
,
49 tweets,
15 min read
Read on Twitter
Coming up: A live Twitter thread of Session 8B: Machine Learning @NAACLHLT with some awesome papers on vocabulary size, subwords, Bayesian learning, multi-task learning, and inductive biases
@NAACLHLT First paper: How Large a Vocabulary Does Text Classification Need?
A Variational Approach to Vocabulary Selection aclweb.org/anthology/N19-…
A Variational Approach to Vocabulary Selection aclweb.org/anthology/N19-…
@NAACLHLT Wenhu:
- Typically need to predefine vocabulary to get embeddings
- Most common approach: frequency-based cutoff; can lead to under-sized or over-sized vocabulary
- Typically need to predefine vocabulary to get embeddings
- Most common approach: frequency-based cutoff; can lead to under-sized or over-sized vocabulary
@NAACLHLT Wenhu: Goals of paper:
1. Importance of vocabulary selection
2. Minimum required vocabulary size
1. Importance of vocabulary selection
2. Minimum required vocabulary size
@NAACLHLT Wenhu: Re 1:
- Sample different vocabulary sizes with fixed budget
- For sample experiment, take 10 different budgets, 100 different combinations for each
- At lower sizes, large difference in performance; at higher sizes, smaller differences
- Sample different vocabulary sizes with fixed budget
- For sample experiment, take 10 different budgets, 100 different combinations for each
- At lower sizes, large difference in performance; at higher sizes, smaller differences
@NAACLHLT Wenhu:
- Vocabulary selection is important in memory-constrained scenarios
Re 2:
- Formulate vocabulary selection as constrained optimization
- Evaluate vocabulary selection using AUC
- Vocabulary selection is important in memory-constrained scenarios
Re 2:
- Formulate vocabulary selection as constrained optimization
- Evaluate vocabulary selection using AUC
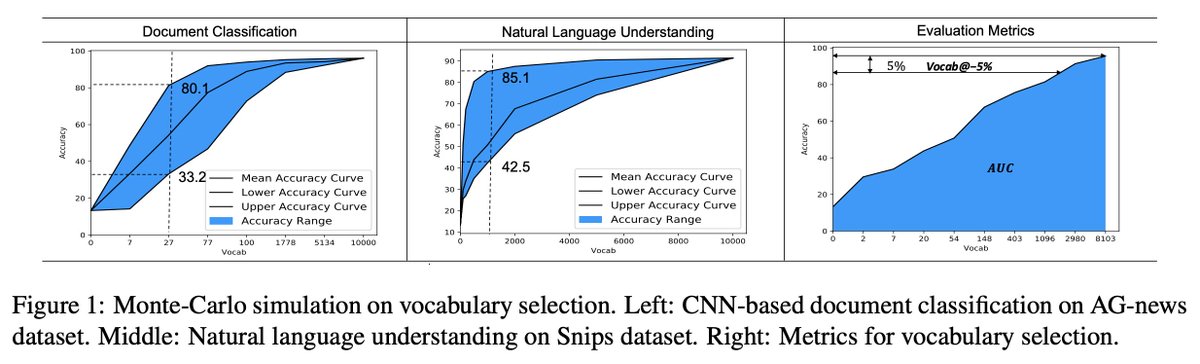
@NAACLHLT Wenhu:
- Objective is not differentiable
- Reinterpret problem in a Bayesian way: Associate a dropout probability with each row of the embedding matrix
- Dropout probability reflects the importance of a given word in the classification task
- Objective is not differentiable
- Reinterpret problem in a Bayesian way: Associate a dropout probability with each row of the embedding matrix
- Dropout probability reflects the importance of a given word in the classification task
@WenhuChen:
- Replace binary masking vector with a Gaussian approximation (sampled from a normal distribution) from nlp.stanford.edu/pubs/sidaw13fa… to reduce variance; optimize a lower bound
- At the end, use all words that have a dropout probability higher than a threshold
- Replace binary masking vector with a Gaussian approximation (sampled from a normal distribution) from nlp.stanford.edu/pubs/sidaw13fa… to reduce variance; optimize a lower bound
- At the end, use all words that have a dropout probability higher than a threshold
@WenhuChen @WenhuChen:
- Evaluate on DBpedia, AG-News, and Yelp
- Frequency-based cut-off is a strong baseline
- Variational dropout works well for reducing the vocabulary size across different budgets
- See the figure below for selected vocabulary sizes on the three tasks
- Evaluate on DBpedia, AG-News, and Yelp
- Frequency-based cut-off is a strong baseline
- Variational dropout works well for reducing the vocabulary size across different budgets
- See the figure below for selected vocabulary sizes on the three tasks

