[Modélisation mathématiques] Et si on s'intéressait à des questions de modélisation mathématiques de modèles épidémiologiques, avec comme application la pandémie de #COVID19 ?
Spoiler warning : si mes résultats sont corrects, #RestezChezVousBordel
Spoiler warning : si mes résultats sont corrects, #RestezChezVousBordel
Une manière simple de modéliser une épidémie est de l'aborder d'une manière statistique, en considérant la population étudiée dans son ensemble, et en la classant dans des petites boites, ou compartiments.
Cette approche est parfois appelée SIR, pour Sain - Infecté - Résistant (ou retiré selon la léthalité du phénomène étudié)...
Et oui, je vois ce que vous avez derrière la tête, ça peut aussi modéliser des infection zombies \o/
Source : mysite.science.uottawa.ca/rsmith43/Zombi…
Et oui, je vois ce que vous avez derrière la tête, ça peut aussi modéliser des infection zombies \o/
Source : mysite.science.uottawa.ca/rsmith43/Zombi…
Je vais m'intéresser à un modèle avec un compartiment de plus, le modèle SEIR pour Sain - Exposé - Infecté - Résistant. Ça permet notamment de mettre un temps d'incubation asymptomatique et des porteurs sains dans le modèle...
Chaque personne appartient donc à un compartiment, et peut passer dans le suivant à un certain taux... Et qui dit taux dit équations différentielles \o/
Je pourrai faire un autre thread sur la signification de chacun des termes, mais voilà le modèle que je considère :
Je pourrai faire un autre thread sur la signification de chacun des termes, mais voilà le modèle que je considère :

En plus des quantités SEIR, qui dépendent donc du temps (nombre de jours depuis l'apparition des malades), on a aussi la quantité N, qui modélise la population totale (N = S + E + I + R), et différents paramètres qui vont pouvoir fixer le modèle...
Les trois principaux sont :
β est le taux d'exposition (sain -> exposé) ;
σ est le taux d'infection (exposé ->infecté) ;
ᵞ est le taux de guérison (infecté -> résistant).
Les deux autres sont différents :
μ est le taux de mortalité (disparition) ;
ν est le taux de vaccination
β est le taux d'exposition (sain -> exposé) ;
σ est le taux d'infection (exposé ->infecté) ;
ᵞ est le taux de guérison (infecté -> résistant).
Les deux autres sont différents :
μ est le taux de mortalité (disparition) ;
ν est le taux de vaccination
Notez la linéarité de tous les termes de ce système... sauf le passage de sain à exposé, qui est lui un quotient des différentes quantités. Ce modèle est donc assez nonlinéaire ! On ne pourra donc pas le résoudre à la main (pas de solution triviale donnée par une exponentielle)
Deux remarques : si μ est nul (pas de mortalité), ce modèle préserve la population totale (ouf)
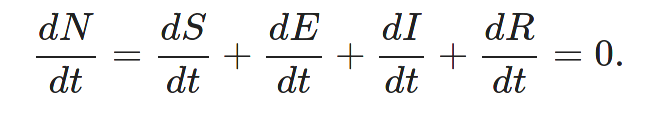
Le modèle n'est pas linéaire, mais il est homogène de degré 1 :
pour tout scalaire λ, si (S,E,I,R) est solution il en est de même pour (λS, λE, λI, λR)... ce qui explique les comportement universels remarques par @mixlamalice dans ses threads sur le sujet (lisez les)
pour tout scalaire λ, si (S,E,I,R) est solution il en est de même pour (λS, λE, λI, λR)... ce qui explique les comportement universels remarques par @mixlamalice dans ses threads sur le sujet (lisez les)
Prenons des paramètres au pif et regardons ce que ça donne. En supposant que l'on regarde des fractions de population (possible par homogénéité), voilà une solution en supposant initialement 10% de personnes exposées au virus : croissance polynomiale du nombre d'infectés !

Bon, mais peut-on estimer les paramètres pour qu'ils collent à la réalité de la maladie (ici #COVID19) et qu'on prédise son évolution ? La réponse est oui, grâce (uhuh) aux nombreux cas chinois. J'ai fait un notebook jupyter avec tous les détails, mais voilà ce que ça donne

En mettant ça dans le modèle et lançant la simulation avec la population du Hubei comme paramètre initialon obtient : croissance exponentielle du nombre d'infectés, jusqu'à atteindre un plateau et décroitre...
Notez que la mortalité ne joue pas (je ne comprends pas pourquoi 🤔)
Notez que la mortalité ne joue pas (je ne comprends pas pourquoi 🤔)

Bon, mais peut-on comparer ces simulations numériques à de vraies données ? Et plus philosophiquement : est-ce qu'un modèle composé de 4 équations différentielles ordinaires peut-il vraiment prédire l'évolution d'une pandémie globale ?
C'est là que j'utilise le génial thread de @alonsosilva permettant de récupérer en direct les données épidémiologiques publiées par le gouvernement. Un petit coup de magie avec pandas permet d'intégrer ces données à notre analyse, via
covid.ourworldindata.org/data/total_cas…
covid.ourworldindata.org/data/total_cas…
Voilà donc les courbes du nombre d'infecté (depuis qu'on en a testé plus de 100), pour la France, l'Italie et la Chine...

