,
10 tweets,
18 min read
Read on Twitter
Hey, internet: just in case you're not one of those engineers who hears "Hey, compilers!" and comes running delightedly, here's a thread on why I think #MLIR is going to transform the machine learning industry:
(1/n)
for more technical details, ref: ai.google/research/pubs/…
(1/n)
for more technical details, ref: ai.google/research/pubs/…
We're seeing an explosion of domain-specific accelerated hardware (yay!).
@GoogleAI's TPUs are an example of this, sure; but you also have @Apple's specialized chips for iPhones, @BaiduResearch's Kunlun, and literally *thousands* of others.
The way that you program for
(2/n)
@GoogleAI's TPUs are an example of this, sure; but you also have @Apple's specialized chips for iPhones, @BaiduResearch's Kunlun, and literally *thousands* of others.
The way that you program for
(2/n)

@GoogleAI @Apple @BaiduResearch these chips right now isn't easy.
Developer-facing tooling is essentially non-existent (or quite bad, even for TPUs); many models are built, and then found to be impossible to deploy to edge hardware; etc.
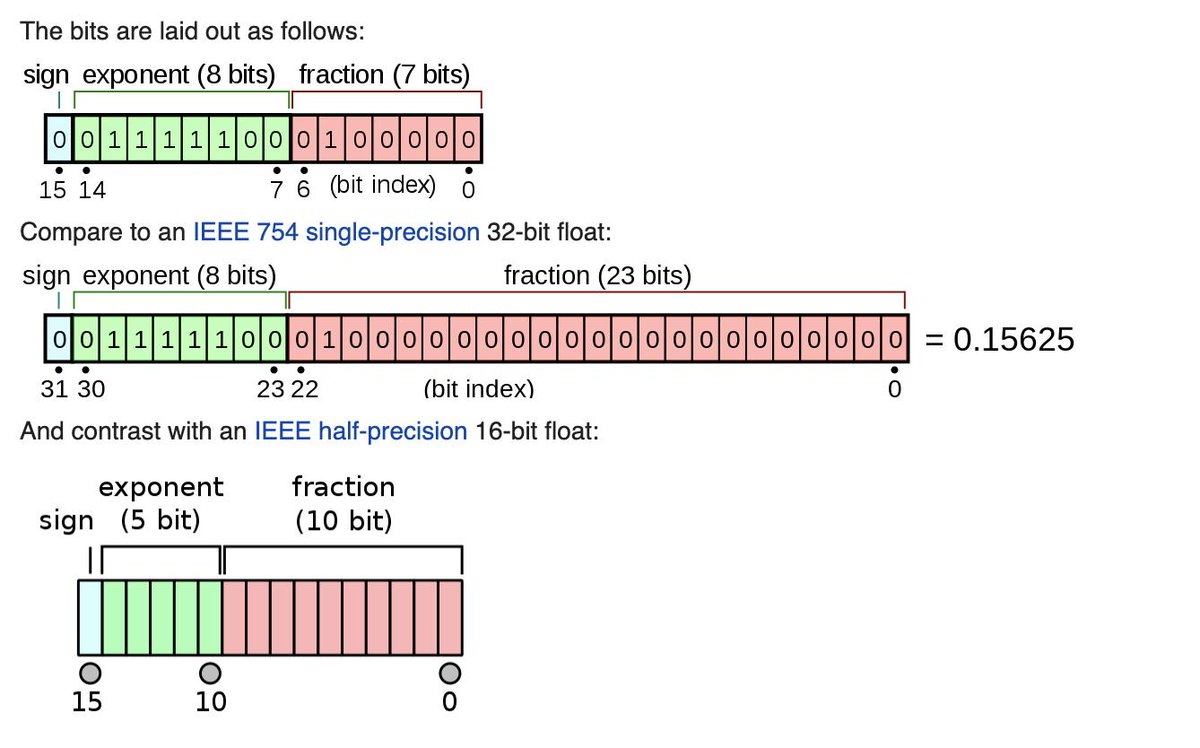
You also have very rad, but specialized types (e.g., bfloat16).
(3/n)
Developer-facing tooling is essentially non-existent (or quite bad, even for TPUs); many models are built, and then found to be impossible to deploy to edge hardware; etc.
You also have very rad, but specialized types (e.g., bfloat16).
(3/n)
@GoogleAI @Apple @BaiduResearch "If this hardware is so hard to use, then why attempt to deploy to it at all?", you may ask.
