"The art of using t-SNE for single-cell transcriptomics" by @CellTypist and myself was published two weeks ago: nature.com/articles/s4146…. This is a thread about the initialisation, the learning rate, and the exaggeration in t-SNE. I'll use MNIST to illustrate. (1/16) 
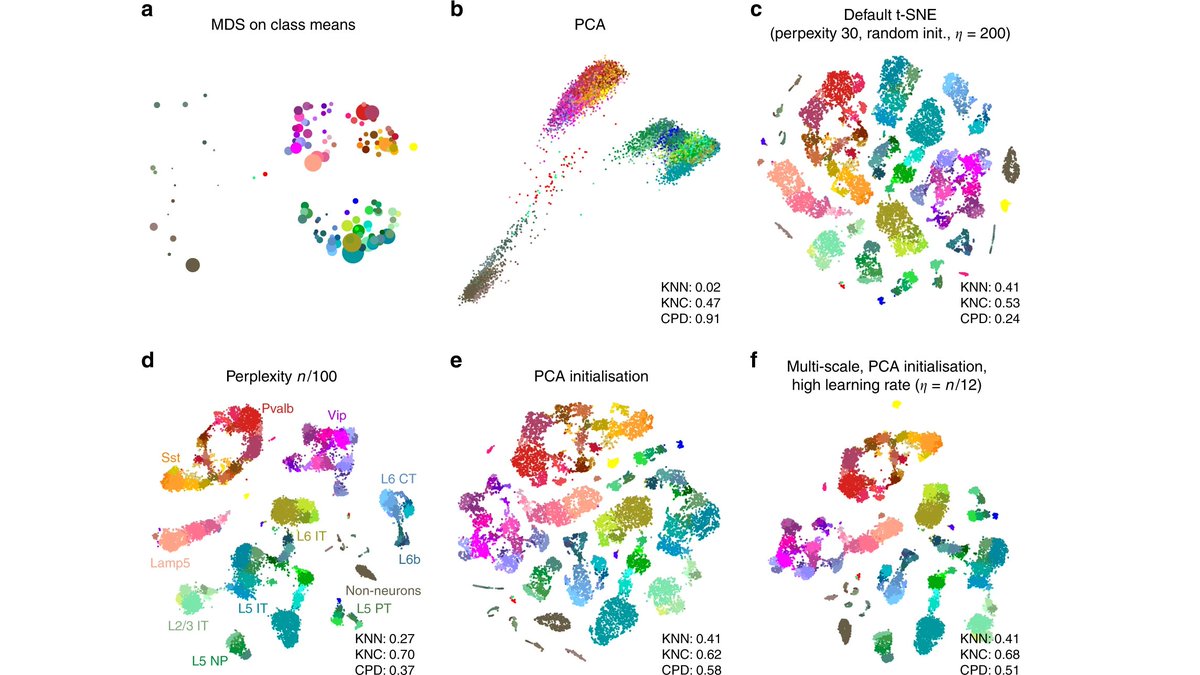
FIRST, the initialisation. Most implementations of t-SNE use random initialisation: points are initially placed randomly and gradient descent then makes similar points attract each other and collect into clusters. We argue that random initialisation is often a bad idea (2/16).
The t-SNE loss function only cares about preserving local neighbourhoods. With random initialisation, the global structure if usually not preserved, meaning that the arrangement of isolated clusters is largely arbitrary and depends mostly on the random seed. (3/16)
A simple trick is to use PCA and take two first PCs as initialisation. PCs 1/2 often capture the most salient global structure, and this structure will survive through the gradient descent and be reflected in the final t-SNE embedding. Cf. these panels of our Figure 2. (4/16)

