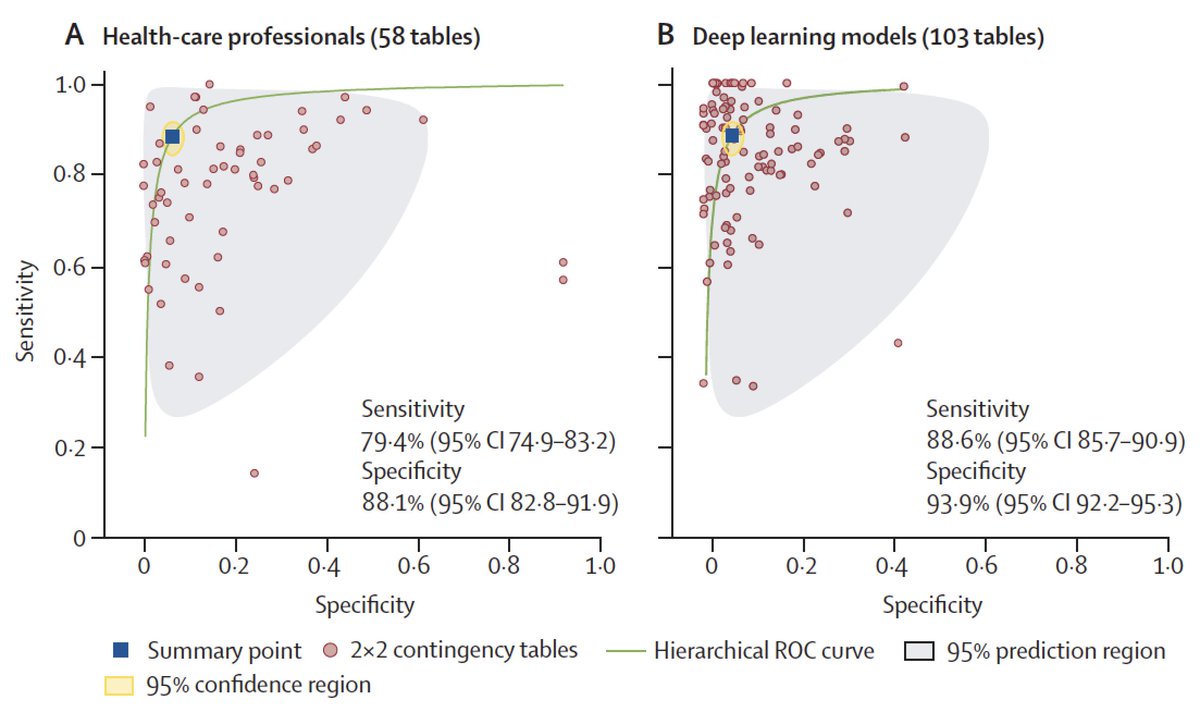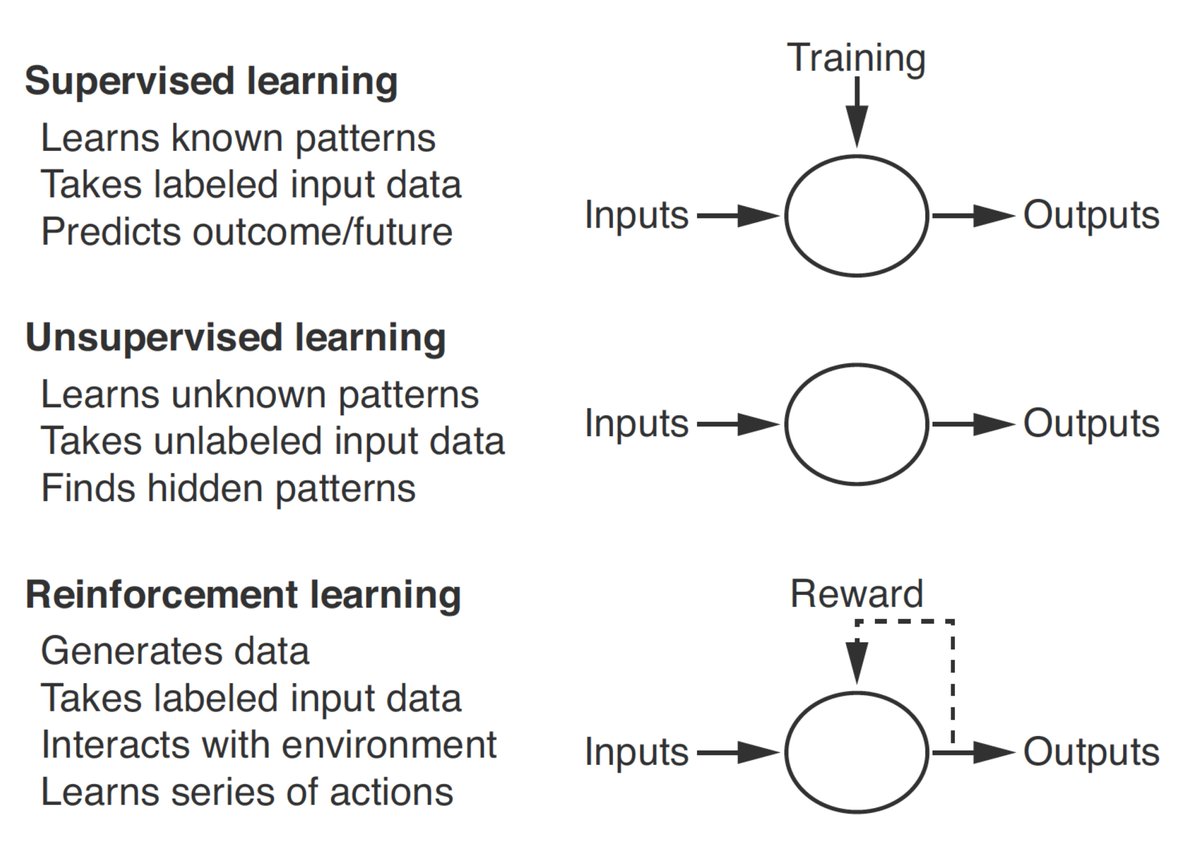
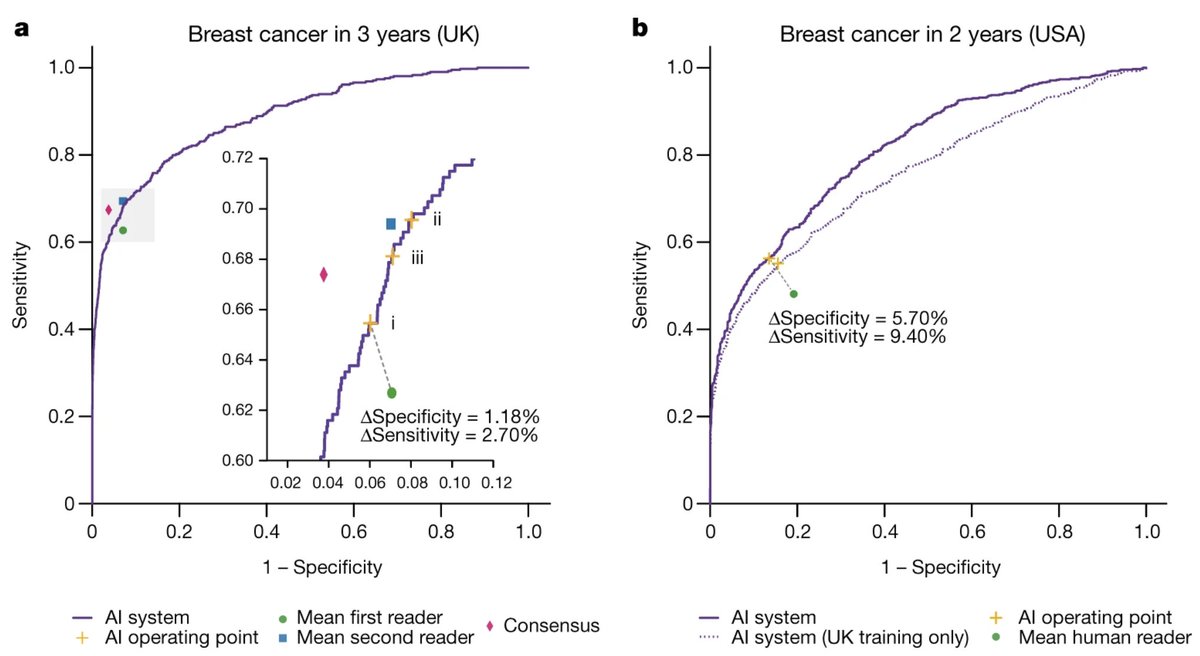
Very excited to share nature.com/articles/s4158… where we show an AI system that outperforms specialists at detecting breast cancer during screening in both the UK and US. Joint work with @GoogleHealth and @CR_UK published in @Nature today! 

