,
51 tweets,
27 min read
Read on Twitter
1/ This is a really interesting Tweet by @crispinhunt regarding #Article13, and he may regret making it:
2/ so much so that here's a screenshot for posterity 

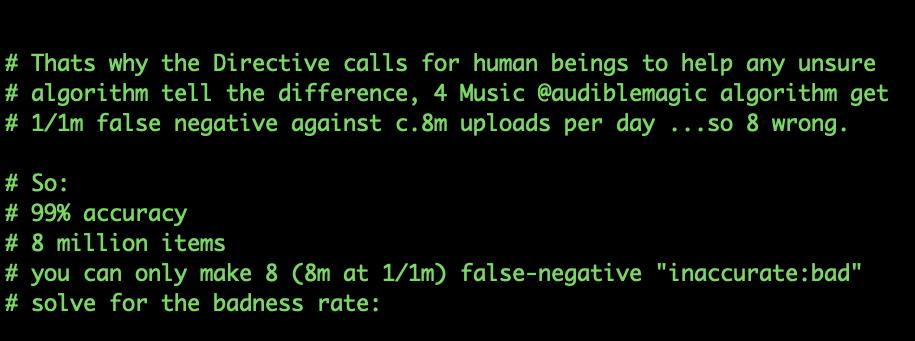
3/ the reason that this is interesting is that it allows us to reverse-engineer the "badness" rate - the rate of infringing content uploads - that the copyright lobby's own people believe is occurring.
4/ so, @crispinhunt says that:
- there's a test accuracy of 99%
- 8 million items
- resulting in 8 (ie: 8m at 1/1m) false-negatives
...solve this equation for the "badness" rate
Fortunately we can plug this into the code and run it until we see ~ 8 "inaccurate:bad" results
- there's a test accuracy of 99%
- 8 million items
- resulting in 8 (ie: 8m at 1/1m) false-negatives
...solve this equation for the "badness" rate
Fortunately we can plug this into the code and run it until we see ~ 8 "inaccurate:bad" results


