
A natural history of dopamine; a thread on @fluketc paper goo.gl/yLnoJr : Dopamine is critical for novel learning. Pioneering work developed methods to record from dopamine neurons. However, recordings come from animals re-learning, rather than learning anew. Why? 
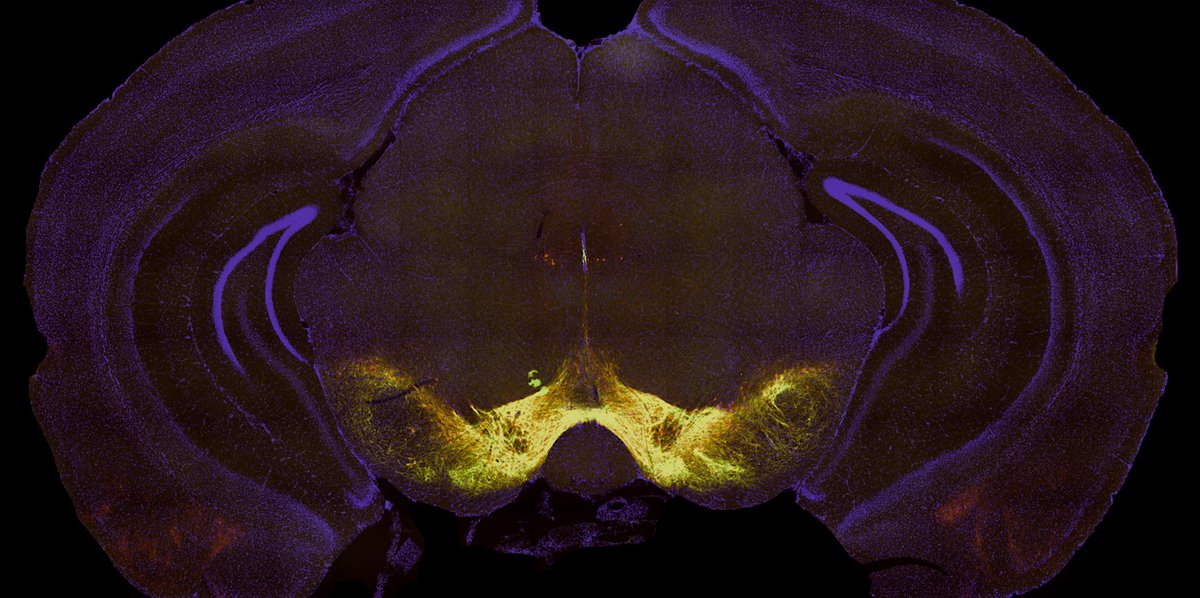
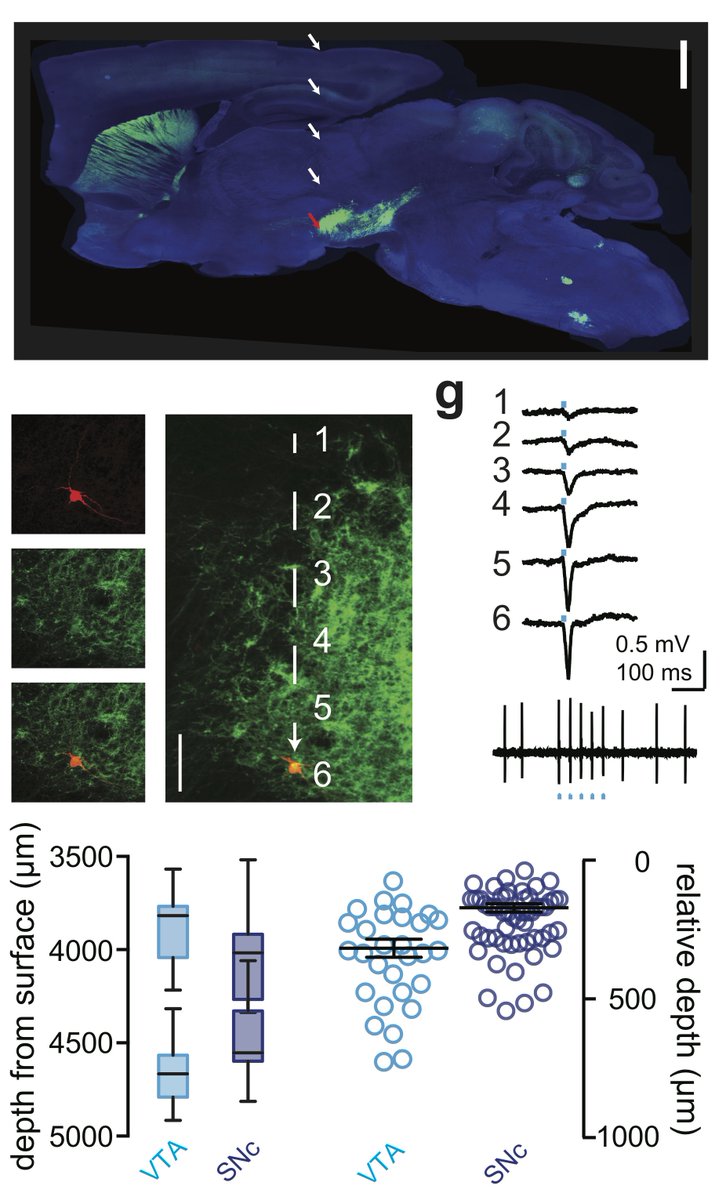
Well, these recordings are very hard, but easier in trained animals. @fluketc came up with an elegant alternative approach to capture activity of dopamine neurons during novel learning. What we saw is the story of his recent paper in @NatureNeuro out now rdcu.be/9i8Q
We learn from past experience to anticipate future events. How can you tell one anticipates an event? Often we act in anticipation. Think of a child reaching out a hand in hopes of receiving a piece of candy or an animal licking at a tube that delivers sweetened water rewards.
Mice anticipate sweetened water rewards and they both lick in anticipation and it turns out that if you measure it, you can see they also try to lean in towards the reward. You might think of yourself leaning towards the tv while anticipating a big play in a football game

The default response of a DA neuron to such movements is a net inhibition of its activity - a result seen in naive animals in our experiments as well as very nice recent work from @dodson pnas.org/content/113/15…