@GoogleHealth @CR_UK @nature In AI health work it’s common to see claims about AI performing tasks at or above human performance, so I want to give my perspective on this to contextualize our results. 1/16
@GoogleHealth @CR_UK @nature A task can be defined by a dataset and a metric. Additionally when we (researchers) describe results, e.g. “detect cancer better than experts”, it highlights another critical aspect: baseline/human performance. 2/16
There is a “many-to-one” mapping of tuples (dataset, metric, baseline) to people’s summary of results such as “detect cancer better than experts”. Crucially, there can be very different such tuples although over time the field slowly agrees on invalidating some of these. 3/16
That agreement to invalidate such mappings is because there is consensus the summary would not hold in clinical practice. Finding the most robust tuple (dataset, metric, baseline) is very difficult and is what I personally (with collaborators) spent most of my time on. 4/16
Each of (dataset, metric, baseline) is critical in understanding the actual clinical impact of results. Seemingly small details can completely change the impact to the point where many feel the summary is invalid (will not translate in practice). 5/16
Unfortunately that means to fully understand work in AI health, you need to delve quite deep. Examples of what invalidates the mapping for my interpretation (things I look out for): dataset is artificially constructed (“let’s find 100 examples of cancer”), … 6/16
… dataset has unreasonable exclusion criteria, dataset is not randomly sampled from a clinical pathway, baseline performance is post-hoc, ground truth for metric is biased, etc. There are loads and, some can be very subtle. 7/16
Concretely about this for our paper: 1. Datasets: the UK dataset (from @CR_UK) is a representative sample directly from breast screening, we have spent a very large amount of time doing this thoroughly. 8/16