@WenhuChen @WenhuChen:
- Pros: compared to subword methods, can be applied to languages, which cannot be directly decomposed into characters/subwords
- Cons: loss of information due to reduced vocab size
- Pros: compared to subword methods, can be applied to languages, which cannot be directly decomposed into characters/subwords
- Cons: loss of information due to reduced vocab size
@WenhuChen Overall, a creative approach to deal with a somewhat under-studied but fundamental aspect of common NLP tasks, the vocabulary size. Would be cool to see if similar findings apply to subword-based vocabularies.
@WenhuChen In a nice segue, we now move from words to subwords for our second paper:
Subword-based Compact Reconstruction of Word Embeddings aclweb.org/anthology/N19-…
Subword-based Compact Reconstruction of Word Embeddings aclweb.org/anthology/N19-…
@WenhuChen Shota Sasaki:
- Introduce novel word embeddings, which are open-vocabulary and compact
- They achieve better performance on word similarity and similar performance on downstream tasks with fewer memory
- Introduce novel word embeddings, which are open-vocabulary and compact
- They achieve better performance on word similarity and similar performance on downstream tasks with fewer memory
In a picture:

Shota:
- Related work (Zhao et al., EMNLP 2018): Bag-of-subwords reconstructs pretrained word embeddings to support OOV words by summing up subword embeddings obtained through the reconstruction
- Related work (Zhao et al., EMNLP 2018): Bag-of-subwords reconstructs pretrained word embeddings to support OOV words by summing up subword embeddings obtained through the reconstruction
Shota:
- Cons of this approach: Large # of subword embeddings blows up memory size of model
- Two key ideas of approach:
1. A subword-to-memory mapping function
2. A subword mixing function
- Cons of this approach: Large # of subword embeddings blows up memory size of model
- Two key ideas of approach:
1. A subword-to-memory mapping function
2. A subword mixing function
Shota: Re 1.: propose different strategies:
- discard infrequent subwords (use only top-k most frequent ones)
- memory sharing: randomly share vectors between subwords as in arxiv.org/pdf/1607.04606…
- combine first two methods
- discard infrequent subwords (use only top-k most frequent ones)
- memory sharing: randomly share vectors between subwords as in arxiv.org/pdf/1607.04606…
- combine first two methods
Shota: Re 2:
- don't use summation for combining subwords;
- use key-value attention; crucially, has a context-dependent weighting factor
- pros: highly expressive (enables using a lower weight for an unrelated subword); does not require a separate transformation matrix
- don't use summation for combining subwords;
- use key-value attention; crucially, has a context-dependent weighting factor
- pros: highly expressive (enables using a lower weight for an unrelated subword); does not require a separate transformation matrix
Shota:
- evaluate on word similarity, model compression, NER, and textual entailment
- Method outperforms comparison methods; performance on word similarity, NER, and TE is close to full fastText with a lot less memory (0.6 GB vs. 2.2GB)
- evaluate on word similarity, model compression, NER, and textual entailment
- Method outperforms comparison methods; performance on word similarity, NER, and TE is close to full fastText with a lot less memory (0.6 GB vs. 2.2GB)
We slightly shift gears and move from the low-memory to the low-data regime with our third paper:
Bayesian Learning for Neural Dependency Parsing aclweb.org/anthology/N19-…
The paper proposes a Bayesian parser that performs particularly well with a small number of samples.
Bayesian Learning for Neural Dependency Parsing aclweb.org/anthology/N19-…
The paper proposes a Bayesian parser that performs particularly well with a small number of samples.
A recorded presentation by Ehsan Shareghi.
Ehsan:
- Big picture view of supervised learning: lots of parameters, many languages only have a small amount of data; most models use Maximum Likelihood Estimation
Ehsan:
- Big picture view of supervised learning: lots of parameters, many languages only have a small amount of data; most models use Maximum Likelihood Estimation
Ehsan:
- Cons: can lead to overfitting and poor generalization; ignores uncertainty and model is over-confident
- Solution in this paper: a Bayesian approach (to learning and inference)
- Cons: can lead to overfitting and poor generalization; ignores uncertainty and model is over-confident
- Solution in this paper: a Bayesian approach (to learning and inference)
Ehsan:
- Parsing setup in this paper: a first-order factorized graph-based parser (score of a tree is decomposed into a summation of arcs in tree)
- Use BiLSTM to assign scores using Kiperwasser & Goldberg parser aclweb.org/anthology/Q16-…
- Parsing setup in this paper: a first-order factorized graph-based parser (score of a tree is decomposed into a summation of arcs in tree)
- Use BiLSTM to assign scores using Kiperwasser & Goldberg parser aclweb.org/anthology/Q16-…
Ehsan:
- Bayesian approach: learn posterior distribution over parameters of model; problem: integration is intractable; need to approximate
- main problem: need to sample efficiently from the posterior (approximate integration with Monte Carlo samples / summation)
- Bayesian approach: learn posterior distribution over parameters of model; problem: integration is intractable; need to approximate
- main problem: need to sample efficiently from the posterior (approximate integration with Monte Carlo samples / summation)
Ehsan:
- derive gradient via stochastic gradient langevin dynamics (looks similar to SGD + Gaussian noise) from ics.uci.edu/~welling/publi…
- derive gradient via stochastic gradient langevin dynamics (looks similar to SGD + Gaussian noise) from ics.uci.edu/~welling/publi…
Derivation:

