💡Econometrics Thread💡”Cherry Picking with Synthetic Controls” by Ferman, Pinto and Possebom (2020, bit.ly/3bGKum7).
It was a long journey, but we have finally published our paper at @JPAM_DC. I’m really happy to see it on the journal’s website.
It was a long journey, but we have finally published our paper at @JPAM_DC. I’m really happy to see it on the journal’s website.
I would like to thank the editor, Burt Barnow, and three anonymous referees whose comments helped us to improve our article.
Moreover, my co-author, @bruno_ferman, has joined Twitter. Let’s welcome him in our #EconTwitter community. In his webpage (bit.ly/2UEtea5), you can find his other papers. If you are interested in the SCM, like @causalinf , you will like many of his other papers.
My other co-author, Cristine Pinto, is not on Twitter, but check her webpage find other cool research topics! sites.google.com/site/cristinep…
What is the SCM? The SCM is a common way to analyze case studies. It is very cool because it decreases the discretionary power of the researcher by forcing her to use a data-driven method to choose the comparison unit. IMO, that’s one of the reasons behind the SCM’s popularity.
What is this paper about? We argue that the researcher still has a lot of discretionary power and may use it to find falsely significant results. This possibility comes from the fact that there is no consensus about the SCM specification.
Should we use all pre-treatment periods? Should we use their mean? Should we add covariates? Applied researchers have been very creative when choosing their specifications, because that’s a hard to answer question! 
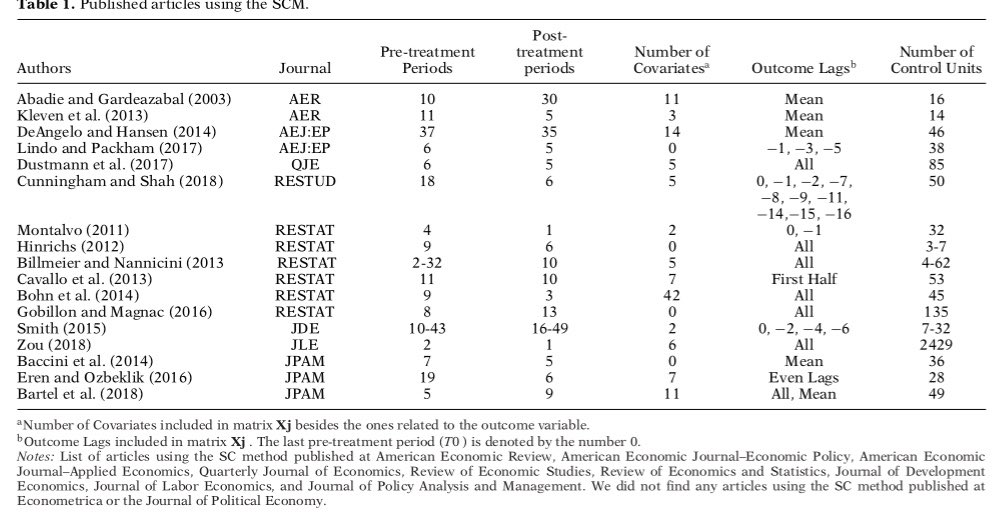
Our paper discuss whether researchers can cherry-pick their results by using different specifications. Our theoretical results are positive, but our simulation and empirical results suggest that our theoretical optimism is exaggerated in the real world.
Theoretically, if you only use specifications whose number of included pre-treatment periods grows when the pre-treatment period gets large, your results are asymptotically robust to specification search. In the picture, you can see some of those specifications in the picture.

But, in applied work, researchers frequently use specifications that are not included in our theoretical results. For example, the pre-treatment mean is still a very common specification. Our simulation results try to understand what happens when such specs are considered.
Our simulations also discuss if sample sizes usually found in applications are large enough to ensure that our asymptotic robustness results are a good approximation of the real world. This is important cause it is common to find pre-treatment periods that are around 12 periods.