The US dataset represents a different type of screening program (1-2 years screening, single reader). The supplementary data has plenty of tables and statistics to reveal the level of detail that is hidden away. 9/16
2. Metric: we look at biopsy proven cancer within 39 months (UK) and 27 months (US). We say it’s not cancer when we have at least one follow-up visit confirming this. These definitions are not trivial -- and there is a lot of nuance -- …. 10/16
… it’s the result of countless hours of discussions with both ML and clinical collaborators. 3. Baseline performance: for the UK we have the _original_ decisions from the radiologists, together with the results of arbitration if relevant. 11/16
We can basically compare directly by putting the AI system in the exact same part of the clinical pathway: woman comes for screening, radiologist(s) decide if follow-up is needed vs AI decides if follow-up is needed. It’s similar for the US but we also provide another eval. 12/16
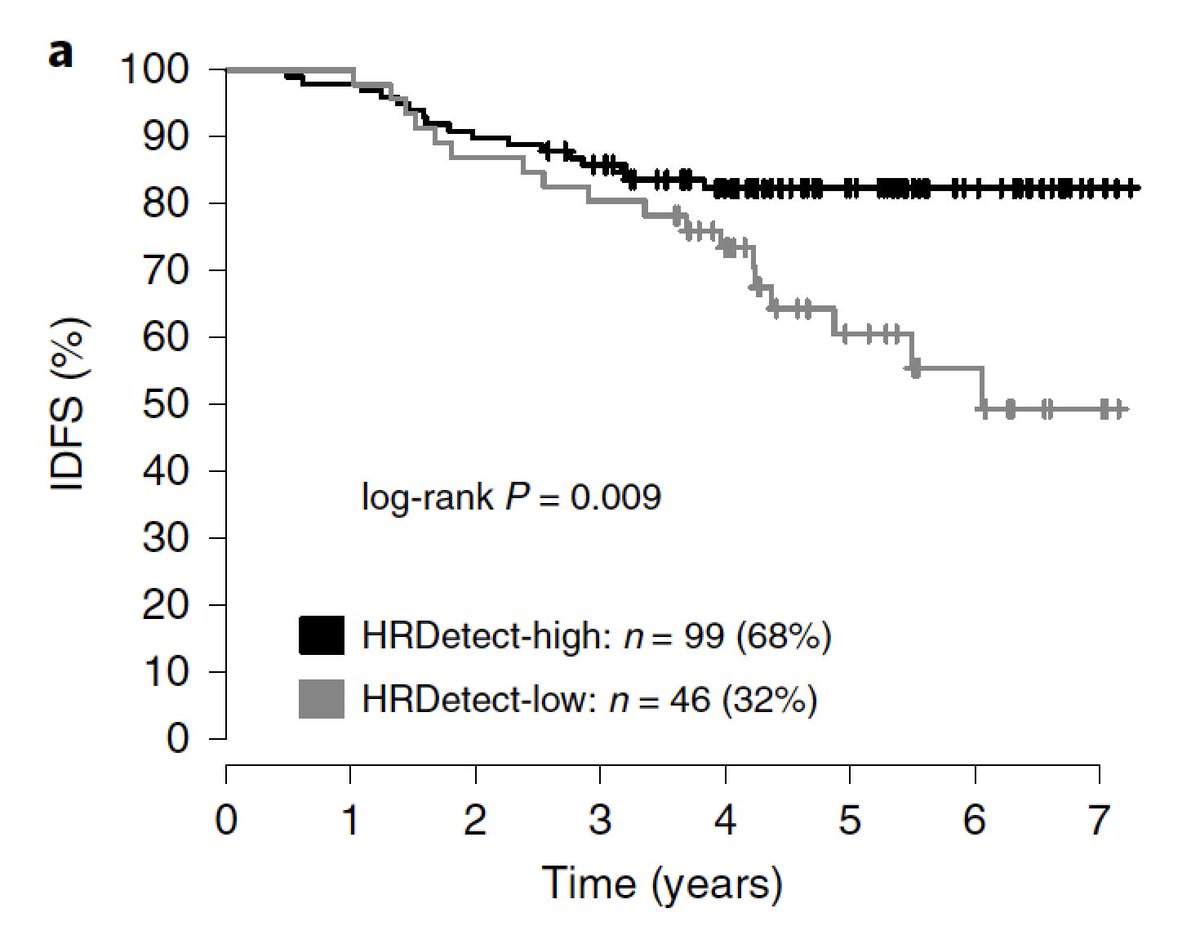
Note a subtlety: the radiologists are “gatekeepers” for further investigation. This means that if they don’t follow up, there is no possibility to confirm any malicious mass. We discuss this more in e.g. Extended Data Fig 4. 13/16
We also show a reader study on the US dataset -- performed by an external research organization, which is specialized to do clinical trials and evaluations. There is plenty more detail that is obfuscated by the technical language of a paper, I’ve tried to uncover some. 14/16
In the end, for AI health we need well-designed clinical trials to validate performance but this takes time. Note that these clinical trials _still_ have to think about a very similar (dataset, metric, baseline). 15/16
Even given all these nuances, I’m still convinced that AI will have a strong positive impact on our lives, of which health will be an important aspect. I hope our work can contribute to that in the longer-term! 16/16