,
30 tweets,
10 min read
Read on Twitter
On-chain mixing - A few thoughts about the challenges created by heterogeneous participants, postmix behaviors and statistical analysis. #SorryForTheLongThread
Disclaimer: It's well known (and repeated) that 2 important challenges for on-chain mixers are sybil attacks by malicious actors and the need for a large anonymity set. So, they won't be the subject of this thread.
Let's just note that it's not always easy to measure the exact size of the anonymity set. Thus, liquidities entering the mixer are sometimes used as a proxy metrics for the kind of anonymity set that you may expect from the mixer...
The main issue with this proxy metrics is that it completely ignores an important ingredient of mixing: the homogeneity of the participants; in all theirs aspects (liquidity injected in the mixer, premix and postmix behaviors, etc).
To understand this point, it's first important to keep in mind that blockchain analysis isn't limited to the analysis of the transactions graph.
Statistical analysis is another useful tool in the toolbox.
Statistical analysis is another useful tool in the toolbox.
For instance, statistical analysis can be useful for detecting patterns or outliers resulting from the activity of a small number of actors...
See this old post illustrating how a couple of entities are able to create a pattern at the level of the whole Bitcoin blockchain.
bitcointalk.org/index.php?topi…
bitcointalk.org/index.php?topi…
This is s similar approach that led to the detection of 3 waves of activity and the detection of a step pattern in the recent analysis published by @SamouraiWallet.
@SamouraiWallet As an additional illustration of how this kind of approach can be used for the analysis of mixing services, here's another example which wasn't published in the report...
@SamouraiWallet The starting point is the observation that after having mixed their UTXOs, it's likely that users will aggregate some postmix UTXOs (for the need of a payment or just for convenience).
Let's see if we can learn something from the distribution of these clusters of addresses.
Let's see if we can learn something from the distribution of these clusters of addresses.
@SamouraiWallet This is what we get.
Let's start with the obvious:
- the distribution seems to have a "natural" decreasing shape (many "poors", few "riches")
- a few outliers with a lot of addresses caused by massive aggregations of postmix UTXOs (bad!)
Let's start with the obvious:
- the distribution seems to have a "natural" decreasing shape (many "poors", few "riches")
- a few outliers with a lot of addresses caused by massive aggregations of postmix UTXOs (bad!)
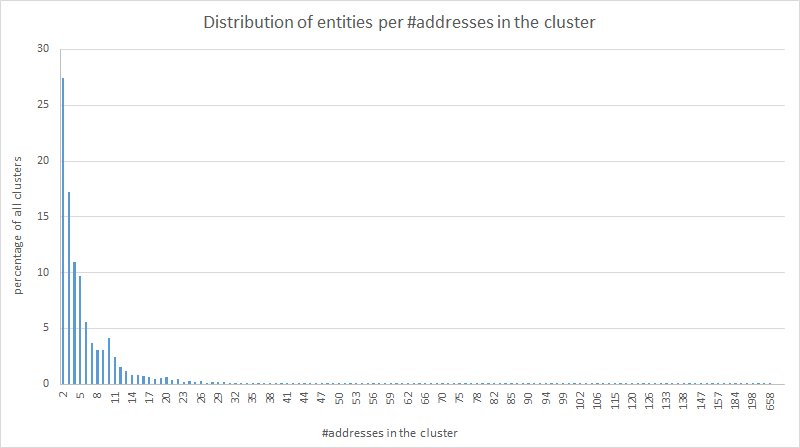
@SamouraiWallet But the most interesting observation is certainly the outlier occurring for clusters of 10 addresses.
My main hypothesis here is that some privacy-conscious users avoid large aggregations by gatheting theirs UTXOs in chunks of 10 addresses/UTXOs.
My main hypothesis here is that some privacy-conscious users avoid large aggregations by gatheting theirs UTXOs in chunks of 10 addresses/UTXOs.