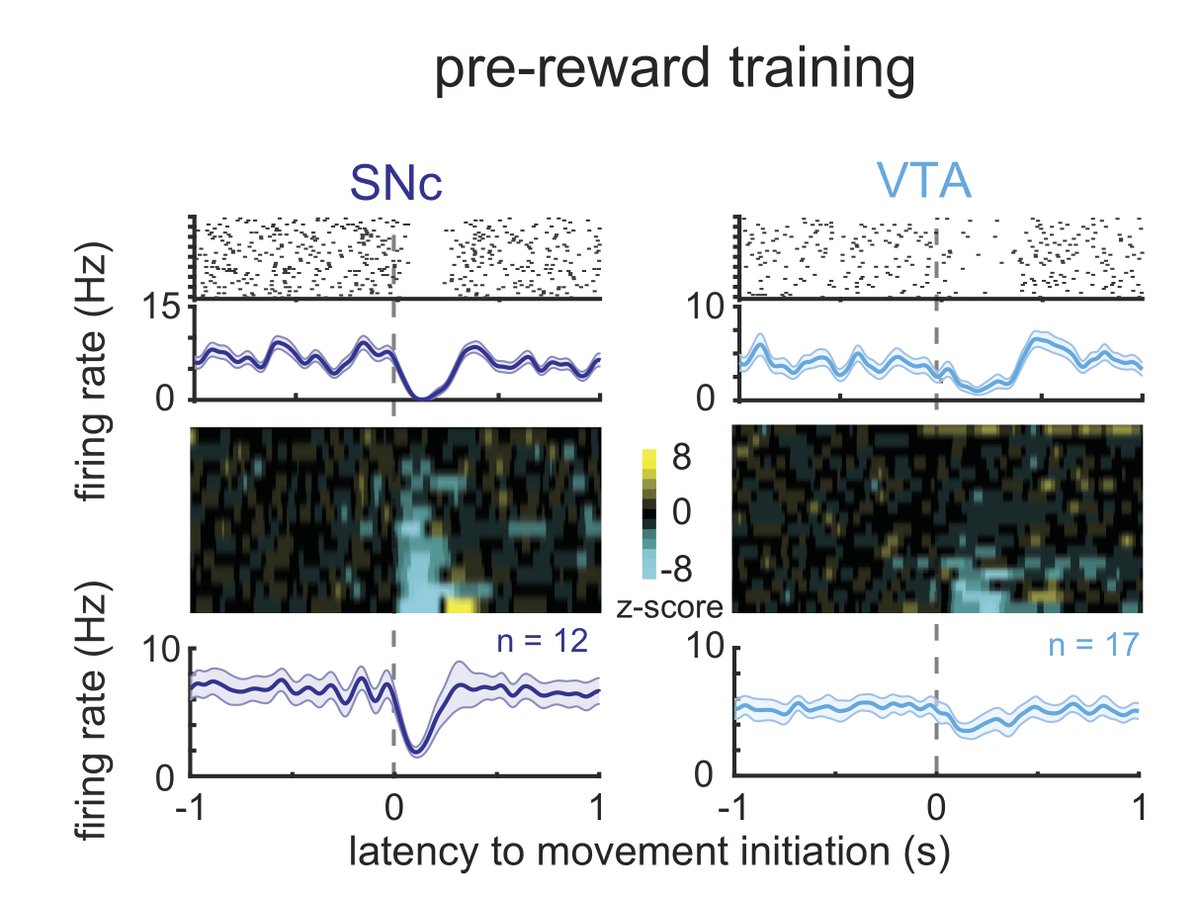
However, once some rewards are possible, a little burst of activity occurs at movement initiation. We propose this reflects an action taken with in anticipation of reward. But… you may well have thought that DA neurons are the signal in the brain that a reward was received.

But DA neurons do not, even for the very first few rewards, reflect receipt of reward. They fire before receipt and in anticipation of collecting a reward. We could see this clearly in raw data because we observed the very first few experiences a mouse had with a water reward.

DA neurons are active right before movement - this has tempted many to conclude it’s obligate to move. We know that this isn’t strictly true (movements are present in naive mice even though DA neurons were inhibited), but maybe DA activity was necessary once rewards were around..
We tested this directly w/ an approach we think is important - calibrated stimulation. In the same cells we measured normal responses to rewards and movements and then played back the same pattern of activity (and a number of supraphysiological patterns) to see what happened…

What happened? zilch. When we played back calibrated stimulation no movement - we needed ~5x activity to get a little movement. From this we conclude that DA activity can reflect anticipation associated with movement without being obligate for or sufficient for movement itself.
In naive mice DA is inhibited by movement then once rewards are available DA is excited by the ~same movement. This is clearly an aspect of learning, but only an aspect. What about learning to use information from the environment to anticipate when rewards are available?
Mice can also smell the presence of a sweetened water reward sitting in front of their nose and we also can give them a cue about when reward would be available. We played a brief tone (half a second) to let them know that a reward would appear 1 second later.
The mice learned to use these sensory cues to anticipate reward and guide when to act. After a few hundred such experiences, mice would start licking and moving after the cue - they knew something good was coming.

DA activity also started to reflect anticipation triggered by sensory cues. This is well known, but still remarkable. A sensory stim provokes no response. After learning that same stim elicits a robust response in DA neurons - and when played back _is_ sufficient for learning.

