@adrianco kicking off with Breaking Containers. We'll be discussing history and what it looks like. @Ana_M_Medina will be doing some live demos later on
How frequently do you failover a whole datacenter? ... not that frequently according to @adrianco. We do it to appease auditors but this turns into "Availabilty Theater"
Some examples of bad situations:
- Forgot to renew a domain name
- Didn't update security certificate and it expired...
- Physical hardware issues "surprisingly computers don't function well underwater" during Hurricane Sandy
- Forgot to renew a domain name
- Didn't update security certificate and it expired...
- Physical hardware issues "surprisingly computers don't function well underwater" during Hurricane Sandy
"You can't legislate against failure, focus on fast detection and response." - Chris Pinkham. Couldn't agree more. There are millions of failure modes to attempt to 'prevent' you can't catch them all.
Some good books following...
Drift Into Failure by Sydney Dekker: Everyone can do everything right at every step you may still get a catastrophic failure as a result. Protip: don't read this on a plane or with a loved one nearby!
Drift Into Failure by Sydney Dekker: Everyone can do everything right at every step you may still get a catastrophic failure as a result. Protip: don't read this on a plane or with a loved one nearby!
Release It! Second Edition by Michael Nygard. Great book on Bulkheads and Circuit Breakers.
@adrianco : Chaos Engineering practice is "to experiment to ensure that the impact of failure is mitigated". Slightly modified less verbose version of what's available on #principlesofchaos It's a great synopsis. #reInvent
Categorizing failures can certainly help to manage your chaos testing portfolio. Core failure mode categories include:
- Operations
- Application
- Software stack
- Infrastructure
#reInvent
- Operations
- Application
- Software stack
- Infrastructure
#reInvent
Replication is core to chaos testing and resiliency:
- Application level replication
- Structured database replication
- Storage block level replication
- Application level replication
- Structured database replication
- Storage block level replication
Three bullet history of IT resiliency:
- Past: disaster recovery
- Now: Chaos engineering
- Future: Resilient critical systems
Will be interesting to hear the difference between Now and Future.
- Past: disaster recovery
- Now: Chaos engineering
- Future: Resilient critical systems
Will be interesting to hear the difference between Now and Future.
Diving into more of the history behind Disaster Recovery:
- Started with Sungard & Mainframe Batch, core focus on Recovery Point Objectives (time interval between snapshots)and Recovery Time Objectives (time taken to recover from after a failure)
