
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
Rather than hardcoding forward prediction, we try to get agents to *learn* that they need to predict the future.
Check out our #NeurIPS2019 paper!
learningtopredict.github.io
arxiv.org/abs/1910.13038
Rather than hardcoding forward prediction, we try to get agents to *learn* that they need to predict the future.
Check out our #NeurIPS2019 paper!
learningtopredict.github.io
arxiv.org/abs/1910.13038
Work by @bucketofkets @Luke_Metz and myself.
Rather than assume forward models are needed, in this work, we investigate to what extent world models trained with policy gradients behave like forward predictive models, by restricting the agent’s ability to observe its environment.
Rather than assume forward models are needed, in this work, we investigate to what extent world models trained with policy gradients behave like forward predictive models, by restricting the agent’s ability to observe its environment.

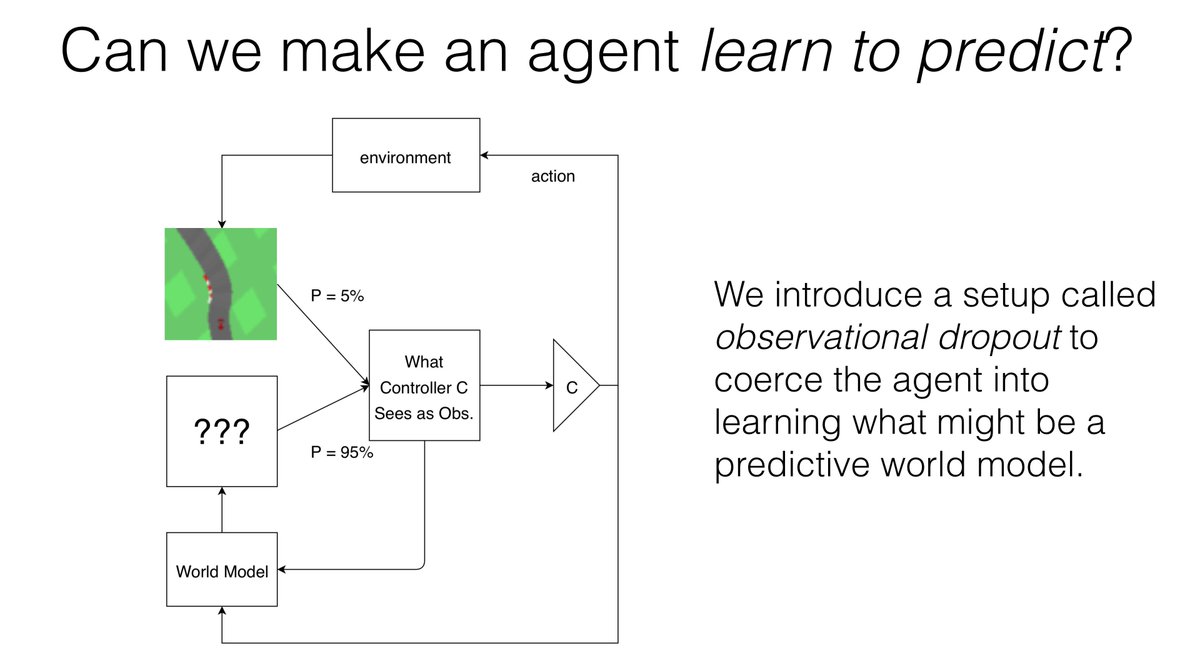
@bucketofkets @Luke_Metz @NeurIPSConf Core idea: By not letting an agent observe (most of the time), it can be coerced into learning a world model to help fill in the gaps between observations.
It's like training a blindfolded agent to drive. Its world model realigns with reality when we let it observe (red frames):
It's like training a blindfolded agent to drive. Its world model realigns with reality when we let it observe (red frames):
@bucketofkets @Luke_Metz @NeurIPSConf Our agent is only given infrequent observation of the real environment. As a side effect for optimizing performance in this setting a “world model” emerges.
The true dynamics in color, full saturation denoting frames it can see. The outline shows the state of the emergent model.
The true dynamics in color, full saturation denoting frames it can see. The outline shows the state of the emergent model.
@bucketofkets @Luke_Metz @NeurIPSConf At each timestep, the policy either sees the real observation (5%) or one generated by the world model (95%) but it cannot tell which one is real, and outputs an action.
Meanwhile, the model outputs a “predicted” observation based on the policy's previous observation and action.
Meanwhile, the model outputs a “predicted” observation based on the policy's previous observation and action.
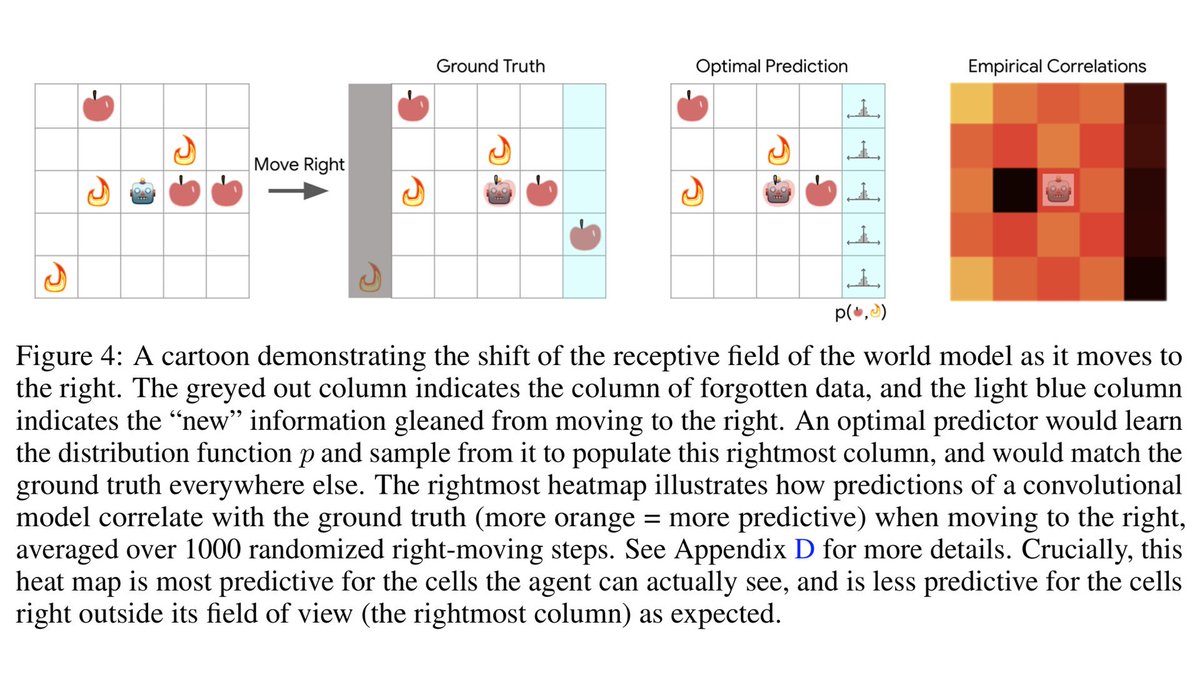
@bucketofkets @Luke_Metz @NeurIPSConf These world model exhibits similar, but not identical dynamics to forward predictive models. It only models “important” aspects of the environment.
The “physics” the model learns is also imperfect. We can see this by training from scratch a policy on this model's “hallucination”
The “physics” the model learns is also imperfect. We can see this by training from scratch a policy on this model's “hallucination”
@bucketofkets @Luke_Metz @NeurIPSConf Surprisingly, the policy learned from training inside of the “dream world” still transfers to the actual environment to some extent. This policy is still able to swing up the cart-pole in the actual environment, although it remains balanced only for some time before falling down.
@bucketofkets @Luke_Metz @NeurIPSConf We examine the role of inductive biases in the world model, and show that the architecture of the model plays a role in not only in performance, but also interpretability.
Our paper will be presented at #NeurIPS2019:
article learningtopredict.github.io
arxiv arxiv.org/abs/1910.13038
Our paper will be presented at #NeurIPS2019:
article learningtopredict.github.io
arxiv arxiv.org/abs/1910.13038
@bucketofkets @Luke_Metz @NeurIPSConf We have released code to reproduce experiments in our paper “Learning to Predict Without Looking Ahead: World Models Without Forward Prediction” #NeurIPS2019
github.com/google/brain-t…
github.com/google/brain-t…


