@crispinhunt @Senficon 6/ copyright infringement, according to the copyright industry's _own_ figures, occurs at a rate of about 1 in 10,000 uploads. That's 0.01% of uploads.
They are trying to get #Article13 imposed on the internet for 0.01% of uploads.
They are trying to get #Article13 imposed on the internet for 0.01% of uploads.
@crispinhunt @Senficon 7/ But apparently copyright infringement is endemic?
@crispinhunt @Senficon 8/ Again, if you want to try this at home:
@crispinhunt @Senficon 9/ Source for the 99% accuracy is the software provider themselves; @mmasnick will probably enjoy the above thread:
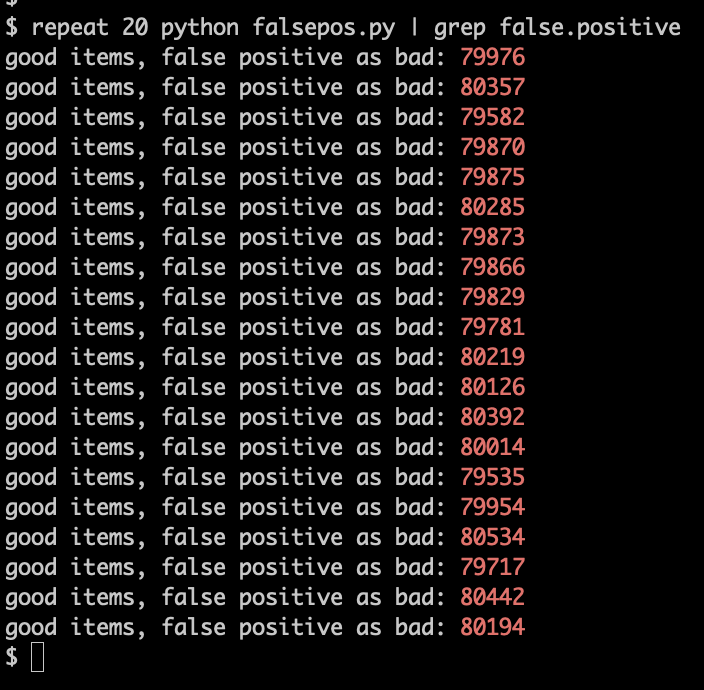
@crispinhunt @Senficon @mmasnick 10/ Oh yeah, and the representative false-positive rate for the same scenario?
Those 8 false-negatives (ie: infringers you missed) are balanced by about 80,000 false-positives (ie: innocent people you squelched)
Those 8 false-negatives (ie: infringers you missed) are balanced by about 80,000 false-positives (ie: innocent people you squelched)
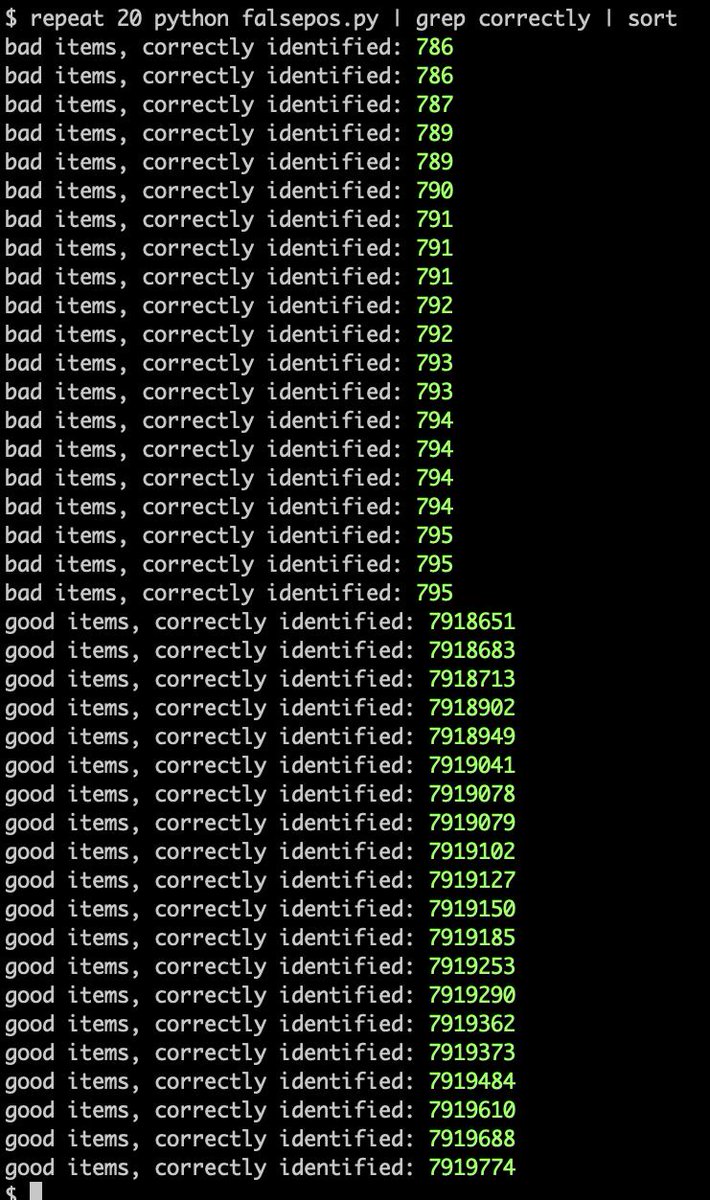
@crispinhunt @Senficon @mmasnick 11/ numbers for the rest of the simulation:
- 7.9 million correct-and-proper non-infringing posts
- 80,000 erroneous takedowns of non-infringing content
- about 800 correct-and-proper takedowns
- 8 infringements missed
This is the true cost & impact of #Article13
- 7.9 million correct-and-proper non-infringing posts
- 80,000 erroneous takedowns of non-infringing content
- about 800 correct-and-proper takedowns
- 8 infringements missed
This is the true cost & impact of #Article13
@crispinhunt @Senficon @mmasnick 12/ This math is straight out @crispinhunt's twitter, and he's "Songwriter / Studio Producer / Musicians Advocate / Chair of @BASCA_uk" - and I am presuming that he has confused false-negative (infringements that were missed) with false-positives (innocents who were caught) >>