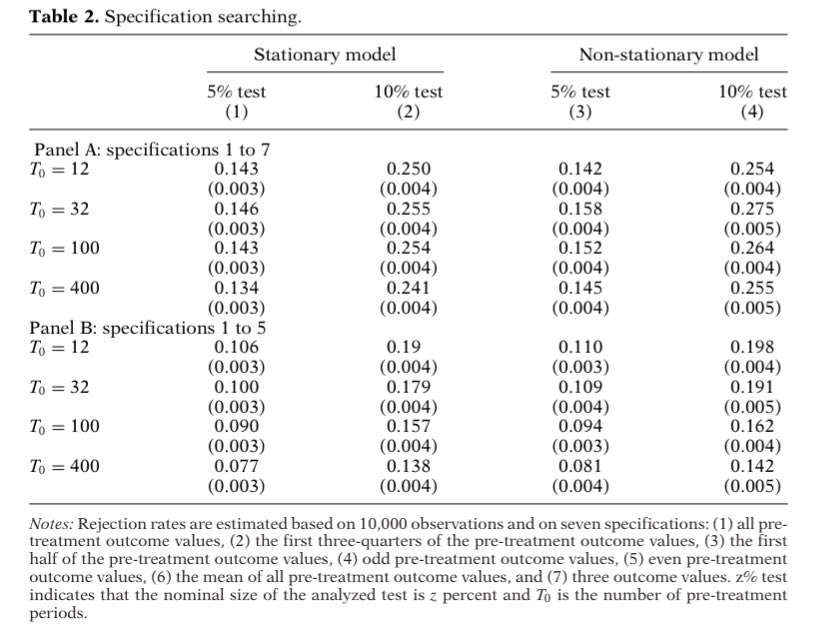
In panel A, we test the null using specs not included in our theoretical results. We find many opportunities for specification search. In panel B, we drop the problematic specs and life improves a lot. But there is still room for cherry picking when pre-T period is short.
So people should be cautious when reading SC papers and take into account those concerns. But what can a researcher do to shield herself against cherry picking opportunities? We have a couple of recommendations!
1) The SC that uses all pre-treatments periods is a good benchmark and should always be reported.
2) If you need to include covariates, use only specs that are included in our theoretical results. They are much more robust and stable.
2) If you need to include covariates, use only specs that are included in our theoretical results. They are much more robust and stable.
3) Be transparent. Show results for more than one spec.
4) Inference should account for the use of more than one spec. Combine all of them in one test statistic to control size.
4) Inference should account for the use of more than one spec. Combine all of them in one test statistic to control size.
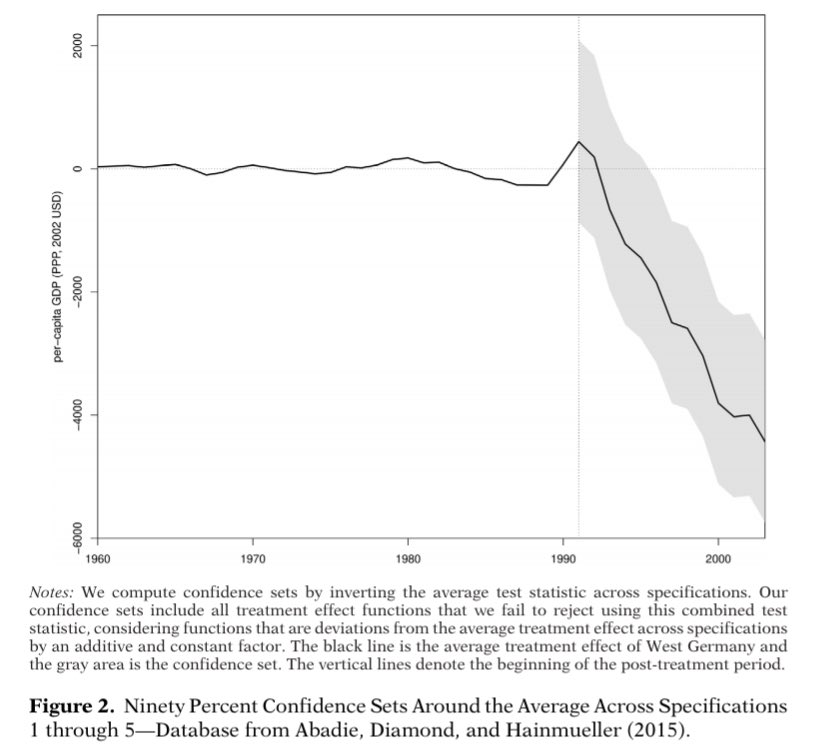
5) Point-estimates are hard to interpret when there is more than o e specification. So, we recommend to focus on set identification. @sergiopfirpo and I have a paper about confidence sets and the SCM. (bit.ly/3dzT2wI)
At the very least, focusing on confidence sets can give you some pretty figures. They are also a greate way to summarize uncertainty about the magnitude of treatment effects.
6) Our last recommendation is to use a choice criterion in order to choose a SC specification. @arindube and Zipperer (2015) proposed an easy-to-implement criterion.
At the end, we apply our recommendations to some empirical applications to illustrate that they can provide robust conclusions even when there opportunities for cherry picking.
I hope you enjoyed this thread as much as I enjoyed writing it. I’m super happy with the final outcome of this paper and it was an amazing experience to write it with Bruno and Cris!
Just to illustrate that this question is hard, there are other papers analyzing different SC specifications and they find different conclusions than us: gregor-pfeifer.net/files/SCM_Pred…, by Kaul, Klöbner, @gregor_pfeifer and Schieler.