Ehsan:
- for prediction, we can get multiple samples to compute the structure with the minimum Bayes risk
- model consistently improves over MLE estimation; ensembling both performs even better
- gains are highest on datasets with small numbers of examples
- for prediction, we can get multiple samples to compute the structure with the minimum Bayes risk
- model consistently improves over MLE estimation; ensembling both performs even better
- gains are highest on datasets with small numbers of examples
Ehsan:
- For small numbers of samples, introducing prior knowledge via a prior over parameters can be useful.
- Dropout (with more training data) can be used to get some of the benefits of the Bayesian approach
- For small numbers of samples, introducing prior knowledge via a prior over parameters can be useful.
- Dropout (with more training data) can be used to get some of the benefits of the Bayesian approach
For our fourth paper, we'll also leverage a Bayesian approach, but in the context of Bayesian optimization for multi-task learning:
AUTOSEM: Automatic Task Selection and Mixing in Multi-Task Learning
aclweb.org/anthology/N19-…
AUTOSEM: Automatic Task Selection and Mixing in Multi-Task Learning
aclweb.org/anthology/N19-…
Han Guo:
- In multi-task learning (MTL), we use information from related tasks to improve generalization performance
- Two issues of MTL:
1. Auxiliary task selection: difficult to choose aux task
2. Mixing ratio learning: how to determine the task weights
- In multi-task learning (MTL), we use information from related tasks to improve generalization performance
- Two issues of MTL:
1. Auxiliary task selection: difficult to choose aux task
2. Mixing ratio learning: how to determine the task weights
Han:
- Propose AutoSeM:
1. use a multi-armed bandit for auxiliary task selection; and
2. Bayesian optimization based on Gaussian processes for mixing ratio learning
- Propose AutoSeM:
1. use a multi-armed bandit for auxiliary task selection; and
2. Bayesian optimization based on Gaussian processes for mixing ratio learning

Lots of related work:

Han:
- standard setup for multitask learning; model uses ELMo embeddings, has different task-specific output layers
- standard setup for multitask learning; model uses ELMo embeddings, has different task-specific output layers