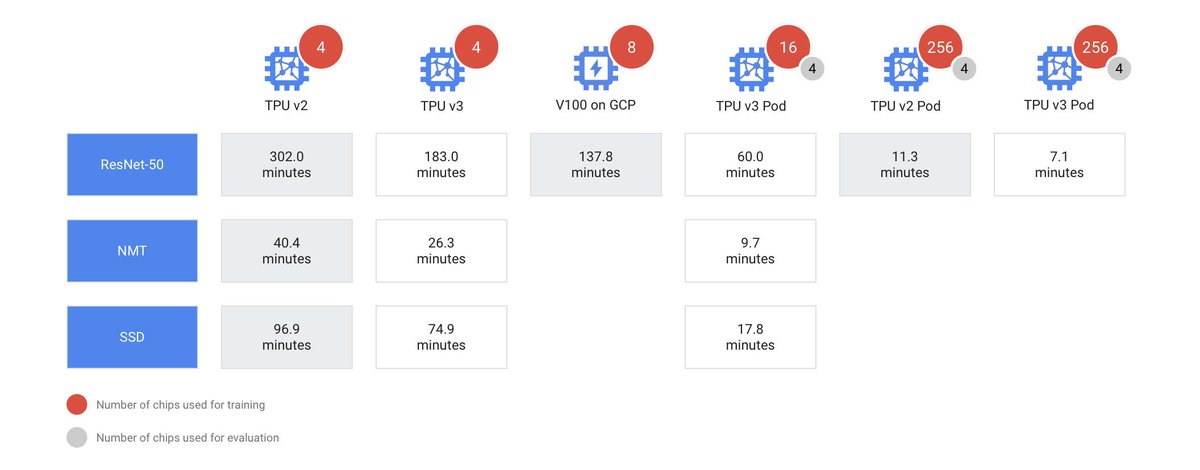
For @Google, it's saved us from increasing our number of data centers by a considerable amount ($$). It's also unlocked research for @DeepMindAI that would have been impossible.
(4/n)
For @Google, it's saved us from increasing our number of data centers by a considerable amount ($$). It's also unlocked research for @DeepMindAI that would have been impossible.
(4/n)
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI And it isn't just about training: it's also inferencing.
Imagine trying to deploy a machine learning-enabled app to @Android phones. You'd have to know which ops could be accelerated *for each device*; which to run on GPU, and which to kick back to CPU.
It's crazypants.
(5/n)
Imagine trying to deploy a machine learning-enabled app to @Android phones. You'd have to know which ops could be accelerated *for each device*; which to run on GPU, and which to kick back to CPU.
It's crazypants.
(5/n)
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI @Android Products like @TensorFlow Lite remove a bit of the complexity; but engineers on the @Google side still had to be tasked with figuring out how to support all those devices. 😨
As programmers, none of us should have to be concerned about this nonsense. We should be able to
(6/n)
As programmers, none of us should have to be concerned about this nonsense. We should be able to
(6/n)
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI @Android @TensorFlow write in any language we choose, using any framework (@TensorFlow, scikit-learn, @PyTorch, ML.NET, whatever) and have ops automatically lowered, if they can be run on accelerated hardware.
Anything not runnable on GPU/TPU could be punted back to the CPU.
(7/n)
Anything not runnable on GPU/TPU could be punted back to the CPU.
(7/n)
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI @Android @TensorFlow @PyTorch If this sounds familiar and LLVM-y, that was by design: Chris Lattner's teams at @GoogleAI are leading the effort. 😁
You can think of MLIR as a layer on top of LLVM, that allows you to focus on writing high-level code, instead of how to optimize ops or where to deploy.
(8/n)
You can think of MLIR as a layer on top of LLVM, that allows you to focus on writing high-level code, instead of how to optimize ops or where to deploy.
