After digging a bit deeper, I have a strong suspicion about how #CambridgeAnalytica was doing their targeting.
My theory: Cambridge Analytica was matching users with political messages using the exact same technique Netflix uses to recommend you movies.
My theory: Cambridge Analytica was matching users with political messages using the exact same technique Netflix uses to recommend you movies.
If I’m right, press coverage (and CA’s hype) has it backwards: The predictions themselves DO NOT depend on psychometrics, not really.
On the other hand, if my guess is correct, CA’s targeting was likely state of the art. I expect it worked exceedingly well.
On the other hand, if my guess is correct, CA’s targeting was likely state of the art. I expect it worked exceedingly well.
To understand what I think is going on, think back a decade ago to the Netflix Prize. Netflix offered a million dollars to any team of researchers who could improve their algorithms for recommending movies.
But the contest showed that there was a better way. It was possible to condense all of a users’ ratings into a series of *factors* -- essentially, a list of inferred categories, ranked by importance or predictive power.
As @simonfunk explained: "a category might represent action movies, with movies with a lot of action at the top, and slow movies at the bottom, and correspondingly users who like action movies at the top, and those who prefer slow movies at the bottom.”
sifter.org/simon/journal/…
sifter.org/simon/journal/…
Funk’s revised version of SVD (short for Singular Value Decomposition), adapting work from @GMGorrellUK, ended up being the biggest part of the Netflix prize solution.
It remains pretty much state-of-the-art for predicting what users will like.
It remains pretty much state-of-the-art for predicting what users will like.
So what does this have to do with Cambridge Analytica? This Motherboard article from last year, I think, hints at the answer.
motherboard.vice.com/en_us/article/…
motherboard.vice.com/en_us/article/…
Aleksandr Kogan -- the researcher who passed Facebook data to Cambridge Analytica -- reportedly approached fellow Cambridge researcher @michalkosinski in 2014 about sketchy election consulting. Kosinski apparently said no, reported this, and a intra-university fight ensued.
The MB article says : “Kosinski came to suspect that Kogan's company might have reproduced the Facebook ‘Likes’-based Big Five measurement tool in order to sell it to this election-influencing firm.”
If so, what would that mean?
If so, what would that mean?
Take a look at the 2013 PNAS paper that @michalkosinski @david_stillwell and @ThoreG published, the one that seemingly attracted Kogan’s attention (and reportedly got Kosinski both a job offer and a lawsuit threat (!) from Facebook on the same day). pnas.org/content/pnas/1…
Figure 1 is below. This is a Netflix Prize-style approach: First, use SVD to reduce user likes (art, CNN, BMW, etc.) into a set of inferred categories or factors.
Then use the 100 most powerful factors to predict users’ age, race, partisanship, or even personality.
Then use the 100 most powerful factors to predict users’ age, race, partisanship, or even personality.
