🗣Some recommendations for budding machine learning engineers:
(1) Make sure your sample dataset is representative of your entire population - and remember that more data is usually - but not necessarily! - better.
Also consider using image preprocessing tools, like Augmentor.
(1) Make sure your sample dataset is representative of your entire population - and remember that more data is usually - but not necessarily! - better.
Also consider using image preprocessing tools, like Augmentor.

(2) Use small, random batches to train rather than the entire dataset.
⏳Reducing your batch size increases training time; but it also decreases the likelihood that your optimizer will settle into a local minimum instead of finding the global minimum (or something closer to it).
⏳Reducing your batch size increases training time; but it also decreases the likelihood that your optimizer will settle into a local minimum instead of finding the global minimum (or something closer to it).
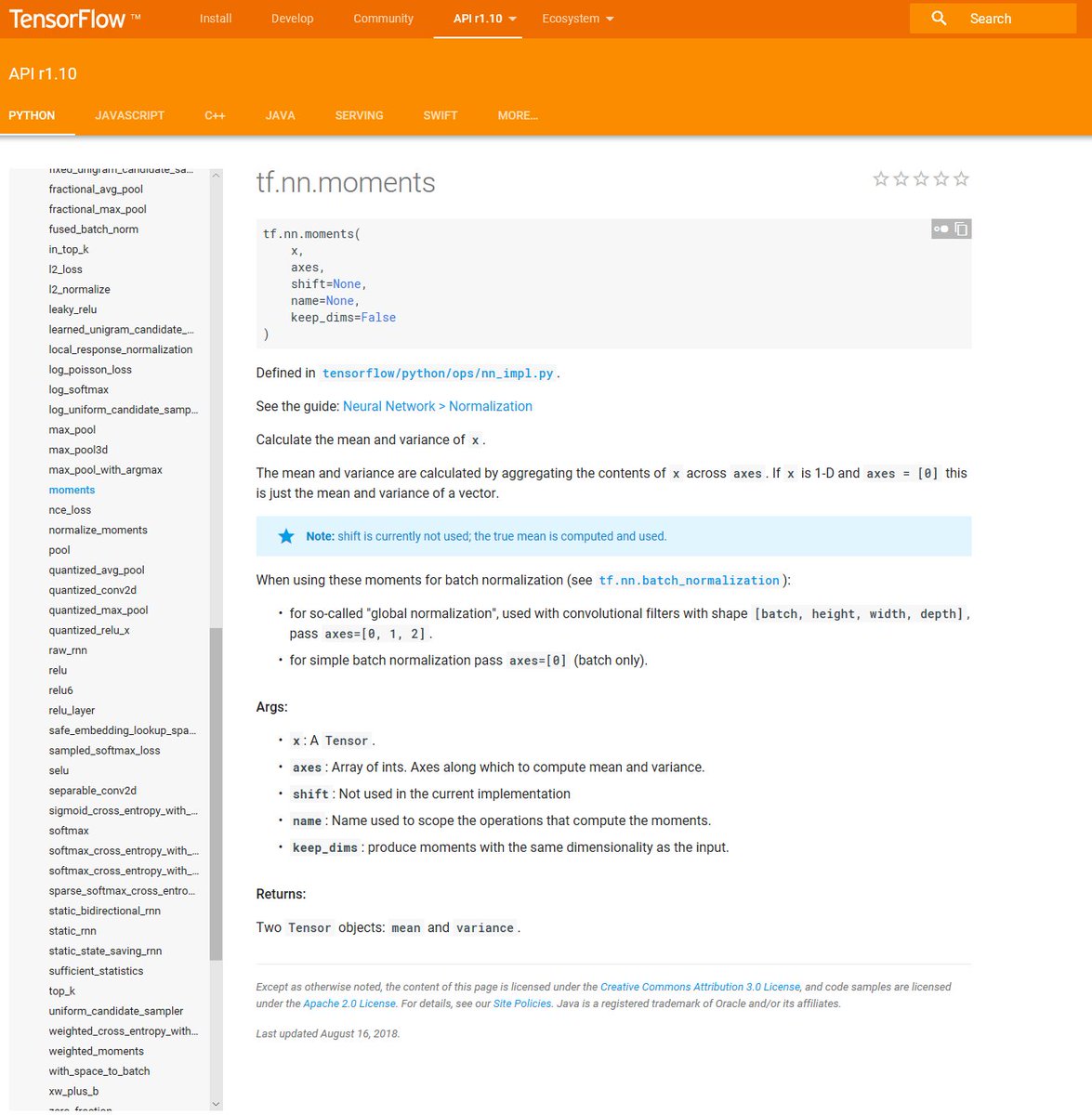
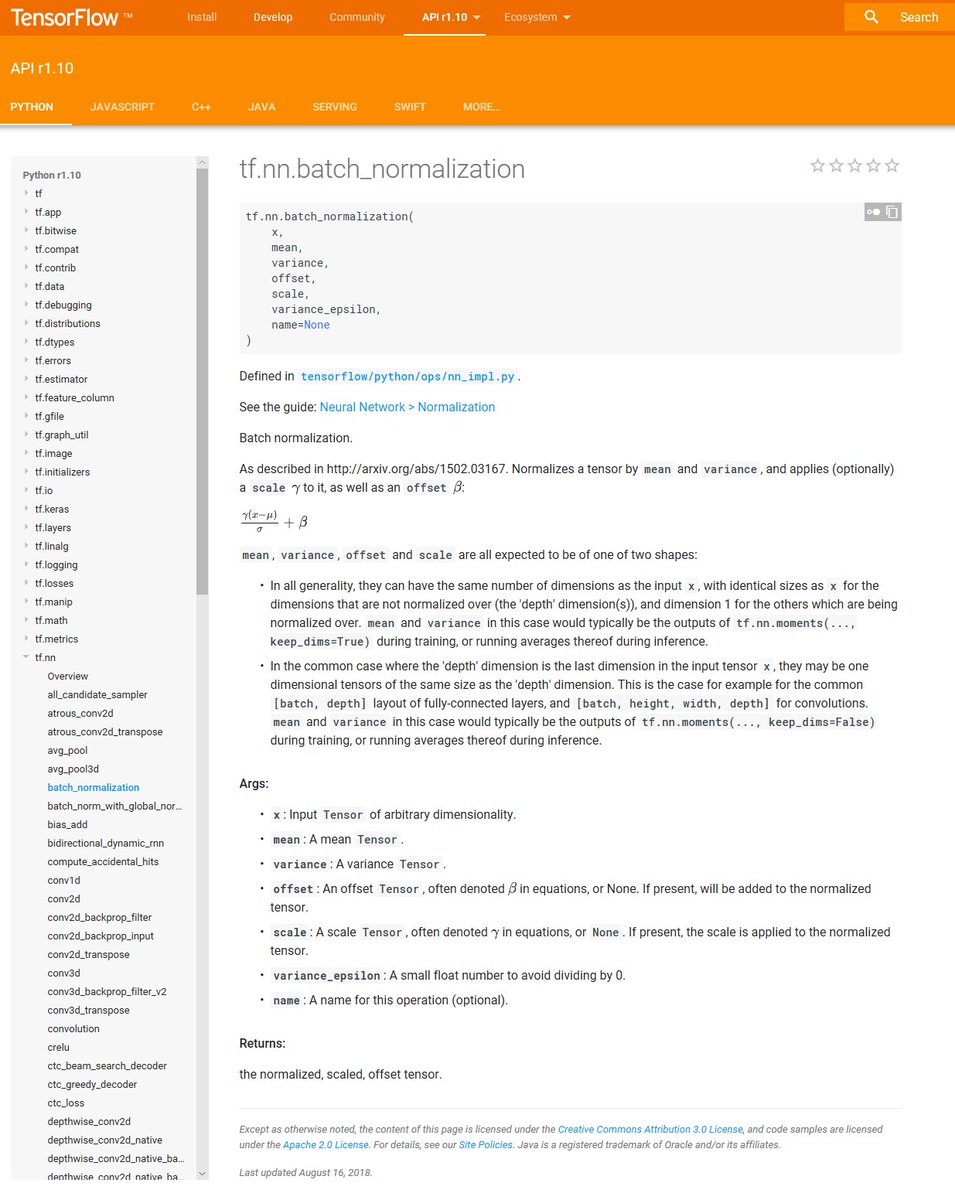
(3) Make sure the data that you're using is standardized (mean and standard deviation for the training data should match that of the test data). 📊
If you're using @TensorFlow, standardization can be accomplished with something like tf.nn.moments and tf.nn.batch_normalization.
If you're using @TensorFlow, standardization can be accomplished with something like tf.nn.moments and tf.nn.batch_normalization.
(4) More layers isn't always better! And adding too many of 'em at the beginning often leads to overfitting. 🙅♀️
Start with a few layers; if you aren't happy with accuracy, you can always add more. Another perk? The fewer layers you start out with, the faster the execution.
Start with a few layers; if you aren't happy with accuracy, you can always add more. Another perk? The fewer layers you start out with, the faster the execution.