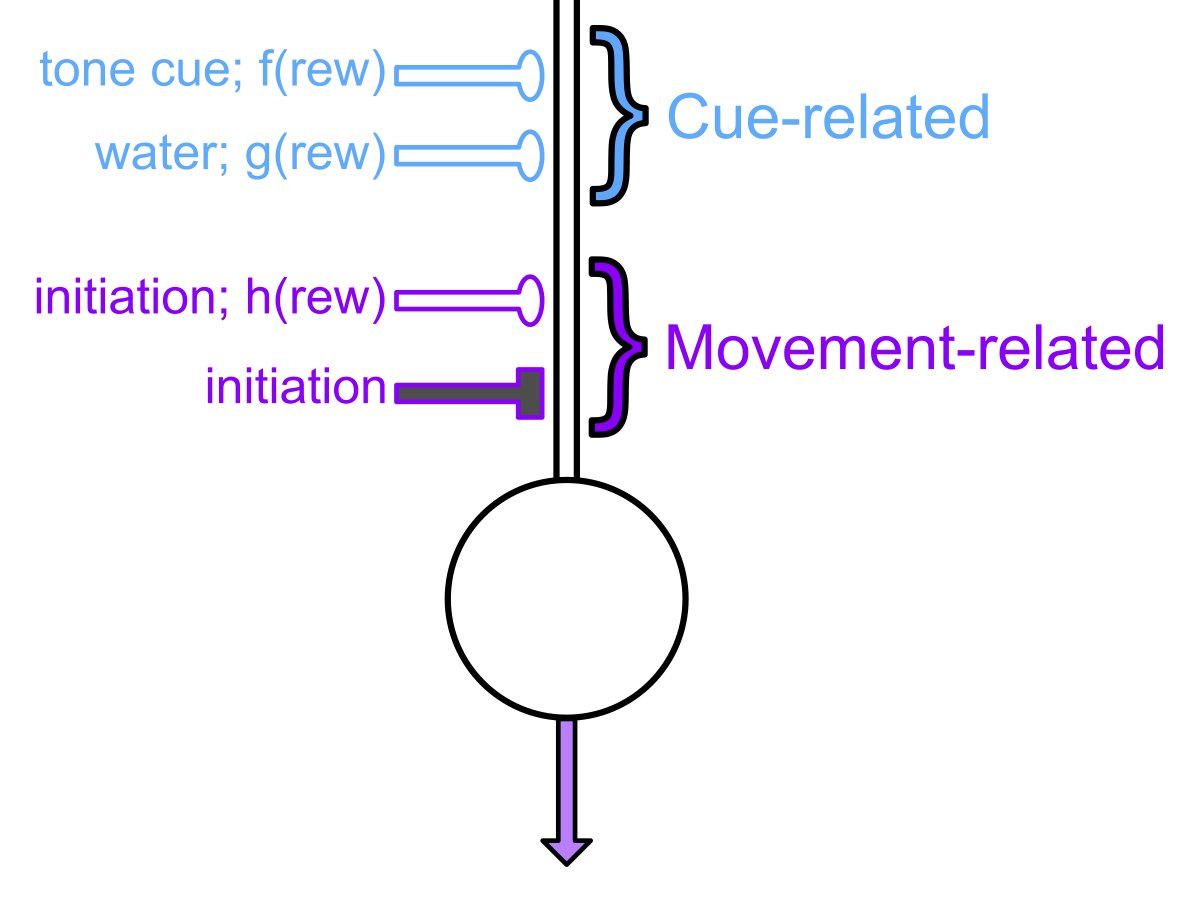
It has been proposed for 20 yrs that DA activity reflects a scalar variable- reward expectation in simple learning (using a cue to anticipate reward). Here, with our novel dataset we saw 2 distinct components - one associated with movements and one associated with sensory cues
A very surprising, albeit subtle, point and one we had never questioned previously, was that the DA response to a sensory cue and reward delivery were both a function of training extent, but changed independently. This directly contradicts a core premise of influential models.

Moreover, the sensory cue and movement related components have distinct time courses (mvmt-associated appears in first ~10 trials, sensory cue-associated over hundreds of trials) and also sum - a classic demonstration of independent inputs to a neuron.

Finally, once behavior has fully adapted to the task and will not change further (overtrained) - only then do we observe the canonical neural correlate of reward prediction error (RPE). In other words, after learning is complete and as a consequence of learning.
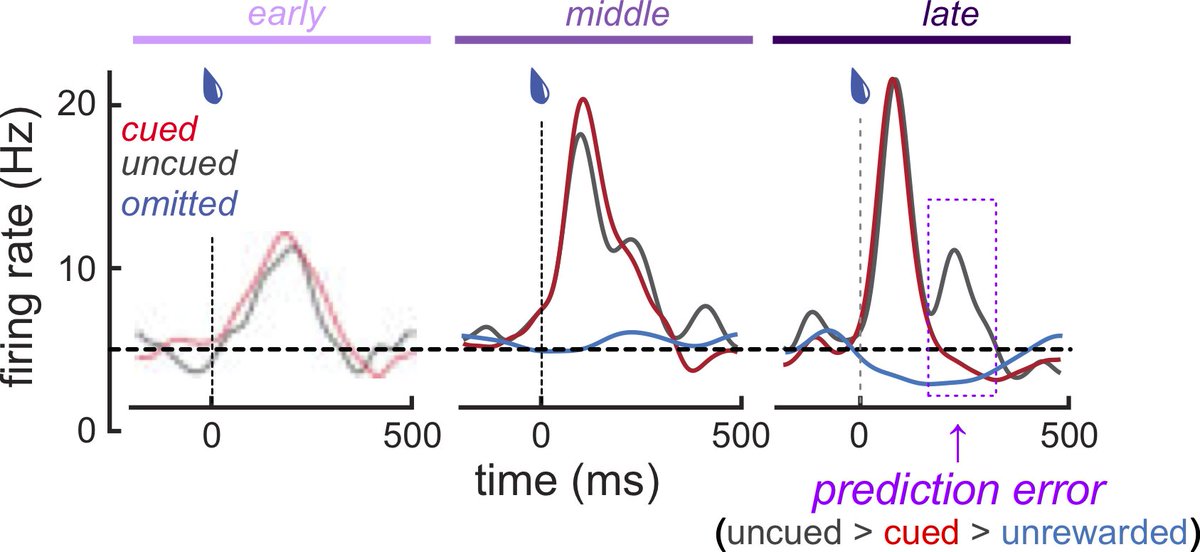
That RPE correlates are a consequence of learning is quite surprising. It has been argued that RPE signals in DA neurons are a cause of learning. A key point: we replicate observed RPE correlates _after_ learning and we replicate that DA stim is sufficient for reinforcement.
Our dataset rules out the now canonical interpretation of how a temporal difference like computations could be implemented to give rise to DA RPE correlates (e.g. Suri & Schultz 1999) providing strong evidence that RPE correlates do not arise from an error computation. But…
An implementation consistent with temporal integration of sensory cue-associated and action initiation-associated inputs + Hebbian plasticity can explain DA correlates both on the timescale of learning (hours/days) and of synaptic integration (millisec) dudmanlab.org/html/learnda.h…
Thus, we conclude that the timing of action is a critical determinant of reward prediction correlates in the activity of DA neurons during novel associative learning. This has important implications for the learning rules that underly DA-dependent learning.
In particular, it suggests that correlation-like signals in the activity of mDA neurons may allow a novice animal to rapidly learn from its successes - namely, when an appetitive action is initiated in response to a predictive cue - akin to Hebbian conceptualizations of learning.
The independence of cue-related and reward-delivery responses + the fact that DA responses lag after learning provides support for the notion that changes in DA activity are a consequence of learning in other brain circuits. Eg, amygdala goo.gl/KKxT3S
Onward... how is learning in distributed brain circuits coordinated to control behavior. Two things we propose from this study: Novel learning (ie before overtraining coordinates multiple circuits) and a detailed examination of behavior are key to focus on in future work. Fin.









