
Kicked off @AWSreInvent 2019 by attending @houlihan_rick’s @DynamoDB modeling session. As expected, it was a 60 minute firehose of #NoSQL knowledge bombs. There was *A LOT* to take away from this, but here are some really interesting lessons that stuck out to me. #reInvent 

DynamoDB performance gets BETTER with scale. Yup, you read that correctly, the busier it gets, the faster it gets. This is because, eventually, every event router in the fleet caches your information and doesn’t need to look up where your storage nodes are.

Big documents are a bad idea! It’s better to split data into multiple items that (if possible) are less than 1 WCU. This will be a lot cheaper and cost you less to read and write items. You can join the data with a single query on the partition key.

You don’t want to denormalize highly mutable data. Data that is likely to change often should probably be referenced, which can then be retrieved with a separate query (when necessary). Immutable data (like DOB, name, email, etc.) can be denormalized for optimizing data shapes.

Don’t use auto-generated primary keys as partitionKeys if they are not used by your primary access pattern. If your application doesn’t use those ids directly, then you are creating a "dead index" and you need to create additional GSIs to index meaningful references. Forget 3NF!
Avoid running aggregation queries, because they don’t scale. Use DynamoDB streams to process data and write aggregations back to your DynamoDB table and/or other services that are better at handling those types of access patterns.
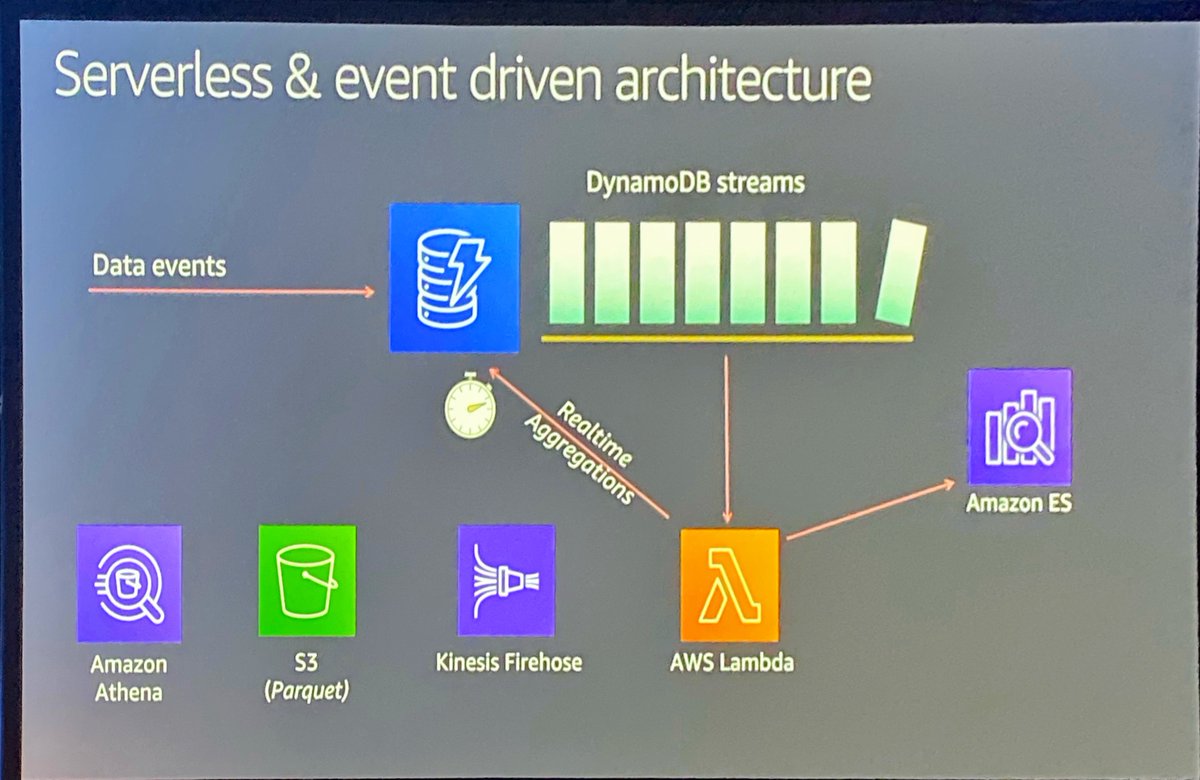
Build idempotency into your DynamoDB stream processors. DynamoDB streams + Lambda = decoupled stored procedures. DDB Streams *guarantee* “at-least-once” delivery, which means your Lambda *could* receive the same event twice. Plan for that.
When you need to add a new access pattern, "You don’t necessarily have to remodel everything and throw the baby out with the bathwater.” ~ @houlihan_rick. Run an ETL and decorate some existing items or change some values. Maybe add a new index.
When possible, push certain logic down to the client. Rather than filtering out old versions or calculating availability by diff’ing existing items, let the client do that math instead of your application layer. #RickProTip
Use write sharding to store large indexes with low cardinality. Rick gave the example of languishing support tickets. Write these to multiple partitions on a GSI and then use a once-a-day look up to decorate other items. Parallelization is an added benefit. 👊
Use an attribute versioning pattern to store deltas for large items with minimal changes between mutations. Don’t duplicate a massive item every time some small part changes. Instead, store each attribute as an item with the same partitionKey.