(8/n)
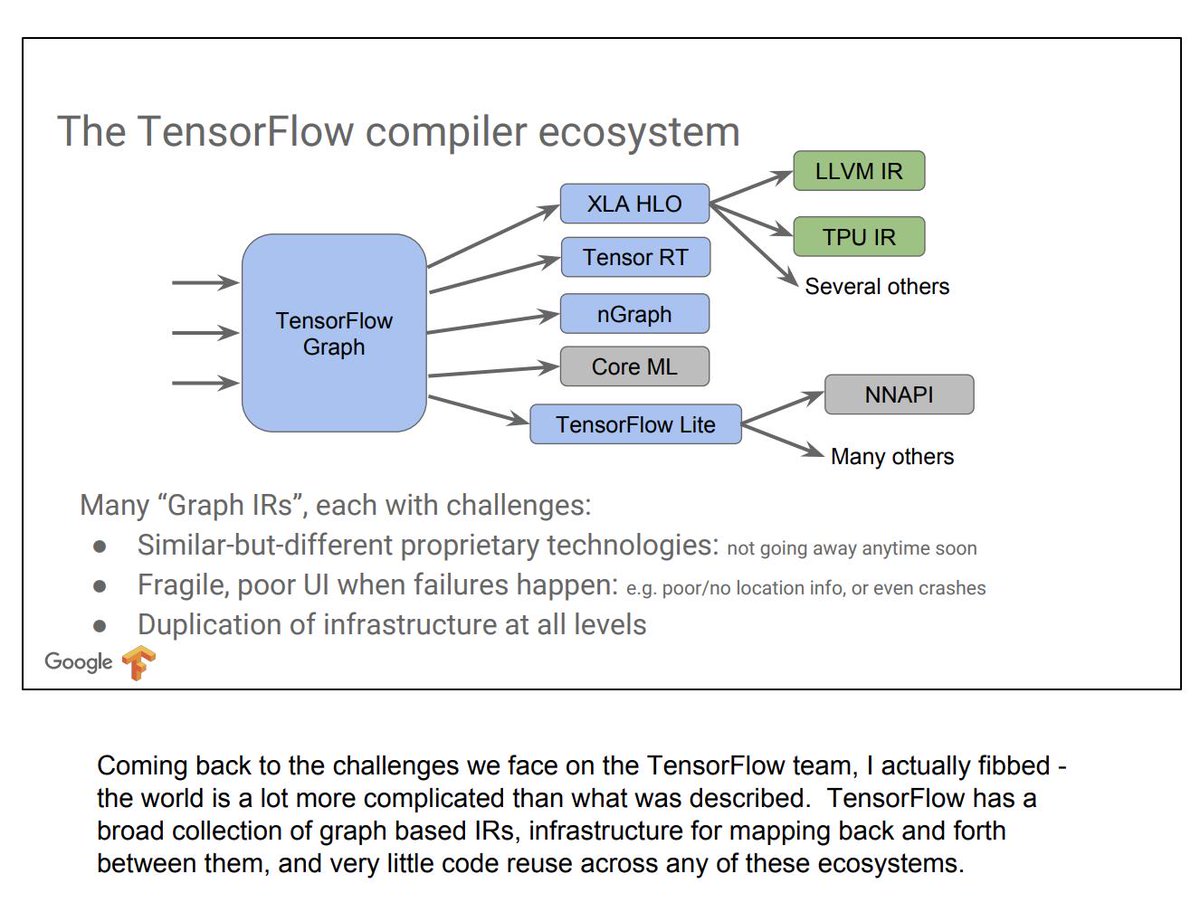
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI @Android @TensorFlow @PyTorch You can also do 🤯 things, like create custom CUDA kernels within a @ProjectJupyter notebook, using #SwiftLang.
If you're interested in these things (I hope you are!), join in our open design meetings / mailing lists:
MLIR: groups.google.com/a/tensorflow.o…
#S4TF: groups.google.com/a/tensorflow.o…
If you're interested in these things (I hope you are!), join in our open design meetings / mailing lists:
MLIR: groups.google.com/a/tensorflow.o…
#S4TF: groups.google.com/a/tensorflow.o…
@GoogleAI @Apple @BaiduResearch @Google @DeepMindAI @Android @TensorFlow @PyTorch @ProjectJupyter Additional references:
Mehdi's LLVM tutorial on MLIR (April 2019): llvm.org/devmtg/2019-04…
Chris Lattner and Tatiana's keynote: llvm.org/devmtg/2019-04…
Chris' podcast with @lexfridman:
Rasmus + Tatiana's @Stanford course: web.stanford.edu/class/cs245/sl…
(fin)
Mehdi's LLVM tutorial on MLIR (April 2019): llvm.org/devmtg/2019-04…
Chris Lattner and Tatiana's keynote: llvm.org/devmtg/2019-04…
Chris' podcast with @lexfridman:
Rasmus + Tatiana's @Stanford course: web.stanford.edu/class/cs245/sl…
(fin)