13/ << … and that (in such mistaken-ness) decided to tweet the nice low number (8 vs: 80,000) in support of his argument.
Fortunately he gave it the correct name.
Fortunately he gave it the correct name.
14/ One might suppose that the fact that he cited the "false-negative" rate may suggest that @audiblemagic have been pitching to the music/copyright industry on the basis of "how few violators the filters *miss*" rather than "how many innocents the filters *hit*"
@audiblemagic 15/ One might also suppose that the citation suggests that
@crispinhunt wasn't entirely clear on the difference between the two figures, either.
@crispinhunt wasn't entirely clear on the difference between the two figures, either.
@audiblemagic @crispinhunt 16/ Just to prove there's nothing up my sleeve, here's the code-change I made; I am a bit surprised that I originally guessed a rate of 1-in-10,000, but it's nice for @BASCA_uk to give us confirmation
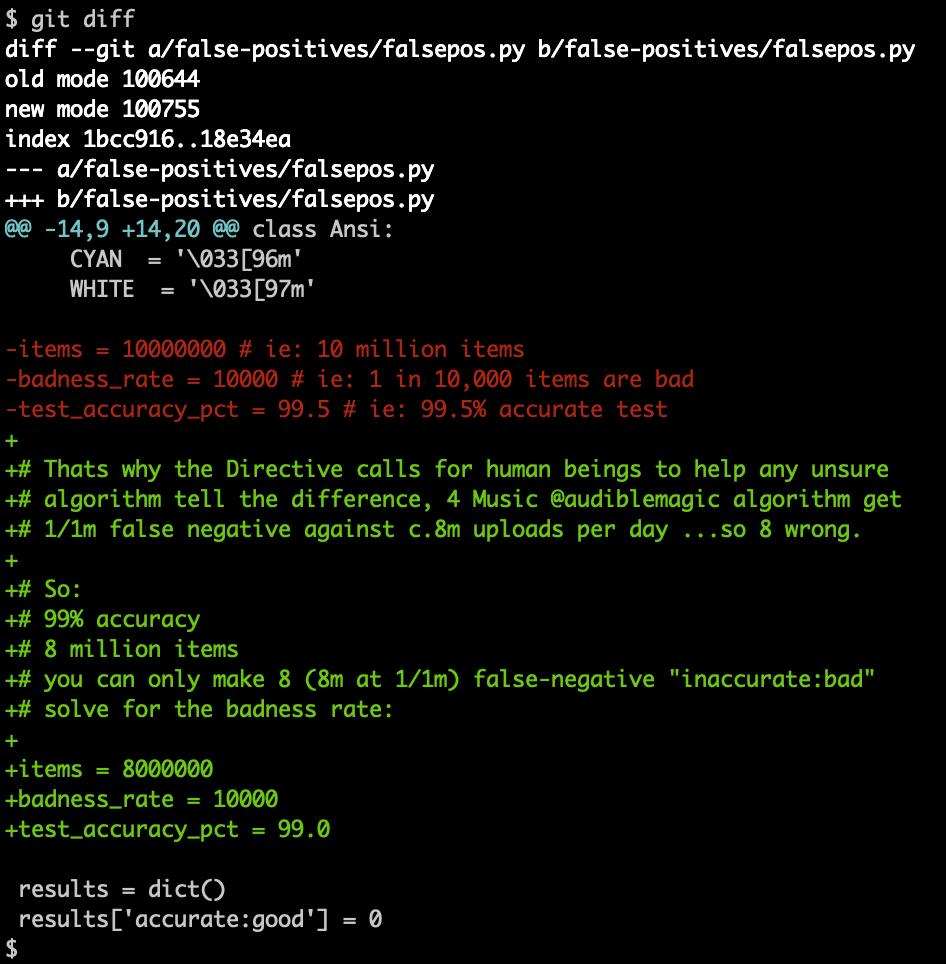
@audiblemagic @crispinhunt @BASCA_uk 17/ Just in case someone wants to ask:
'What if @crispinhunt was not mistaken, and was actually saying there were 8 false _positives_ on 8 million uploads?'
Well … with a 99% accuracy rate, that's not really feasible; the FP rate is a function of the test accuracy (cont…)
'What if @crispinhunt was not mistaken, and was actually saying there were 8 false _positives_ on 8 million uploads?'
Well … with a 99% accuracy rate, that's not really feasible; the FP rate is a function of the test accuracy (cont…)
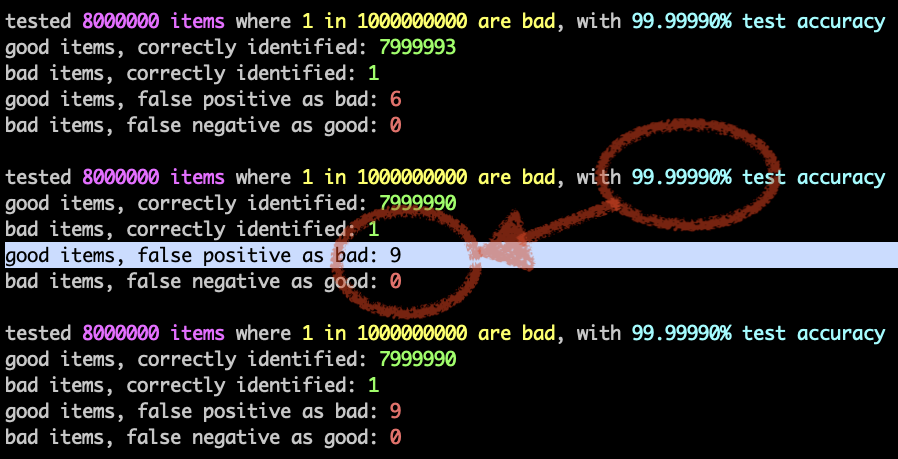
18/ Even in a situation (see pic) where the rate of infringing content is close to zero, at 99% accuracy you will still miscategorise 1% of peoples' non-infringing uploads as being badness.