Use NoSQL Workbench for DynamoDB. You can model your table, add indexes, and pivot your data visualizations. Plus, Rick uses it to model his tables and create the diagrams for his slide decks. Do you really need another reason?

Your workload most likely fits into a single DynamoDB table. Rick's latest example shows 23 access patterns using only *THREE* GSIs. Is it easy? Not really. Can it be done? Yes, and I have faith in you. #SingleTableForEveryone
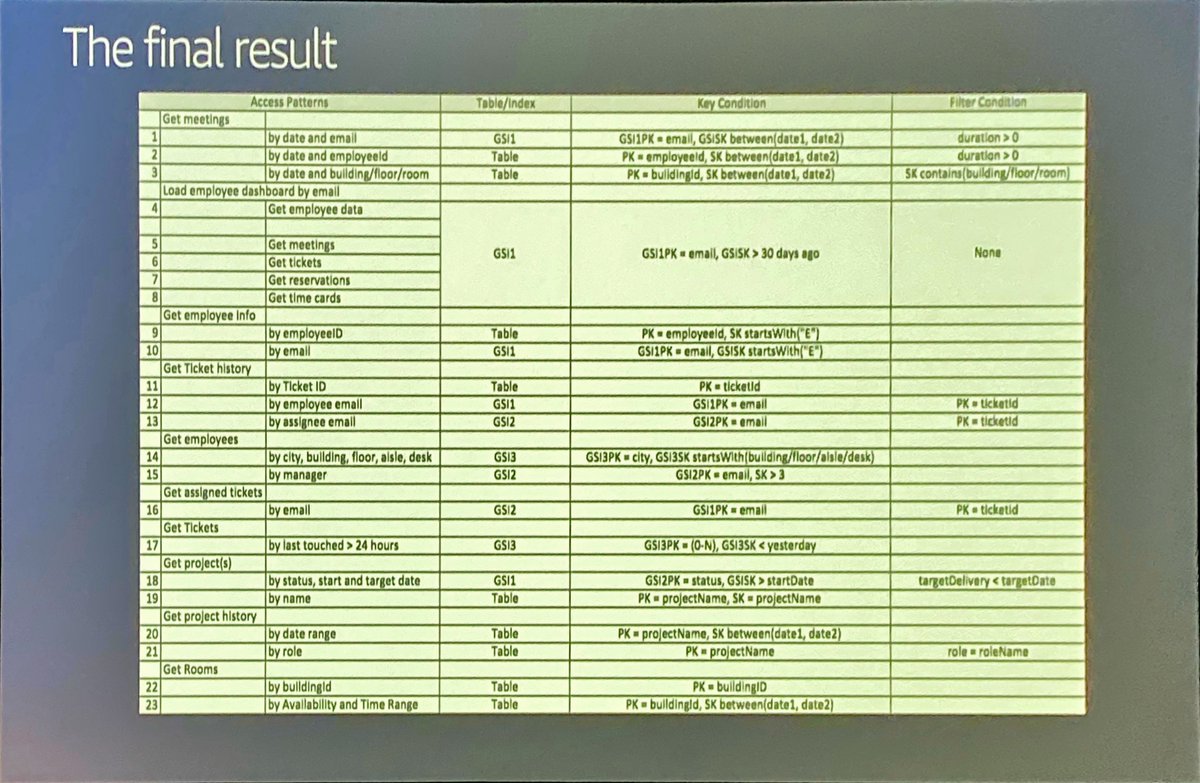
Looking forward to the video of this talk being posted so that I can go through his examples in excruciating detail. And if you’ve not yet jumped into the DynamoDB pool, come on in, the water is fine! 🏊♂️ #NoSQL modeling is going to be a hugely valuable skill. Make 2020 your year!
And if you need some extra help working with DynamoDB, check out my open source project at dynamodbtoolbox.com.







