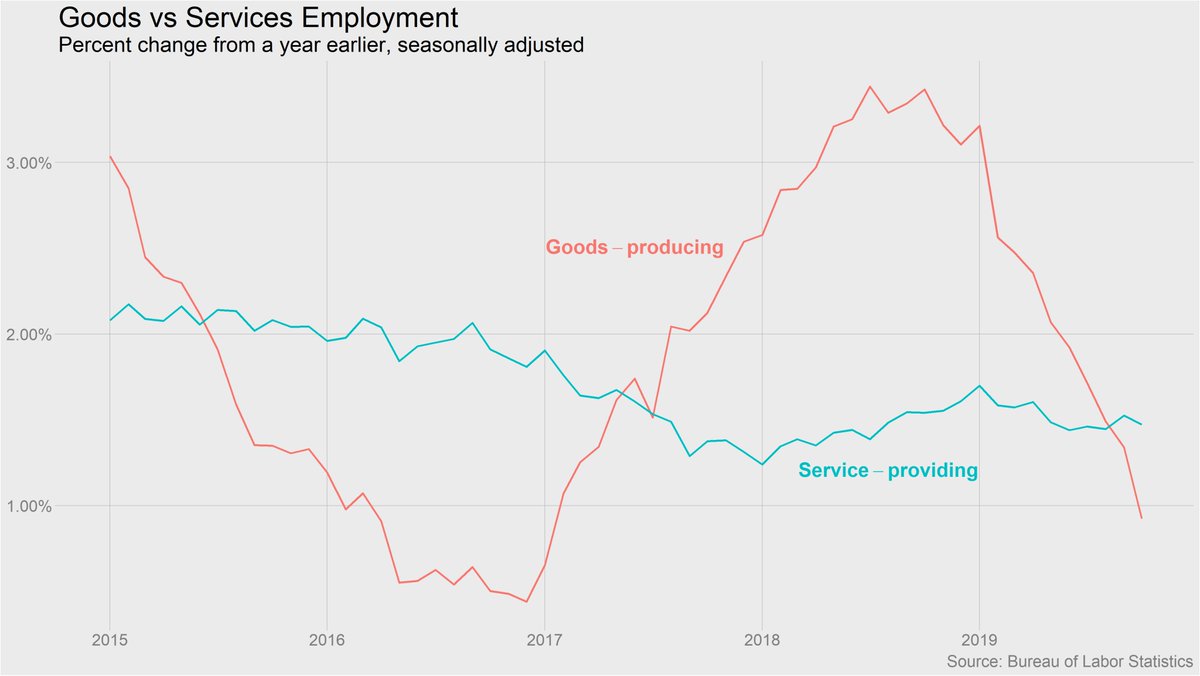
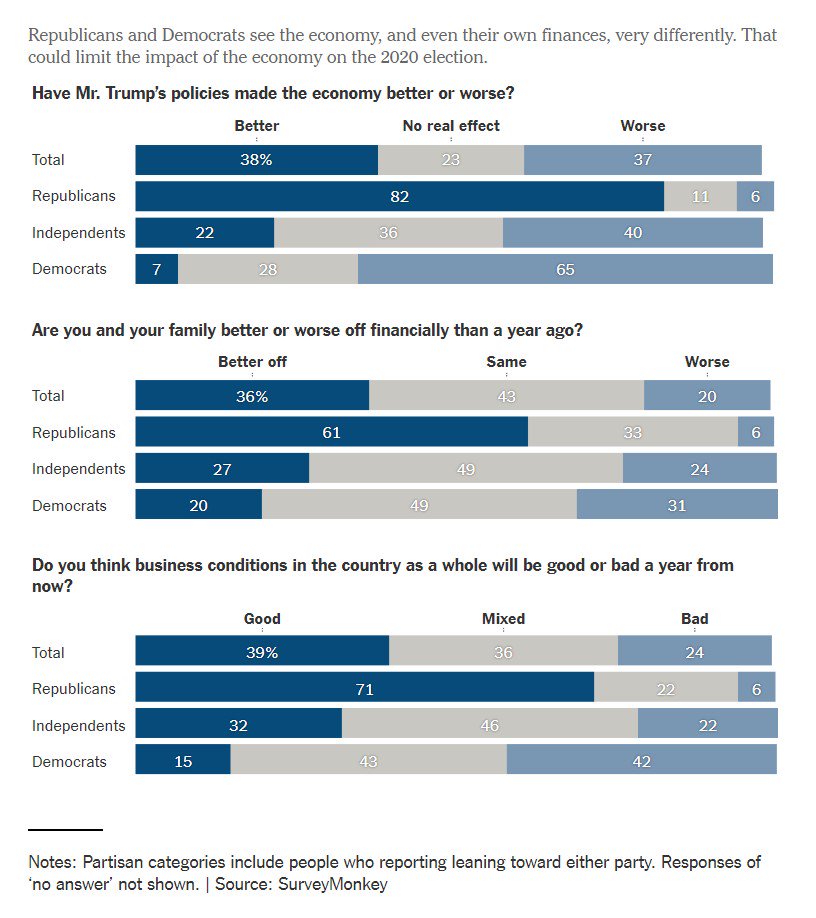
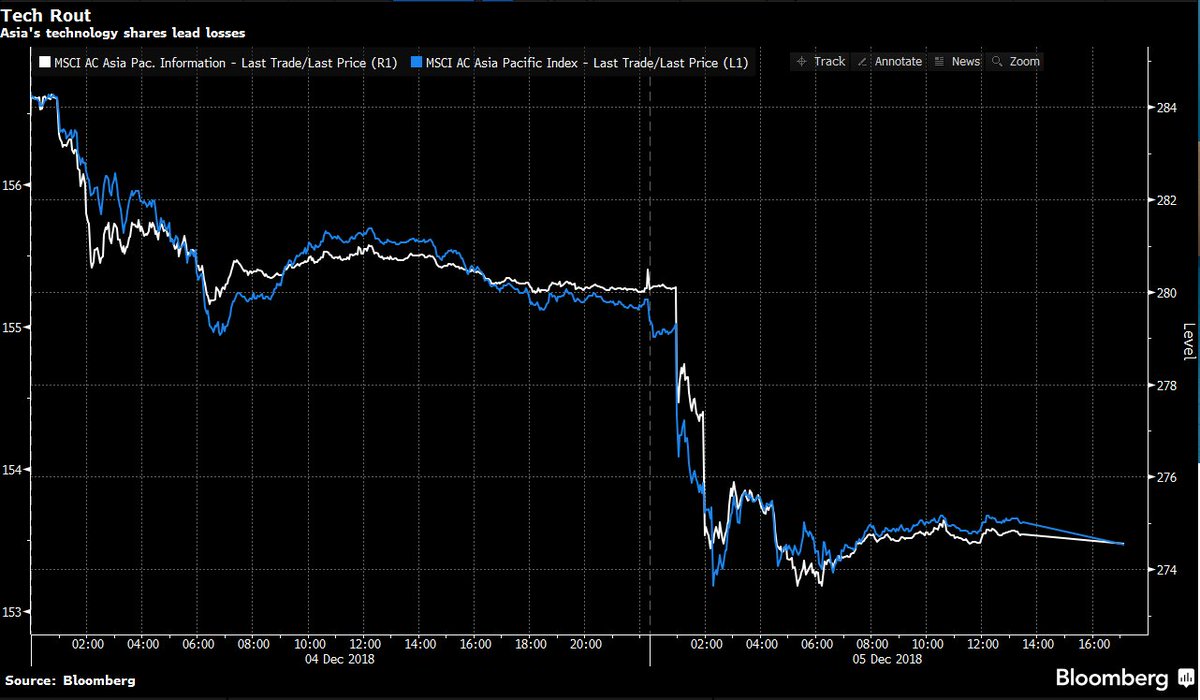
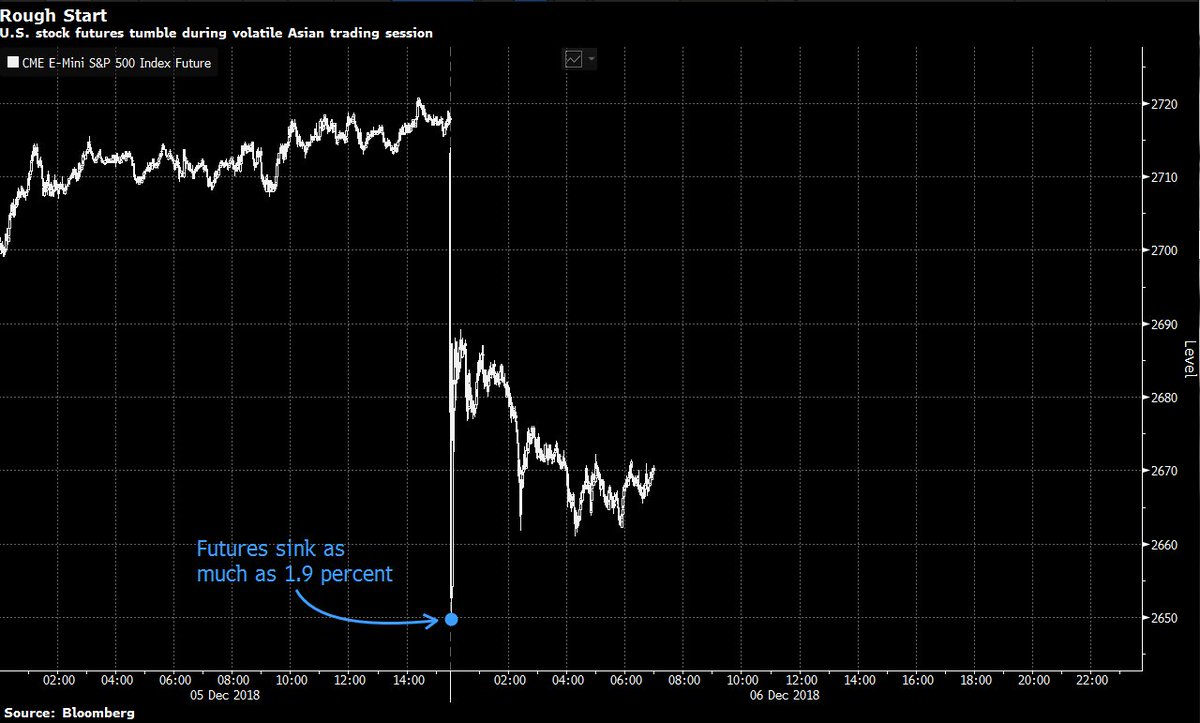
Smart (as always) @RichardRubinDC story on the debate over the new tax estimates from Saez and Zucman.
wsj.com/articles/who-p…
wsj.com/articles/who-p…
I think this debate highlights a challenge for those of us who write about policy. We often write as though there is data (about which we largely agree) and then there is interpretation/analysis/modeling (about which there is disagreement).
But that's not really how it works.
But that's not really how it works.
In an ideal world, we would be able to say, "The top 1% earn X% of income and pay Y% of taxes" (the data). And then we could all argue over what effect policy Z would have on that situation (the analysis).