19/ to fix the false-positive rate, you would have to raise the test accuracy to 99.9999% — which the software vendor itself, rebuts; they only claim 99%.
This is why I think @crispinhunt cited a correct number with its correct name, erroneously.
This is why I think @crispinhunt cited a correct number with its correct name, erroneously.
@crispinhunt 20/ Whether @audiblemagic can actually _deliver_ on the stated 99% accuracy, is a question for people who deploy the software.
@crispinhunt @audiblemagic 21/ Okay, let's stretch this further: previously I've written an essay on content-filtering by human beings, on facebook, trying to block abusive and violent images: medium.com/@alecmuffett/a…
22/ in that essay, I came up with some numbers on cost of review; let's apply those costs to this situation:

23/ in that essay I was talking about visual assessment of content, and said it would take 6 seconds to assess an object; for copyright infringement it will take a lot longer, but let's run with those numbers for a moment.

24/ we have
- 80,000 appeals per day
- 4,800 appeal reviews per person per day
- 80000 / 4800 = 16.67 = 17 review staff on 8h shifts
Assume wage = $10/h
17 staff * 8 hours * $10 * 365 days/year == $496,400
So: about $500k in wages for content reviewers?
- 80,000 appeals per day
- 4,800 appeal reviews per person per day
- 80000 / 4800 = 16.67 = 17 review staff on 8h shifts
Assume wage = $10/h
17 staff * 8 hours * $10 * 365 days/year == $496,400
So: about $500k in wages for content reviewers?
25/ However: copyright reviews are probably not going to be completed at a rate of 1 every six seconds, per the original model.
Say it takes 60 seconds / 1 minute per review; then your appeal-review wage cost is $5 million per annum.
Say it takes 60 seconds / 1 minute per review; then your appeal-review wage cost is $5 million per annum.
26/ …that's not even paying for resources, training, equipment, food, heating, or even bathroom breaks. Tell me again how small websites are going to afford this sort of thing, take this kind of cost in their stride, to inhibit 0.01% of uploads which may infringe copyright?
27/ You could of course say "machine learning can help reduce this wage bill" — but one should point out that this is the irreducible cost of the Human review process.
This is literally the #Article13-lobby's proposed *mitigation* to machine-learning's failures.
This is literally the #Article13-lobby's proposed *mitigation* to machine-learning's failures.
@mmasnick 29/ there's also this marvellous tweet by @crispinhunt :-
In terms of spin, it's quite clever.
In terms of spin, it's quite clever.
@mmasnick @crispinhunt 30/ for one thing: "simple" math is likely correct, and I hope that people reading this have been able to follow along.
Secondly: the math suggests 80k errors PER DAY, and so we get annually: 80,000 * 365 = 29,200,000 erroneous takedowns.
Secondly: the math suggests 80k errors PER DAY, and so we get annually: 80,000 * 365 = 29,200,000 erroneous takedowns.
31/ Those 29 million erroneous takedowns per year he says are in defence of 2 million creative artists — a figure that presumably represents his entire pan-European bailiwick. But I'll speculate that the majority of those 2 million are not popular enough to be infringed-upon.
32/ the question then, is:
- at what point
- in pursuit of prohibiting 0.01% of uploads
- in defence of protecting the copyright of less than 2 million artists
- does pissing-off up to* 29 million people per annum
…become acceptable?
* because statistical repeat-victims
- at what point
- in pursuit of prohibiting 0.01% of uploads
- in defence of protecting the copyright of less than 2 million artists
- does pissing-off up to* 29 million people per annum
…become acceptable?
* because statistical repeat-victims
33/ ignoring the side effects of:
1. degraded / sucky user experience
2. chilling effects on small business
3. reinforcement of the monopolies of big business which can afford this (because 2.)
4. opening the door to government censorship
1. degraded / sucky user experience
2. chilling effects on small business
3. reinforcement of the monopolies of big business which can afford this (because 2.)
4. opening the door to government censorship
34/ Just in case someone else tries the "…but Google said it will lose huge amounts of traffic if it started filtering uploads for copyright infringement":
a) adverts are sold on views, not uploads, and…
b) beware false equivalence, as explained:
a) adverts are sold on views, not uploads, and…
b) beware false equivalence, as explained:

35/ Good Morning! Last night, musician, programmer and metal-head Ben Sizer wrote that my analysis is an "embarrassingly statistically inaccurate thread" …and you know what, he may be right; and if so I believe it leaves us, as consumers, no better off:
36/ What Ben is getting at is that the cited false-positive rate does not give us enough information to reconstruct the amount of badness which the filters are meant to block.
37/ For those following along at home, there's a really good page at dataschool.io/simple-guide-t… which helps with the tables and the terminology
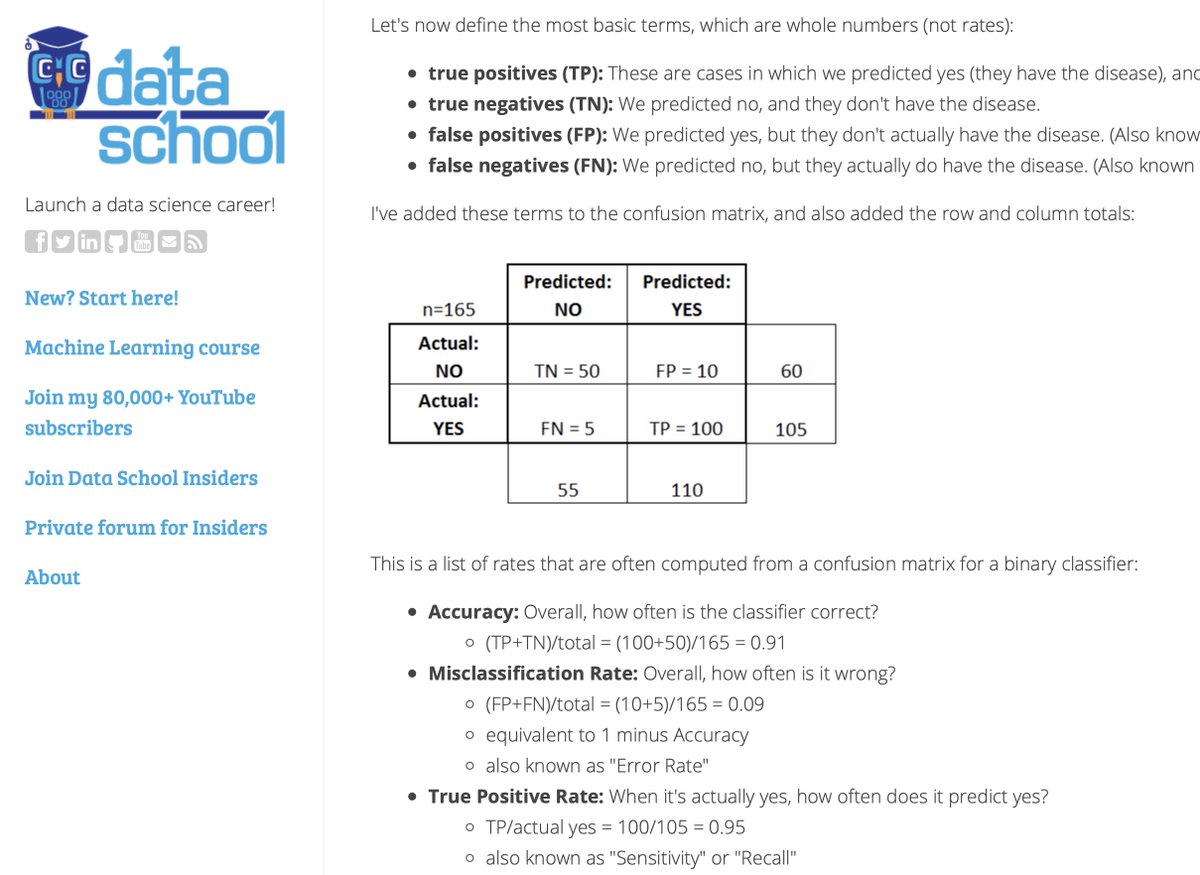
38/ The issue is: we cannot just say "out of a population of 1 million people, the judge 'only' threw 1 innocent person into jail" —and from that extrapolate the ratio of innocent to criminal people, even if we know how good the judge is at being certain that "someone's a bad'un"
39/ The software in question claims to exceed 99% accuracy - that presented with a definite criminal, the judge will be 99% certain to spot the person as criminal; and they also claim to falsely imprison 1 person in a million:
audiblemagic.com/why-audible-ma…
audiblemagic.com/why-audible-ma…

40/ So Ben's somewhat right — we're not terribly better-informed than we were on Friday re: how bad content filtering is going to be for our user experiences; but there is hope for better understanding. We can start by trying to fill-out one of these tables:

41/ …and then we can turn it into a spreadsheet; again if we pick a "prevalence" (badness rate, one-in-how-many posts infringe copyright) then, given the claims on the website, we can see how the rest of the table pans-out:

42/ If you want to make a copy of the spreadsheet and futz around with a copy of it, feel free - link attached; after a while what becomes apparent is that we'd be taking a lot of this on trust, from a "glossy sales brochure" website
docs.google.com/spreadsheets/d…
docs.google.com/spreadsheets/d…
43/ Anything in Yellow is an input box, anything in Red is computed somehow, and the citations for the equations are:
en.wikipedia.org/wiki/Precision…
and dataschool.io/simple-guide-t…
en.wikipedia.org/wiki/Precision…
and dataschool.io/simple-guide-t…
44/ If you find any typos in the equations, let me know; but also consider that "One false positive in a million" / "10e^-6" figure. A claimed 99.9999% "no-false-imprisonment" rate, it exceeds the vaunted "Six Sigma" rate of 99.9997%.
But is it plausible, realistic, good?
But is it plausible, realistic, good?
45/ Imagine for a moment that it is achievable; that means for our hypothetical 8 million uploads per day, still making digital roadkill out of 365 * 8 = 2920 uploads per year.
In the meantime, what's going on behind the scenes?
In the meantime, what's going on behind the scenes?
46/ With the recall ("when it sees badness, the judge accurately identifies it") anchored at 99% in the spreadsheet, and a prevalence of 1/10k, if we raise the false-positive rate to 10/1m, the "precision" (how often is it right when it convicts the accused) drops to 91%

47/ But you can achieve the same by leaving the false positive rate at 1-per-million, and instead reducing the prevalence to 1-in-100k. There are two variables, like a see-saw - push one down, the other goes up.
This is what stops us working it out backwards.
This is what stops us working it out backwards.

48/ So: any movement to go ahead with this is putting a lot of (excessive?) trust in a bunch of formulas where (eg:) shifting from 1-in-a-million false-positives, to 10-in-a-million, will reflect your precision dropping from 99% (1-in-100) to 90.8%(1-in-11ish)
49/ Last year I posited* a scenario a "prevalence" of 1-in-500 and an "accuracy" (see sheet) of 98.5%; how many False Positives per million can we have and satisfy that?
Answer: about 15,000 / million. Not 1; but "Precision" falls thru the floor:
*
Answer: about 15,000 / million. Not 1; but "Precision" falls thru the floor:
*

50/ So the challenge for you, dear reader, is to mess around with the spreadsheet and work out what you want to optimise for, what you want to trade-off — as you try to keep your business afloat keeping people connected.
51/ ps: Anyone who likes Sudoku, will love this shit.