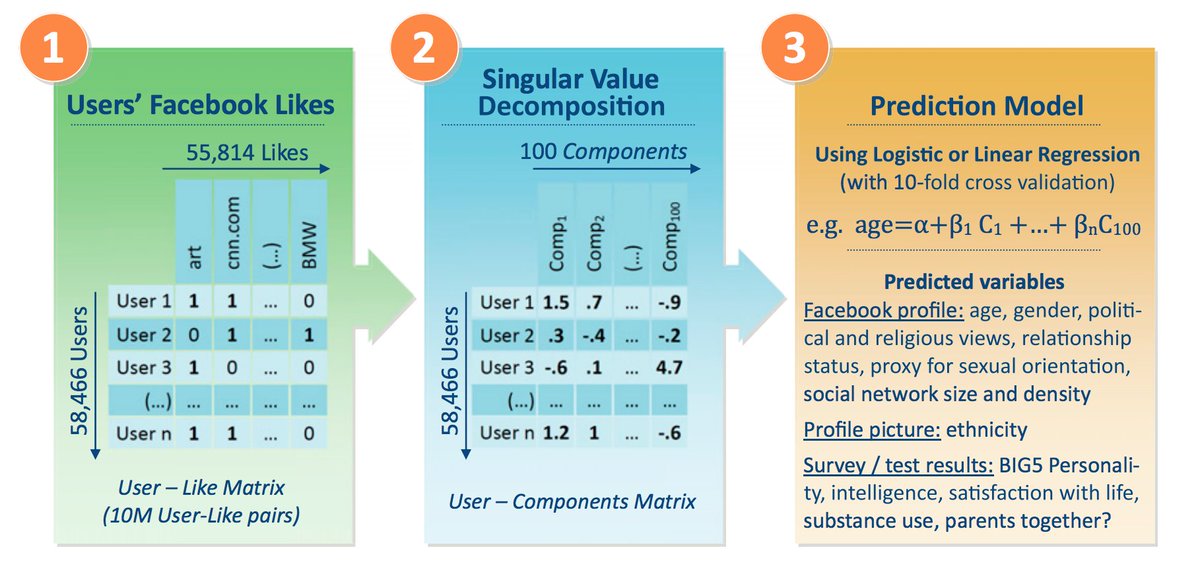
This is a smart approach, and post-Netflix Prize it has become a de facto industry standard. (Indeed, it’s exactly what I *am* doing in an unrelated project.) Tools to do this are widely available, so reverse engineering is easy.
But note: if CA *did* reverse-engineer this technique, the predictions WOULD NOT come from a five-factor model of personality.
I mean, you *could* use the model to *predict* personality, if you want. And the researchers do, which is great.
But you can also use it to predict age. Or race. Or partisanship. Or almost anything correlated with Facebook behavior.
But you can also use it to predict age. Or race. Or partisanship. Or almost anything correlated with Facebook behavior.
For the best predictions, you typically use these recovered factors *directly*. Don’t predict something (noisily) to then (even more noisily) predict what you really care about. That’s @eitanhersh’s point here -- but I doubt CA did that.
Even with something like race or age, you’d likely want to use the factors themselves, not use guesses about age in some downstream model.
So what was with the psychometric talk, and the use on these terms on internal dashboards? Just puffery and salesmanship? Maybe, but my guess is CA was using these labels to *interpret* the models, not to *produce* them.
The biggest problem with factor analysis is that the categories it produces are difficult to interpret.
Consider movies: How would you label a category anchored on one end by movies like Pearl Harbor and The Wedding Planner -- and on the other by Lost in Translation and The Royal Tannenbaums?
These are very different sorts of movies, but it’s tough to give them a clear label.
These are very different sorts of movies, but it’s tough to give them a clear label.
The Facebook factor analysis presents CA with the same problem -- and if you can’t explain the model, you can’t sell it to clients.
But the Big Five models, which had *already* been roughly mapped to the Facebook data, provide a solution.
But the Big Five models, which had *already* been roughly mapped to the Facebook data, provide a solution.
You can say that you’re targeting people with low openness to experience and high neuroticism -- and it’s kind of true!
But the *same exact model* could, just as accurately, be sold as targeting (say) low-education older Republican men.
But the *same exact model* could, just as accurately, be sold as targeting (say) low-education older Republican men.
These inferred categories necessarily capture personality AND demographics TOGETHER, and for politics it seems likely that it’s the demographics are doing the heavy lifting.
Caveats: The above is all built on speculation and semi-educated guesswork, and the nitty gritty details of CA’s targeting is still unknown.
Even if all of the above are true, it’s really *constant*, iterative testing to map messages to these factors that makes this work.
Even if all of the above are true, it’s really *constant*, iterative testing to map messages to these factors that makes this work.
But given what we DO know, it’s more than plausible that CA’s models were quite effective, even if the predictions were not generated in quite the way they claimed.
Bonus: for an intro to SVD, @jure has a great series on YouTube. Highly recommended: