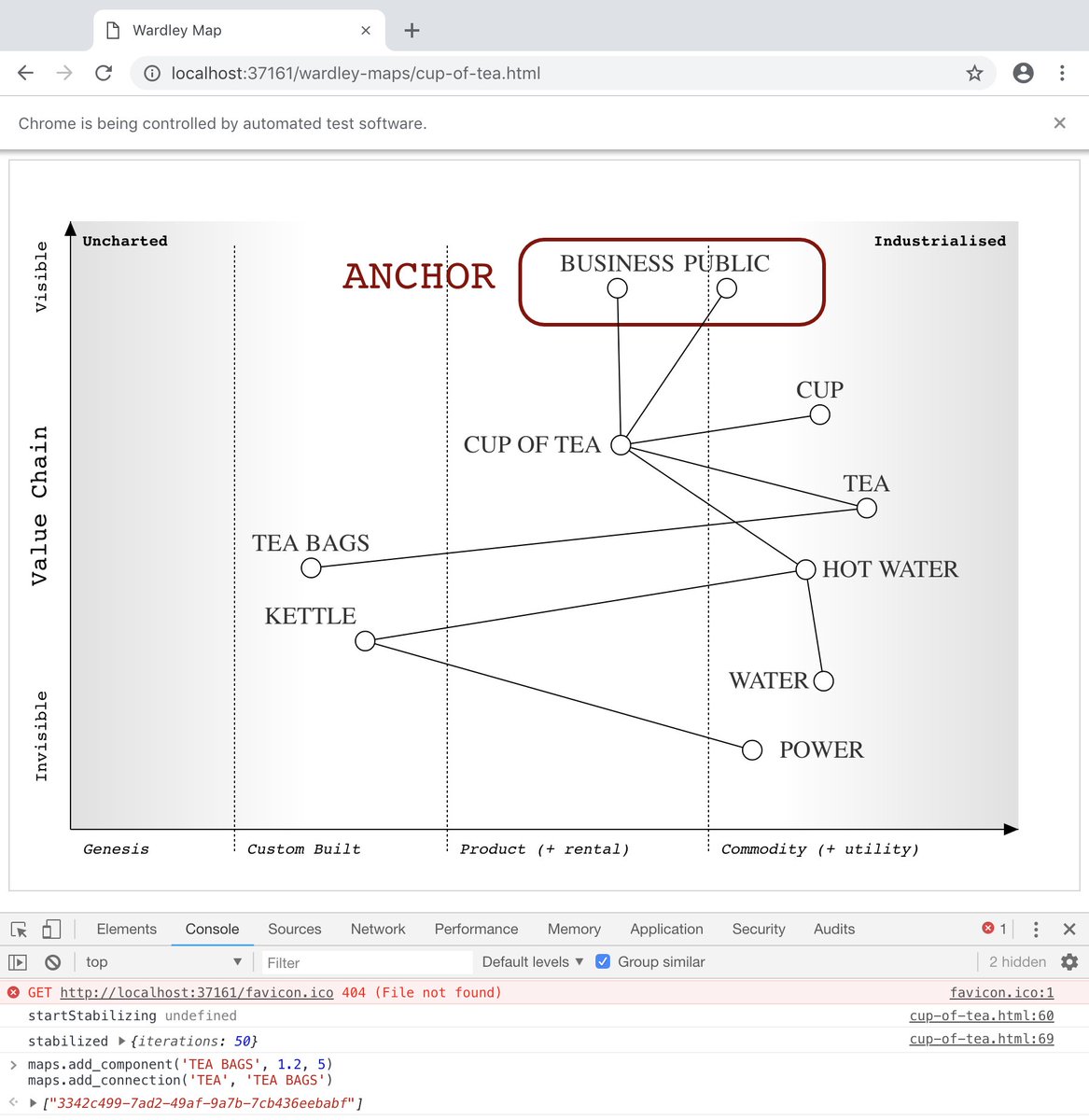
one powerful feature of having Chrome just there, is that we can open up the Javascript console (via Developer tools) and interact with the page
note how in the image below we have access to the 'maps' javascript object in the console
note how in the image below we have access to the 'maps' javascript object in the console

So if we wanted to add a 'TEA BAG' component to the Custom Build stage (and connect it to the TEA component) we can use:
maps.add_component('TEA BAGS', 1.2, 5)
maps.add_connection('TEA', 'TEA BAGS')
@swardley @_tony_richards @HiredThought @madplatt @simonaclifford @Rachel0404
maps.add_component('TEA BAGS', 1.2, 5)
maps.add_connection('TEA', 'TEA BAGS')
@swardley @_tony_richards @HiredThought @madplatt @simonaclifford @Rachel0404
Now that we have the Javascript code needed, let's upgrade the lambda function to support javascript execution

as before, if it runs locally, it will also run in AWS (i.e. the lambda function)
In this case we are adding a 'Tea in Lambda' component
Note how the full loop took 2.1 secs to execute :)
In this case we are adding a 'Tea in Lambda' component
Note how the full loop took 2.1 secs to execute :)

Wrapping up:
So here is how I have been developing lambda functions for the past year, in a super efficient workflow
All code is open sourced as part of the @OWASP Security Bot github.com/owasp-sbot/OSB…
Let me know if you have any questions or need clarification on some steps
So here is how I have been developing lambda functions for the past year, in a super efficient workflow
All code is open sourced as part of the @OWASP Security Bot github.com/owasp-sbot/OSB…
Let me know if you have any questions or need clarification on some steps
@owasp @threadreaderapp unroll