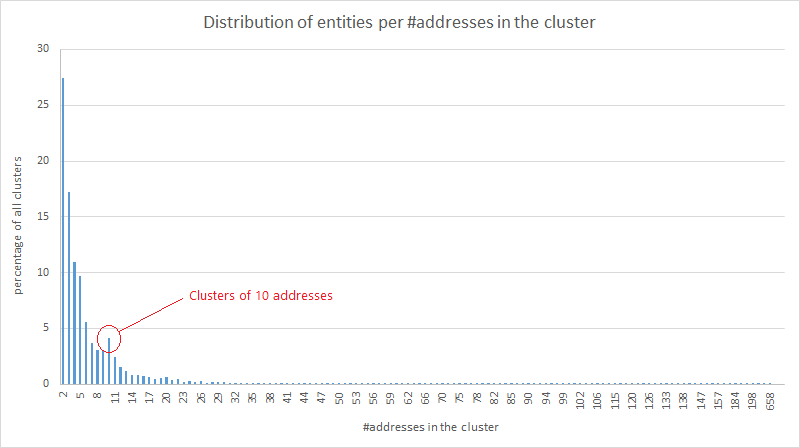
@SamouraiWallet In order to confirm this hypothesis, let's check the same statistics but this time limited to clusters with occurrences of address reuse...
@SamouraiWallet My rationale here is that address reuse is most likely the result of users mixing large amounts. As a consequence these users are more likely to face the dilemma of how to manage their postmix UTXOs.
@SamouraiWallet Two observations can be made here:
- outliers exist for clusters of 10 addresses but also for clusters of 9 addresses,
- the divergence from the "normal" is larger than what we observed for the general case.
- outliers exist for clusters of 10 addresses but also for clusters of 9 addresses,
- the divergence from the "normal" is larger than what we observed for the general case.
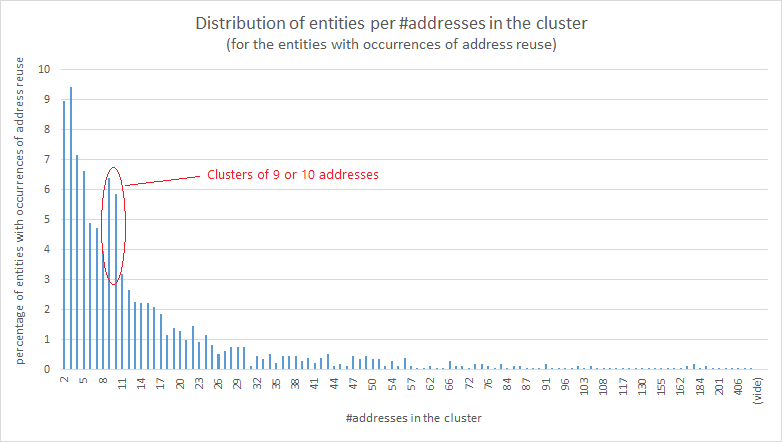
@SamouraiWallet I stopped the analysis at this point but I'm pretty confident that it could be extended by a statistical analysis applied to others metrics or by switching to an analysis of the transactions graph...
@SamouraiWallet For instance, we could analyze the postmix activity of these entities (on several depth levels) in order to improve the clustering. Here's an example of a user applying a 2-levels aggregation. You get the idea.