Importantly, PCA init. does not have any downsides and I believe is strictly better than random init. Some implementations, e.g. openTSNE, already use it as default. One can imagine other reasonable choices of initialisation, but random is not one of them. (5/16)
SECOND, the learning rate. The default learning rate in most implementations is 200, but it turns out it is too small for large data sets. Here are t-SNE embeddings of MNIST (n=70k) for two specific random initialisations. Notice how some digits are split. (6/16)
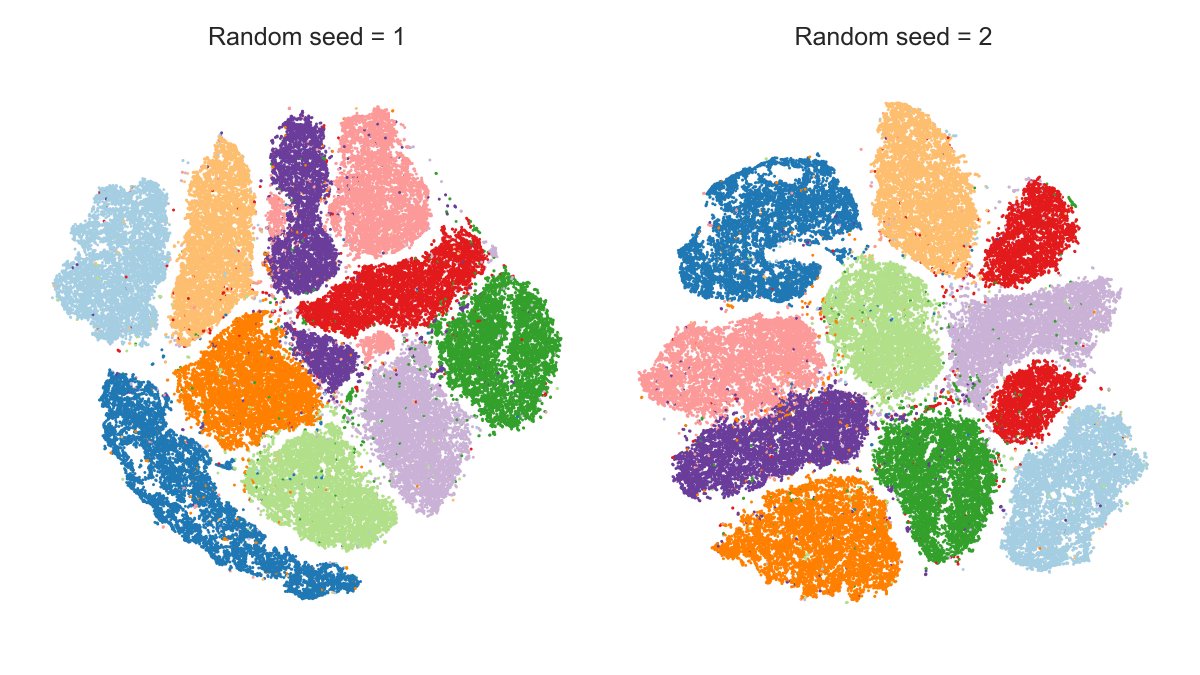
This does not happen if one increases the learning rate to 1000, as shown here. The reason is subtle and has to do with the so called early exaggeration phase of t-SNE optimisation. For it to work effectively, the learning rate should be high enough. (7/16)