- Started with Sungard & Mainframe Batch, core focus on Recovery Point Objectives (time interval between snapshots)and Recovery Time Objectives (time taken to recover from after a failure)
@adrianco - "When adopting Chaos Engineering don't try to reinvent the wheel! Disaster recovery and resiliency are not new topics, don't try to redefine these. Chaos Engineering is focused on the technology used, not the terminology and concepts - do research and read standards"
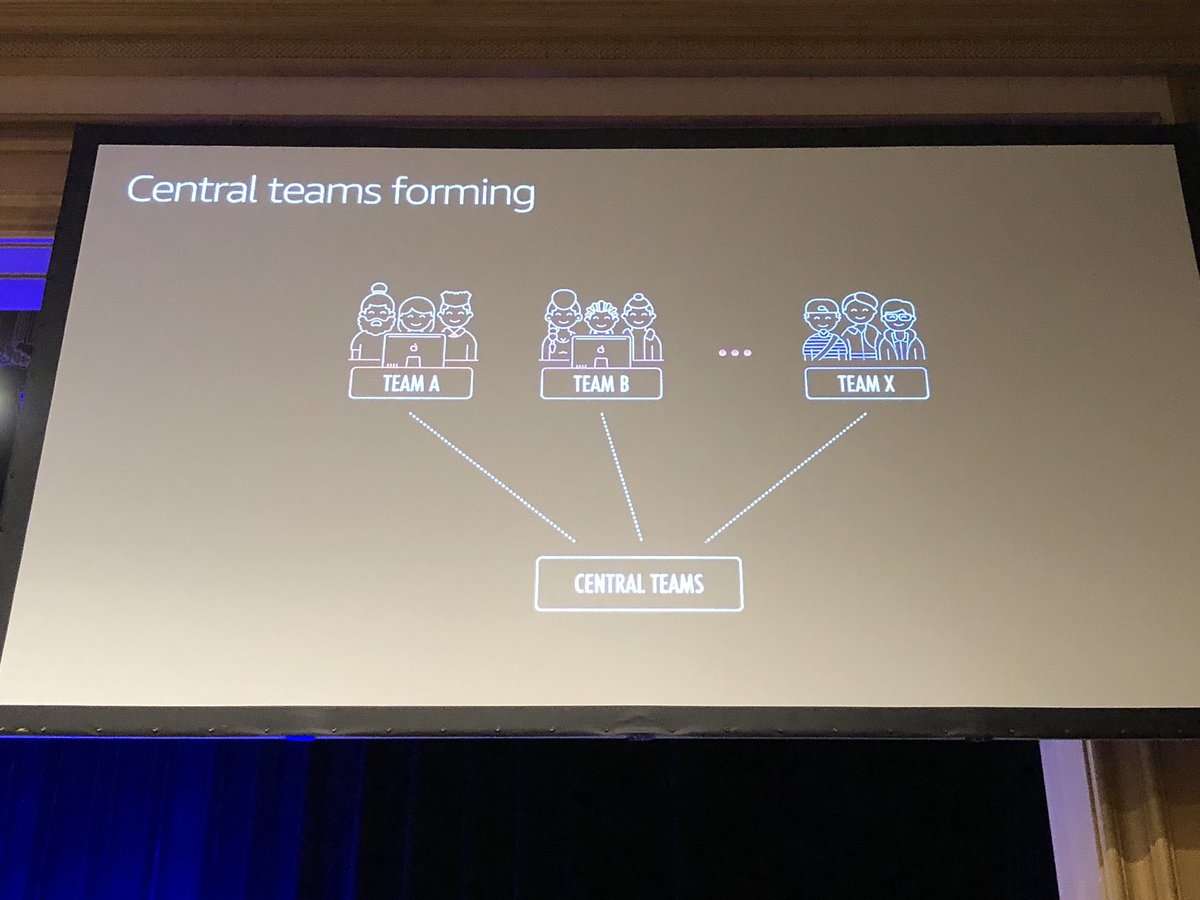
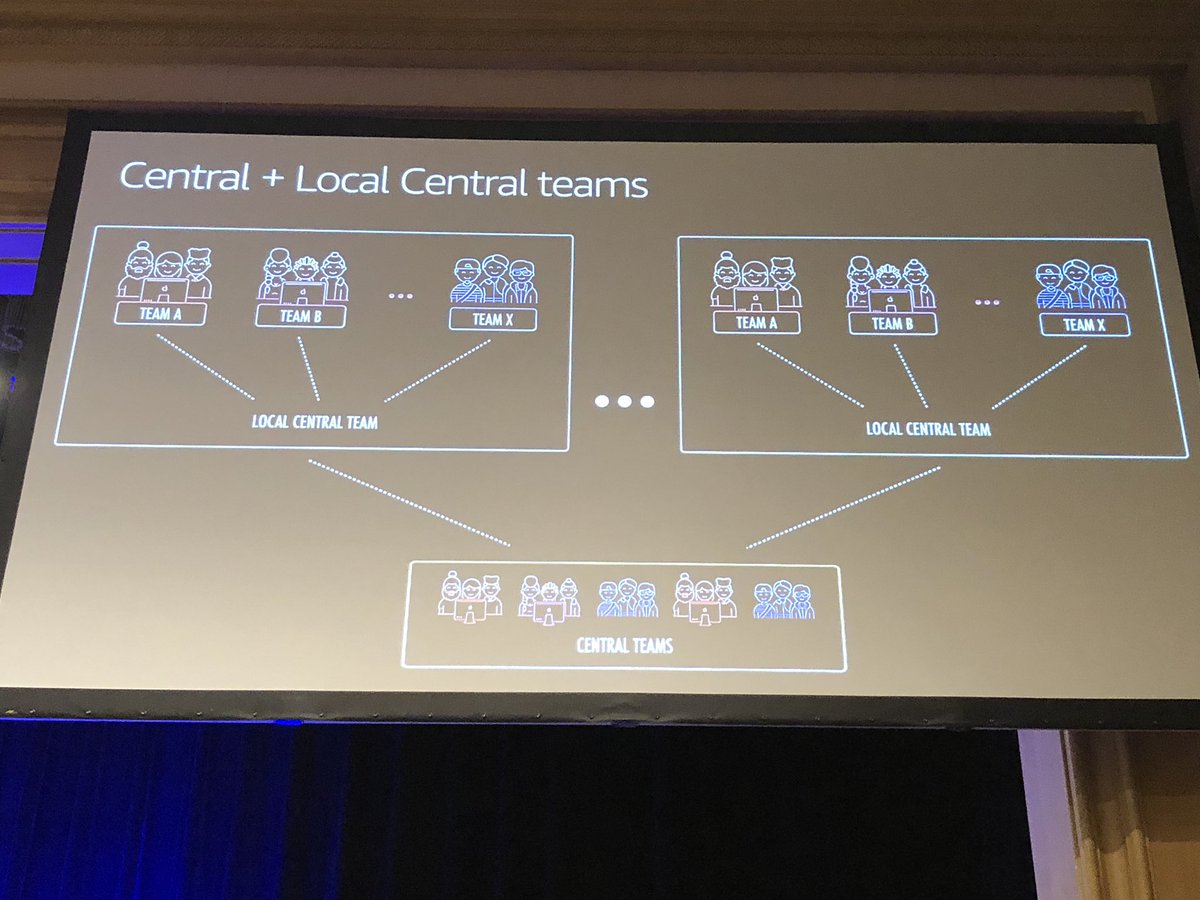
Responsibilities of a Chaos Engineering team: People response processes (supported by Game Days), Application failures, switching between systems, and infrastructure failures. Would be interesting to hear how orgs are adopting along with SRE concepts/teams.
@adrianco : "Any switching systems utilized to transition compute or functionality from one location or system to another must be orders of magnitude more resilient than any of your applications" - this is a super critical concept that many might not catch.
Brief tangent into root-cause analysis. Would love to get away from RCA terminology - not a great syntax to use in blameless cultures.
Models in AWS that enable Chaos testing:
- AWS Isolation Model: No global network or service dependencies; AZ geographical separation with synchronous replication
AWS Mechanisms: fault injection queries, simulating region failure via IAM region restriction
