
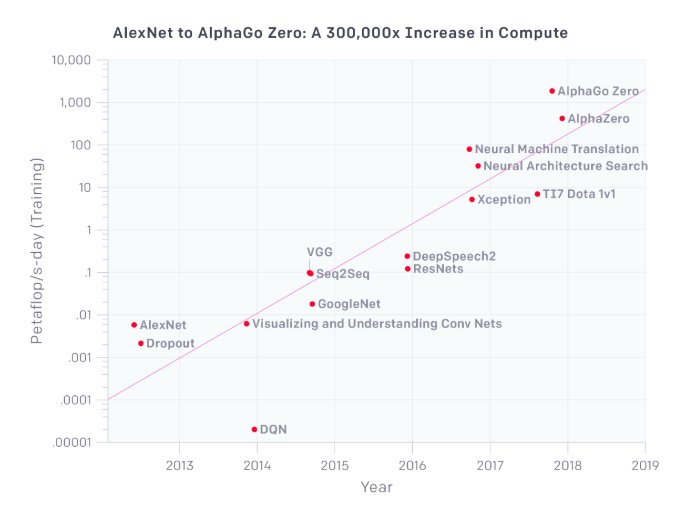
1/ Neural network training complexity has grown 300,000x since 2012. Yet Moore’s Law has only provided 12x more performance. So the question is, where did the extra performance come from? blog.openai.com/ai-and-compute/ @OpenAI 
2/ There are three factors that drive system performance: transistor scaling, chip architecture, and chip count. Let’s see how these have changed since 2012.
3/ Moore’s Law ’75 dictates that transistor per chip doubles every 24 months (not 18!). AlexNet was powered by Fermi GPUs with 3B transistors. Nvidia Volta 2017 is 21B. Transistor scaling gave just a 7x improvement.
4/ Today’s GPUs have dedicated tensor cores, making them far more efficient at DL than classic GPUs. Volta’s 125 TFLOP / Fermi's 1.5 TFLOP = 83x speedup. Divide that by 7 (this takes out Moore’s Law) leaves 12x as the perf improvement from processor architecture.
5/ Lastly, the GPU count has grown massively. AlexNet used two GPUs. Large scale training today uses up to 256. That’s a 128x improvement.
6/ Combing the three factors: 7x (more transistors) * 12x (improved chip architecture) * 128x (more chips) = ~10,000x speedup over five years.
7/ This is within one order of magnitude of the 300,000x number from OpenAI, which is close enough since different neural nets of the same year easily have 10x difference in compute load.
8/ Conclusion: it’s not Moore’s Law sustaining DL compute growth—first it’s just more chips ($$), second it’s better chip architecture, last it’s transistor scaling.



