This was thoroughly investigated in a paper by @Anna_C_Belkina published back-to-back with ours: nature.com/articles/s4146…. Based on the theoretical results by @GCLinderman (epubs.siam.org/doi/abs/10.113…), Belkina et al. recommend to set the learning rate to n/12. (8/16)
Here 12 is the default early exaggeration coef. I found it to work well, and our paper also endorses the n/12 choice. That learning rate 200 is often not enough, has been noticed previously; e.g. the default t-SNE learning rate in scanpy (@falexwolf @fabian_theis) is 1000. (9/16)
@falexwolf @fabian_theis 1000 works well for n~10k--100k (like MNIST), but for much larger sample sizes one needs to increase it even further. For example, Cao et al. (nature.com/articles/s4158…) used scanpy to run t-SNE on a n=2mln data set, and ended up with many clusters split into parts. (10/16)
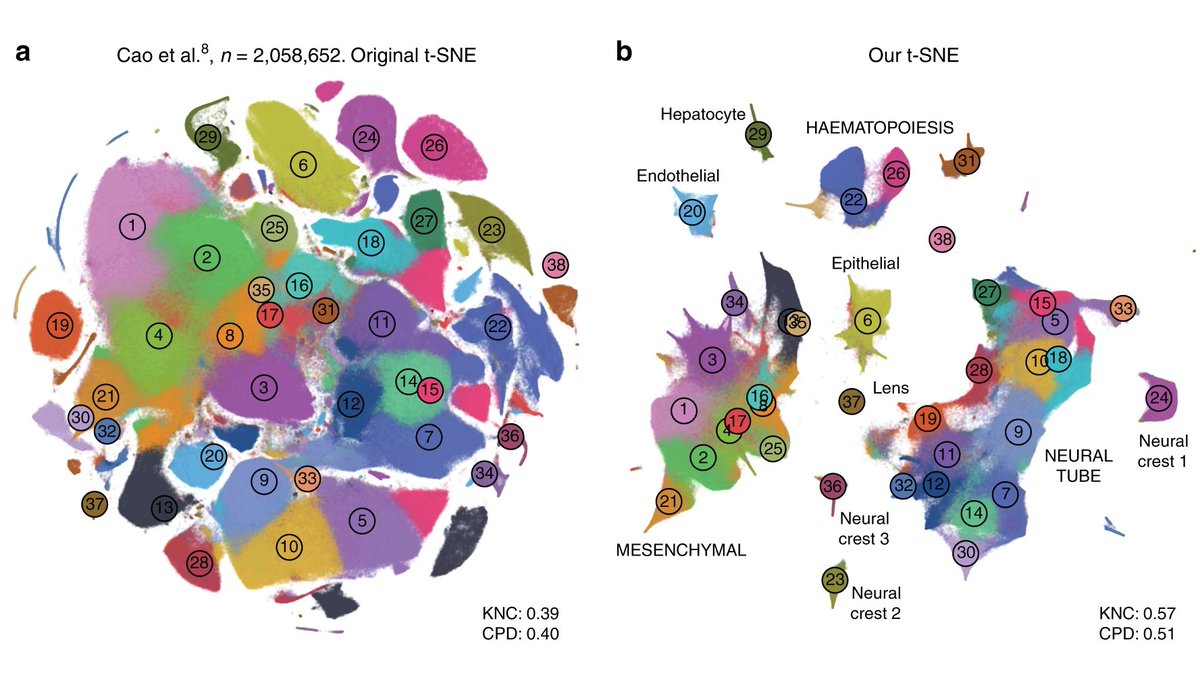
We recommend setting the learning rate to n/12. It works well for the Cao et al. data (n=2mln), and see Belkina et al. paper for an even larger example with n=20mln. (11/16)
THIRD, exaggeration. One property of t-SNE is that it does not leave a lot of white space between the clusters, especially for large data sets. If one wants to have more white space, one can use "exaggeration" which increases all attractive forces by a constant factor (12/16).
Here is the effect of setting exaggeration to 4 on MNIST. Not only there is more white space, but also some relationships between digits become more apparent (e.g. handwritten 4 is similar to 9: that's salmon and violet on top). (13/16)

Incidentally, exaggeration~4 seems to correspond pretty well to the default UMAP settings. Here shown for MNIST, but I have observed the same on many other data sets too. (14/16)

Exaggeration can be handy for very large data sets. In our paper, we re-analyze the Cao et al. data set (n=2mln) and show that exaggeration uncovers meaningful biological structures identified by the original authors. (15/16)

See the paper for more, including how to map new points to an existing t-SNE embedding, how to align multiple t-SNE embeddings to each other, etc. (16/16)