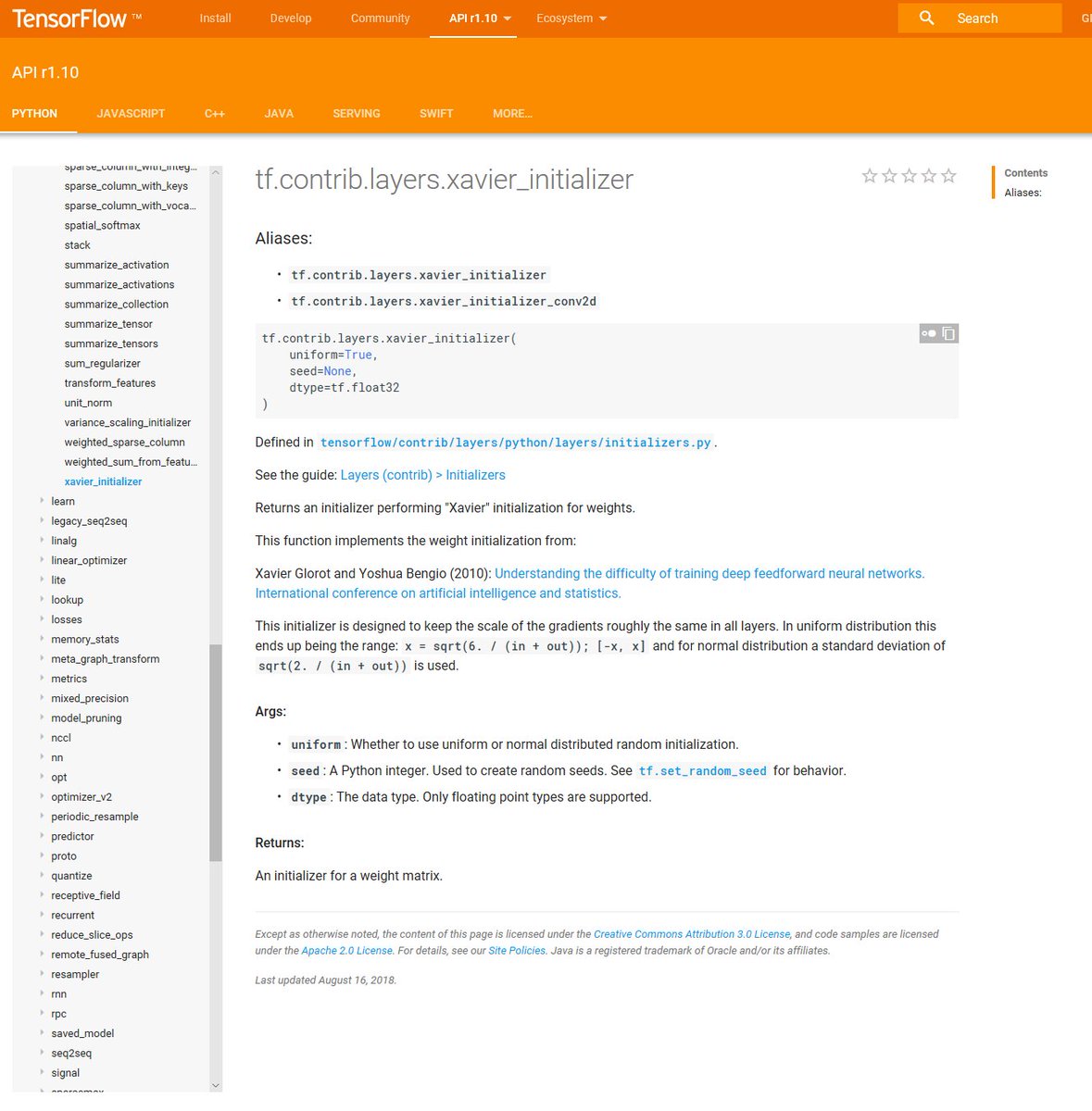
(5) ☠ WEIGHT INITIALIZATION ☠
Your weight initialization randomization function needs to be carefully chosen and specified; otherwise, there is a high risk that your training progress will be slow to the point of impractical.
An option, in @TensorFlow: tensorflow.org/api_docs/pytho…
Your weight initialization randomization function needs to be carefully chosen and specified; otherwise, there is a high risk that your training progress will be slow to the point of impractical.
An option, in @TensorFlow: tensorflow.org/api_docs/pytho…
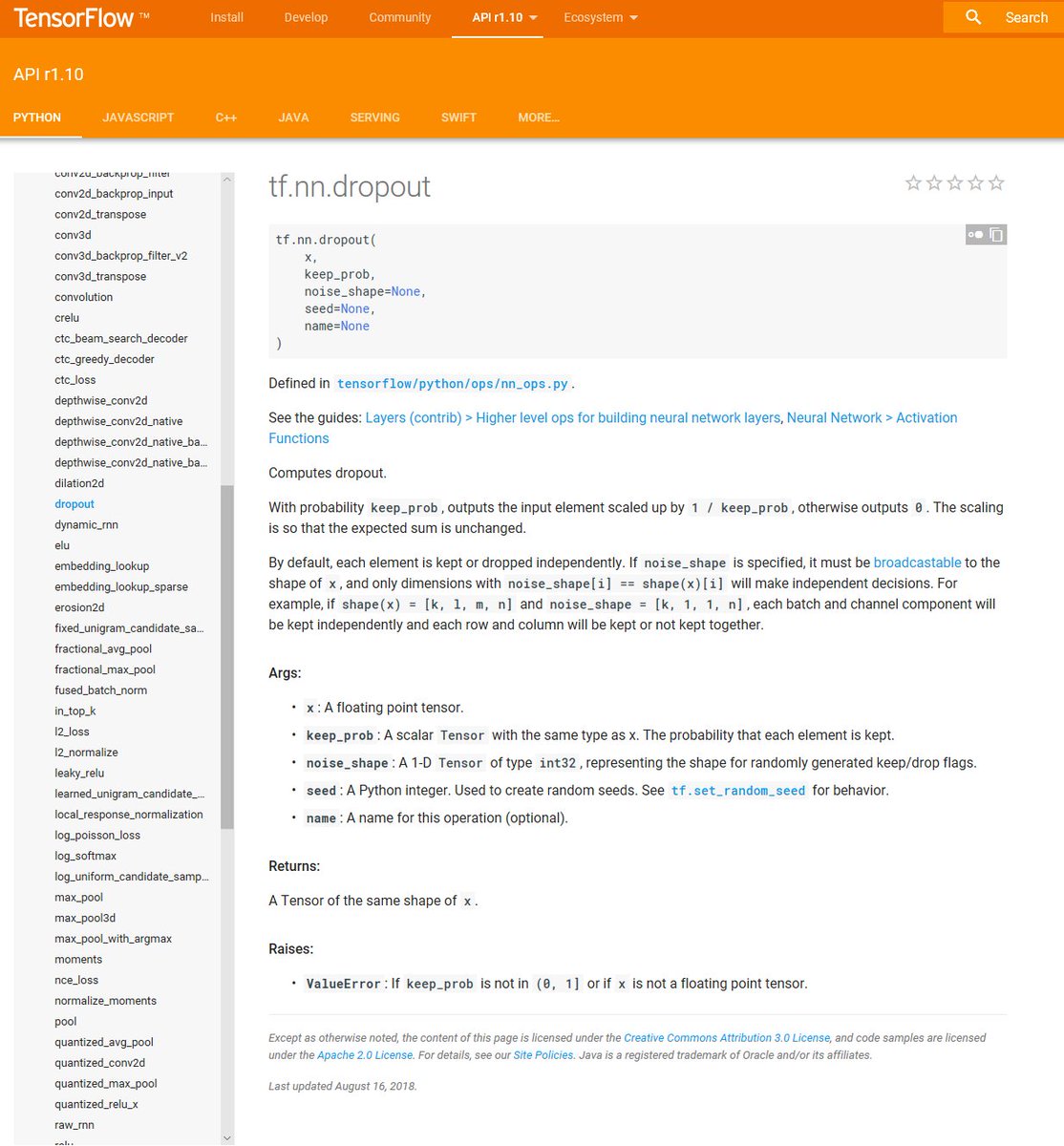
(6) Another attempt to combat overfitting: make sure to add dropout layers. ⚖
Dropout layers set a certain percentage of inputs to zero before passing the signals as output, which reduces codependency of the inputs.
In @TensorFlow, you can use something like tf.nn.dropout.
Dropout layers set a certain percentage of inputs to zero before passing the signals as output, which reduces codependency of the inputs.
In @TensorFlow, you can use something like tf.nn.dropout.
(7) Monitor your gradients and your weights. Check them often.
NNs frequently fail because weights get very, very big (exploding gradients) or very, very small / nonexistent (vanishing gradients). To resolve, adjust the number of layers in your model + activation functions.
NNs frequently fail because weights get very, very big (exploding gradients) or very, very small / nonexistent (vanishing gradients). To resolve, adjust the number of layers in your model + activation functions.

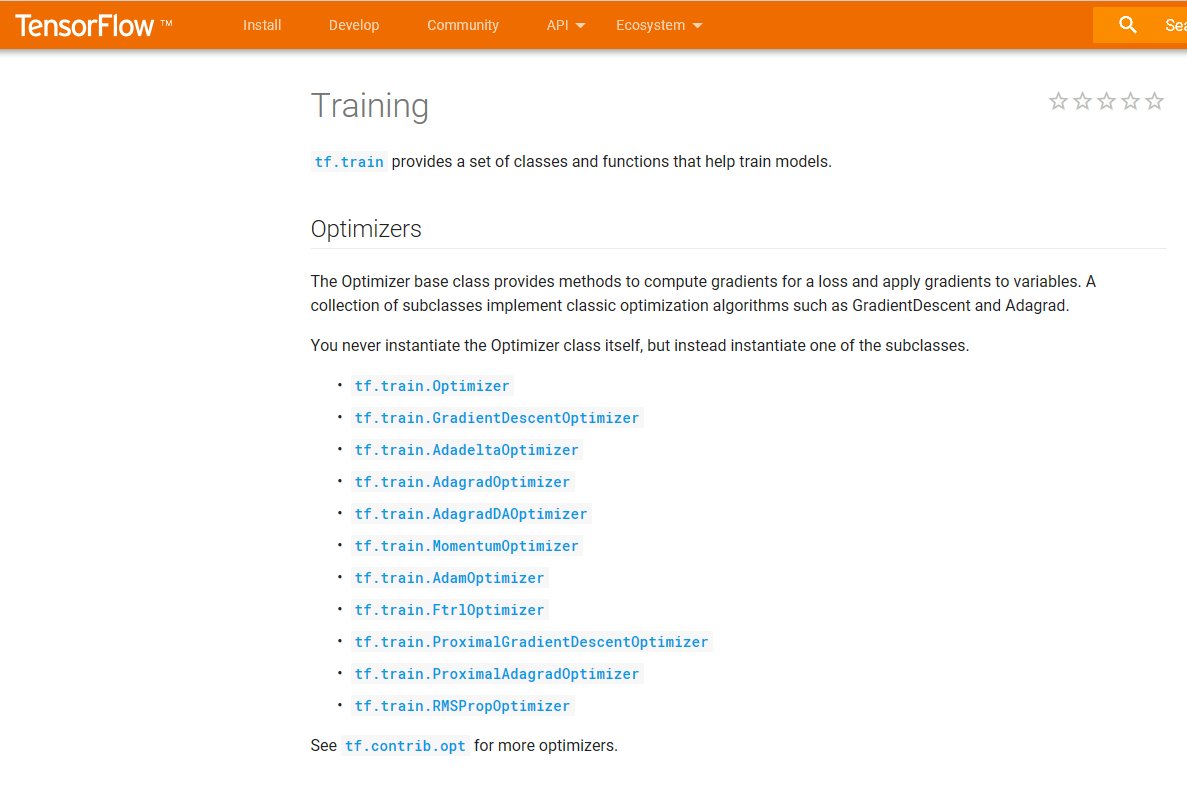
(8) Experiment with optimization algorithms!
The most common aren't necessarily the best for your particular task; and researchers haven't reached consensus, either.
👍A few of the most common: GradientDescentOptimizer, AdamOptimizer, AdagradOptimizer. tensorflow.org/api_guides/pyt…
The most common aren't necessarily the best for your particular task; and researchers haven't reached consensus, either.
👍A few of the most common: GradientDescentOptimizer, AdamOptimizer, AdagradOptimizer. tensorflow.org/api_guides/pyt…
(9) In addition to experimenting with optimizers, experiment with their learning rates (how the optimizer updates weights with each training step).
Most of the time, learning rates vary from 0.0001 to 0.5 - and most examples you see in tutorials start at the higher end. 📈
Most of the time, learning rates vary from 0.0001 to 0.5 - and most examples you see in tutorials start at the higher end. 📈
(10) Follow people who know what they're doing (@jeffdean @fchollet @goodfellow_ian @drfeifei @karpathy etc); read books, blogposts, papers; attempt to reimplement what you see in literature; ask lots of questions.
This stuff changes, every day. It's okay to feel overwhelmed. 💕
This stuff changes, every day. It's okay to feel overwhelmed. 💕


...actually, I'm gonna say that last bit again, so we're all on the same page:
Deep learning is progressing rapidly, and new research is being published *every day*. It's 100% okay to feel overwhelmed. ❤️
(My goal is just to have you feel energized and excited about it, too.)
Deep learning is progressing rapidly, and new research is being published *every day*. It's 100% okay to feel overwhelmed. ❤️
(My goal is just to have you feel energized and excited about it, too.)