(second level of aggregation: oxt.me/transaction/ti…)
(second level of aggregation: oxt.me/transaction/ti…)
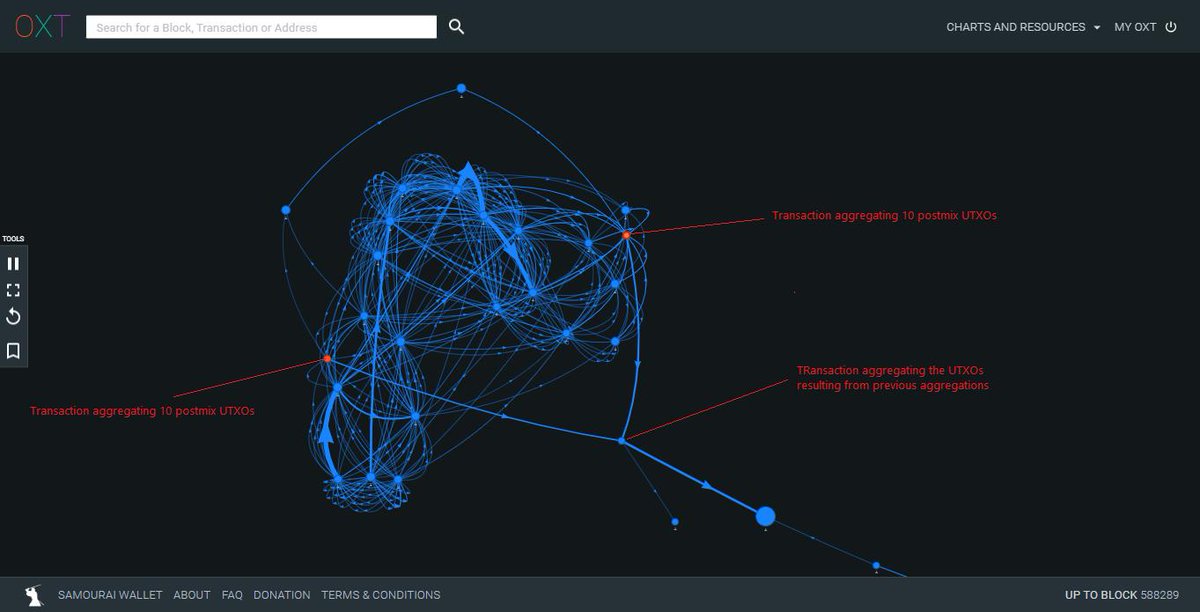
@SamouraiWallet The "harsh" lesson taught here is that even if you're a privacy-conscious user, it's quite possible that your efforts to avoid privacy leaks (large aggregations) mayl lead to a privacy leak (you're one of the few users repeatedly aggregating their postmix by chunks of n UTXOs).
@SamouraiWallet Ok. Enough for the challenges created by statistical analysis.
Now let's focus on the challenges raised by heterogeneous participants...
Now let's focus on the challenges raised by heterogeneous participants...
@SamouraiWallet In a perfect world, all the users of a mixer would be strictly similar (same amounts injected into the mixer by periods of time, same premix and postmix behaviors, etc)...
@SamouraiWallet But as illustrated by the previous example, reality is far from this perfect world. More than likely, specific premix and postmix behaviors will leak something impacting your privacy.
@SamouraiWallet But let's focus on a specific type of heterogeneity and let's ponder this question: What is the impact of a participant injecting an amount far larger than the average into a mixer?
@SamouraiWallet Usually, the answer to this question is that it's a bad situation because this participant may be malicious and may deanonymize others users.
While these concerns may be valid, I think they still miss the real issue...
While these concerns may be valid, I think they still miss the real issue...
@SamouraiWallet IMHO, the real issue is that even if such a user is honest, the situation is still likely to be the source of privacy leaks impacting this user and the others users of the service...
@SamouraiWallet The rationale here is based on 2 simple observations.
First, such a user will generate a lot of postmix UTXOs which are as many potential anchors for a statistical analysis of postmix behaviors.
First, such a user will generate a lot of postmix UTXOs which are as many potential anchors for a statistical analysis of postmix behaviors.
@SamouraiWallet Secondly, human beings are creature of habits.
We suck at generating true randomness and we suck at perfectly imitating a specific behavior (distribution) which isn't our "natural" behavior.
We suck at generating true randomness and we suck at perfectly imitating a specific behavior (distribution) which isn't our "natural" behavior.
@SamouraiWallet This kind of heterogeneity creates even more challenges if we inject a malicious actor into the mix (pun intended) but this thread is already too long, so let's forget that for now.
@SamouraiWallet The takeaways are:
- malicious sybil attacks are a real challenge but they're not the only one,
- heterogenous users are a serious (and underrated) challenge,
- premix and postmix behaviors matter (a lot),
- acknowledging the existence of these challenges is a first good step.
- malicious sybil attacks are a real challenge but they're not the only one,
- heterogenous users are a serious (and underrated) challenge,
- premix and postmix behaviors matter (a lot),
- acknowledging the existence of these challenges is a first good step.
@SamouraiWallet Final note: This thread may seem very pessimistic. Don't get me wrong, I definitely think that it's possible to mitigate some of these issues.
Possible "solutions" will be a subject for another thread.
Possible "solutions" will be a subject for another thread.
@SamouraiWallet /end