Han:
- frame task selection as a multi-armed bandit; each task has a utility (prior is parameterized by Beta distribution)
- for every task, sample from Beta distribution; use task that maximizes sampled value
- train model on that task; reward is 1 if performance improves
- frame task selection as a multi-armed bandit; each task has a utility (prior is parameterized by Beta distribution)
- for every task, sample from Beta distribution; use task that maximizes sampled value
- train model on that task; reward is 1 if performance improves
In a picture:

Han:
- for learning the mixing ratio, use Bayesian optimization based on a Gaussian process (very sample-efficient)
- use samples of mixing ratios to train model; get performance at the end of training as target value and update GP; sample new mixing ratios and train again, etc.
- for learning the mixing ratio, use Bayesian optimization based on a Gaussian process (very sample-efficient)
- use samples of mixing ratios to train model; get performance at the end of training as target value and update GP; sample new mixing ratios and train again, etc.
Han:
- for results, model outperforms single-task and standard multi-task baseline
- in terms of aux tasks, MultiNLI is always chosen as aux task (has a lot of data, useful pretraining task); MultiNLI sometimes gets low mixing ratio in second stage, though
- for results, model outperforms single-task and standard multi-task baseline
- in terms of aux tasks, MultiNLI is always chosen as aux task (has a lot of data, useful pretraining task); MultiNLI sometimes gets low mixing ratio in second stage, though
Han:
- visualization of task utility reveals that for the primary task SST-2, the model assigns the highest utility to this task (which makes sense intuitively)
- visualization of task utility reveals that for the primary task SST-2, the model assigns the highest utility to this task (which makes sense intuitively)

For the last paper of our session, we have a systematic study of the inductive biases of RNNs across (synthetic) languages:
Studying the Inductive Biases of RNNs
with Synthetic Variations of Natural Languages
aclweb.org/anthology/N19-…
Studying the Inductive Biases of RNNs
with Synthetic Variations of Natural Languages
aclweb.org/anthology/N19-…
Shauli Ravfogel @ravfogel:
- Main goals: study how RNNs acquire syntax, whether they find some syntactic features more challenging, and whether we can isolate some of these features
- For evaluation, use agreement prediction (e.g. between subject and verb)
- Main goals: study how RNNs acquire syntax, whether they find some syntactic features more challenging, and whether we can isolate some of these features
- For evaluation, use agreement prediction (e.g. between subject and verb)
@ravfogel:
- agreement prediction was first done in arxiv.org/abs/1611.01368 for English
- follow-up work showed comparable or better results in other languages
- but: languages are diverse and vary across many levels -> not clear how inductive biases vary across typologies
- agreement prediction was first done in arxiv.org/abs/1611.01368 for English
- follow-up work showed comparable or better results in other languages
- but: languages are diverse and vary across many levels -> not clear how inductive biases vary across typologies
@ravfogel:
- Previous work: case study on Basque arxiv.org/abs/1809.04022
- LSTMs perform substantially worse on Basque
-> unclear what caused these disparities
- Previous work: case study on Basque arxiv.org/abs/1809.04022
- LSTMs perform substantially worse on Basque
-> unclear what caused these disparities
@ravfogel:
- naive option would be to just compare raw performance; however: not clear how to compare as languages are challenging in different ways
- main idea: generate artificial variations of existing languages
- naive option would be to just compare raw performance; however: not clear how to compare as languages are challenging in different ways
- main idea: generate artificial variations of existing languages

@ravfogel:
- for polypersonal agreement, lower performance on object vs. subject prediction; jointly predicting of subject and object works best
- for polypersonal agreement, lower performance on object vs. subject prediction; jointly predicting of subject and object works best
Creating corpus with different word orders requires repeatedly swapping complements

@ravfogel:
- word order matters: performance is higher in subject-verb-object order (as in English) than in subject-object-verb order (as in
Japanese) languages
- case marking significantly helps performance and facilitates agreement prediction
- word order matters: performance is higher in subject-verb-object order (as in English) than in subject-object-verb order (as in
Japanese) languages
- case marking significantly helps performance and facilitates agreement prediction
@ravfogel: Key takeaway: not all languages are English! Work on non-English languages to be able to accurately characterize how your model behaves.