But in the real world, that "data" is based on lots of modeling and assumptions. What should count as income? How should we apportion taxes that aren't directly assessed on individuals? How should we knit together older sources so that we can see trends over time?
There are legitimate, good-faith arguments about all those questions. (Also bad-faith arguments, which doesn't make things easier, but setting those aside for now.) They can significantly change what the "data" shows, even before you start debating the effects of policy.
And guess what? Pretty much *everything* we call "data" in economics is based to some degree on a model. Our jobs numbers are based on a survey, then filtered through models that account for things like business births/deaths and seasonal patterns.
GDP blends together a wide range of sources and (especially in preliminary releases) fills in gaps with assumptions and projections. And as we update our models, we revise the data, sometimes going back decades.
In some cases, these models are well enough established that there isn't much debate over them. But there are lots of areas where that isn't true, and not just on fringe issues, as the Saez-Zucman debate shows.
To be clear, this does *not* mean that you should dismiss economic data, or that it can be made to show whatever you want. (The major government statistics are produced according to consistent processes with lots of safeguards.)
But it does mean that you should ask where data is coming from, how it is produced, and whether the methods are widely accepted or are still being debated.
And, more generally, it means that we econ/policy journalists need to be careful when we talk about "data" as some immutable bedrock upon which policy debates are based. Often the data itself deserves scrutiny. </fin>
(By the way: I'm still wading through the substance of the arguments over the Saez-Zucman data, so not going to weigh in on that directly at this point.)