- AWS Isolation Model: No global network or service dependencies; AZ geographical separation with synchronous replication
AWS Mechanisms: fault injection queries, simulating region failure via IAM region restriction
Chaos for k8s! 
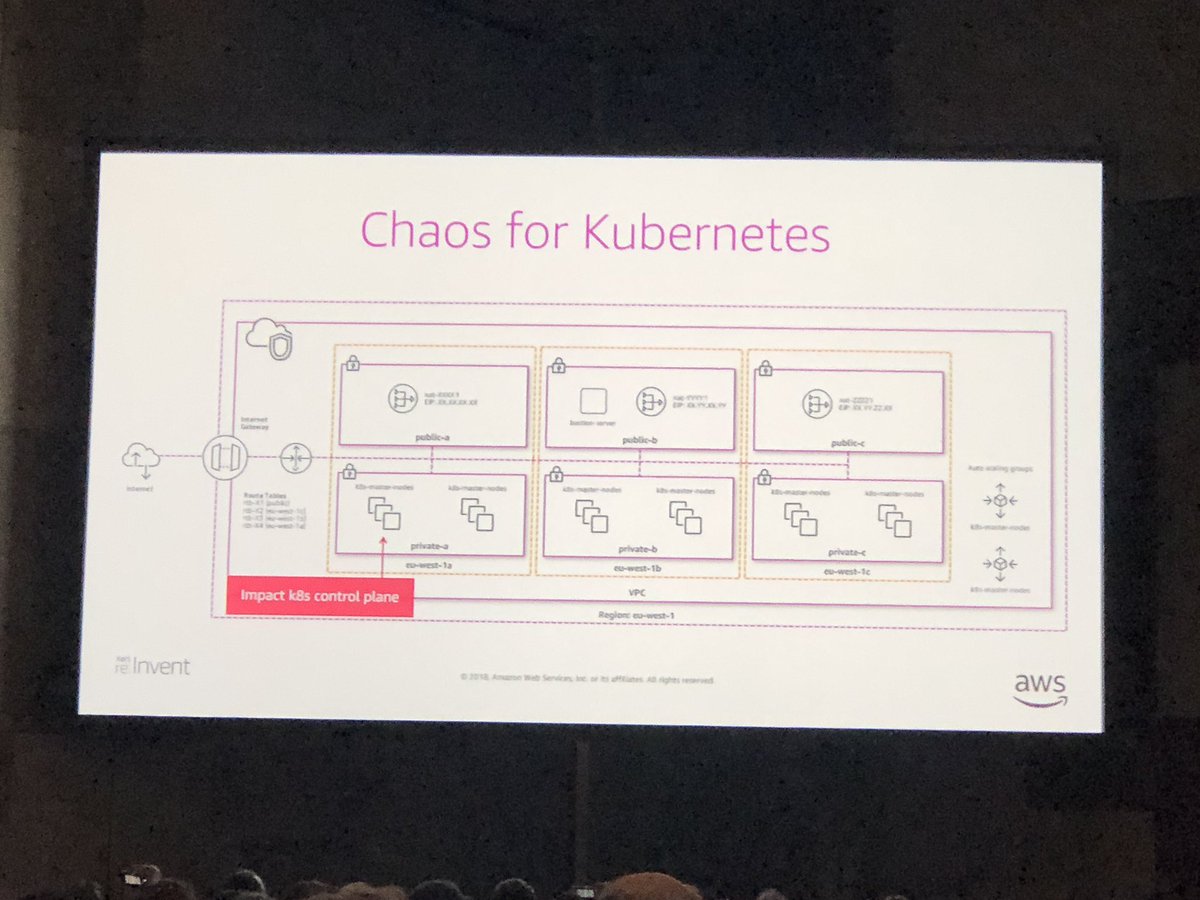

@Ana_M_Medina ‘s pro tip for chaos: start small! Initial test should have a very small blast radius, increase the size over time as you’re increasing confidence. This goes for nonprod testing as well!

@Ana_M_Medina - a great practice is to tie Monitoring and observability platforms to your chaos tests. Have the monitoring determine if things get “too bad” and shut off the test
The demo-gods are working in @Ana_M_Medina ‘s favor. We are following the “start small” mantra and expanding blast radius. Guestbook app has longer and longer response times.
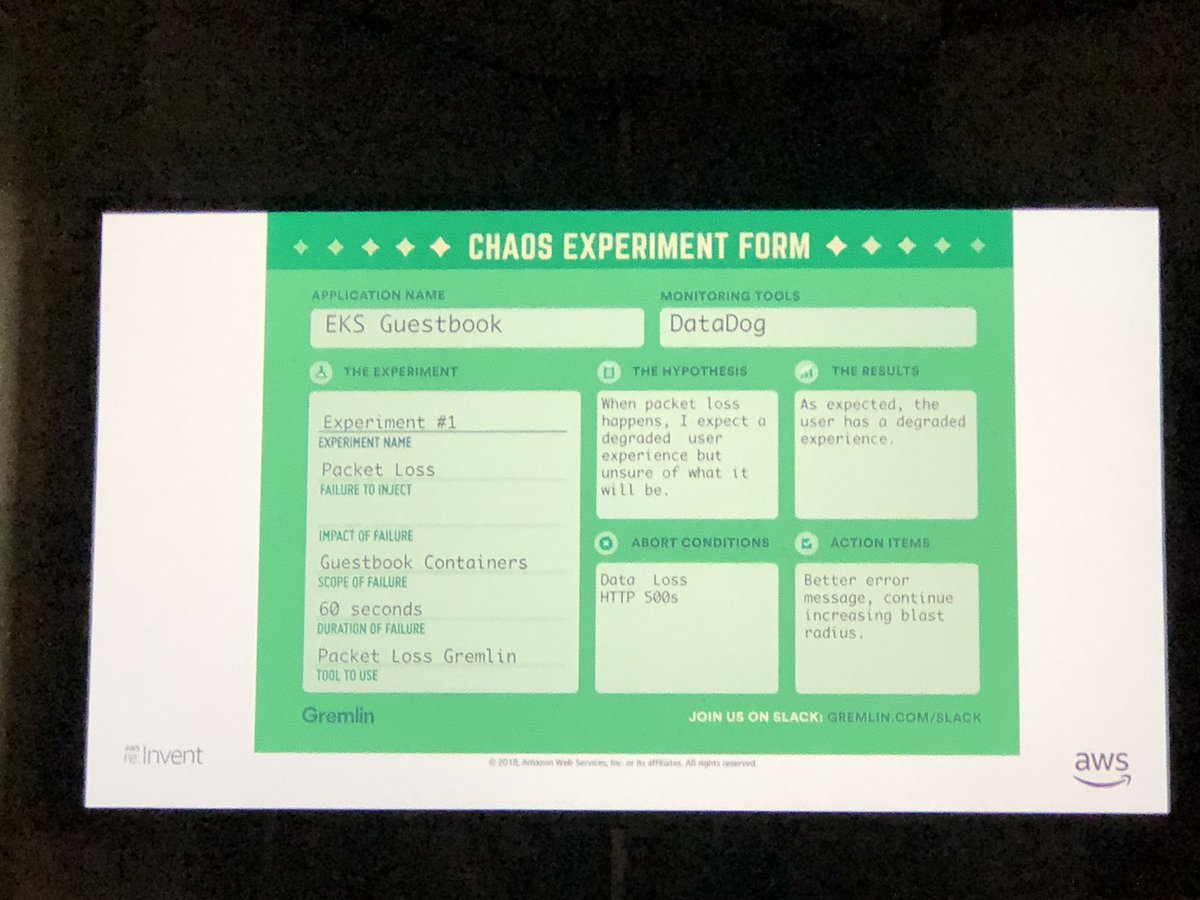
Template for Chaos Engineering experiments. Covers all the core concepts teams should think about before and after a chaos test. I’ve seen a few variations of these out there. This is the first including an abort condition that I’ve seen. #reInvent
Opinion: for standardized and “known” chaos attacks such as CPU/latency attack it would be awesome if dev teams included them as nonfunctional requirements in the build of the app!
Additional opinion: include them as repeatable tests that get run through a CI/CD pipe for bonus points.
Great suggestion from @Ana_M_Medina - incorporate Chaos testing into product and technology selection processes. Would be great to include chaos tests as a part of procurement processes as well for self-hosted and SaaS based systems. Seems like a no-brainer but first I've heard.

Opinion: the first and the last topics above (observability and automating chaos) seem to be picking up a lot of steam across the industry. The former is so critical I'm always curious as to *why* it's taken so long for the industry to really pay attention.
@adrianco is covering examples of Epidemic failures. Definitely a term I've never heard of before:
- Linux leap
- Sun SPARC cache bit-flip
- Cloud zone or region failure
- DNS failure (ok definitely seen this plenty of times - there's a great haiku about this)
- Linux leap
- Sun SPARC cache bit-flip
- Cloud zone or region failure
- DNS failure (ok definitely seen this plenty of times - there's a great haiku about this)
@adrianco - "Disaster recovery scenarios in the past have been tough because we were never certain that our failover datacenters were in the same state as our primary - drift is natural. Cloud provides the automation enabling disaster recovery in a low cost repeatable way"
We're likely to see Chaos Engineering take the place of disaster recovery tests in the past. The session is wrapped up!
Make sure to check out @ChaosConf for more details!
Make sure to check out @ChaosConf for more details!