Du coup mettons cela dans notre modèle, utilisons les paramètre du Hubei et regardons ce que ça donne pour la France et l'Italie (avec un fix sur la mortalité du à @JacobLamblin) :
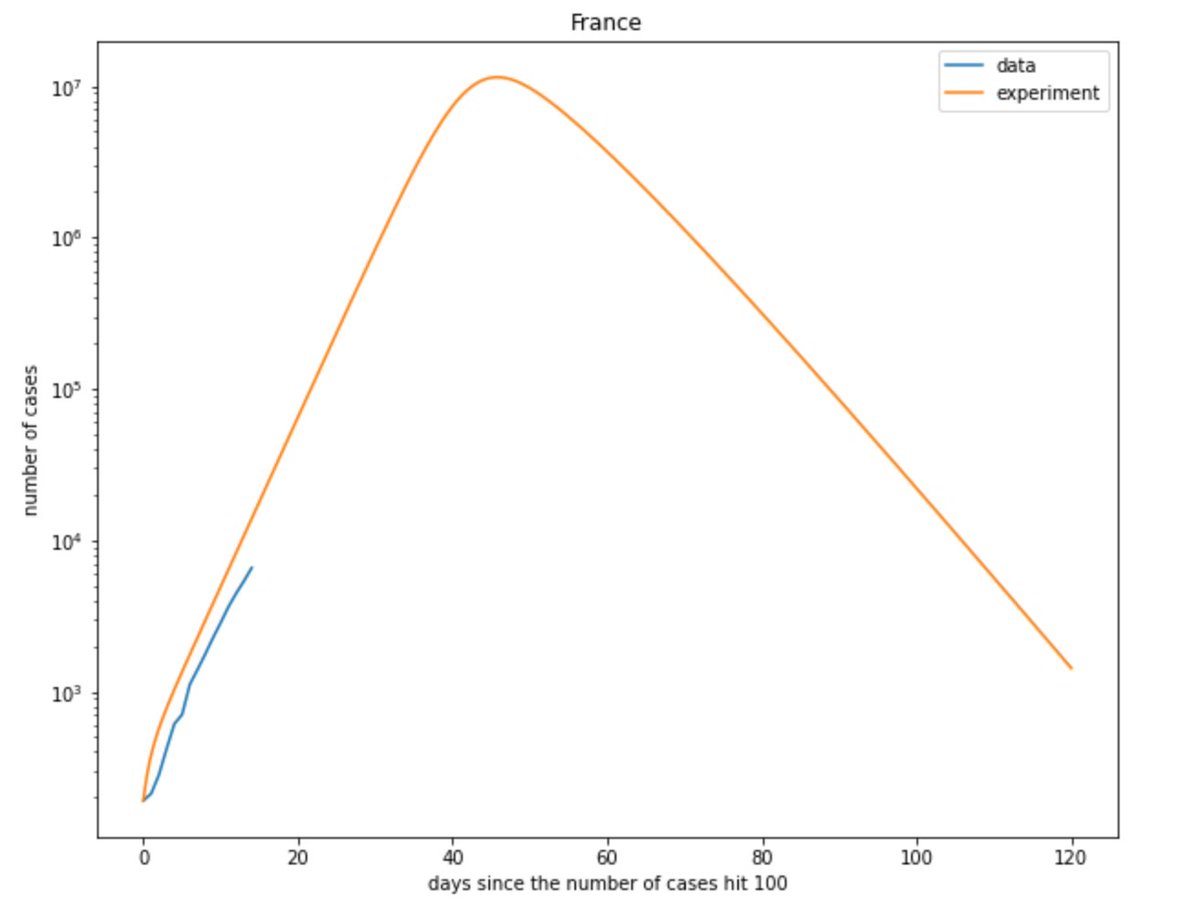
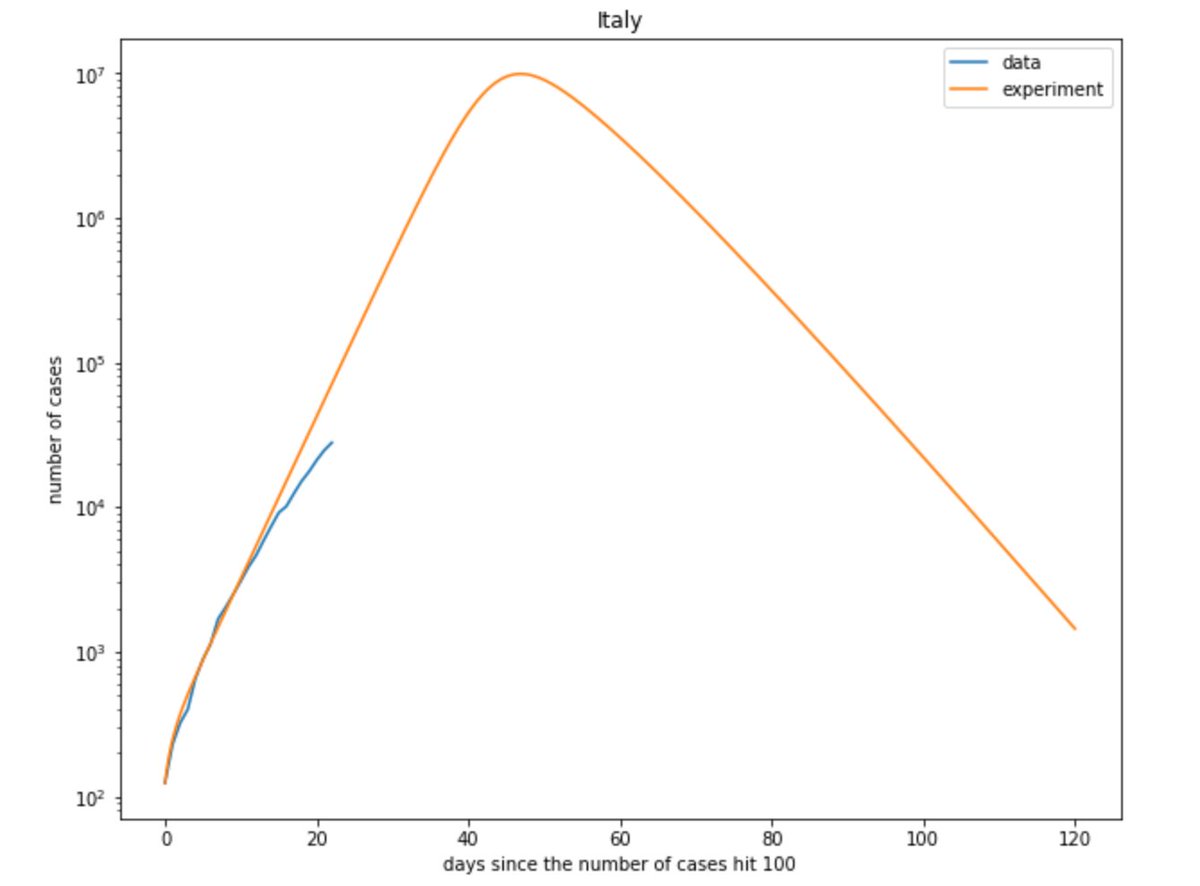
Perso, cette simulation me terrifie : on constate que le nombre d'infecté dépasse les 10 millions... soit 15% de la population !😭
Bon mais les gouvernements français et italiens ont pris des mesures de quarantine (efficaces en Chine) : auront-elles un effet ? Utilisons notre modèle pour ça \o/
Je suppose ici que les mesures de quarantaine divise par 5 le nombre de contacts moyens par adulte. Voilà les nouvelles simulations dans ce cas :


C'est moins bon niveau prédictions mais plus rassurant. Donc comme dit plus haut #RestezChezVousBordel !!!
Et si vous voulez jouer avec mon code, il est disponible ici, n'hésitez pas à le partager !
gitlab.com/thoma.rey/seir…
Et si vous voulez jouer avec mon code, il est disponible ici, n'hésitez pas à le partager !
gitlab.com/thoma.rey/seir…
En fait 35 millions, soit 50% de la population. Il y avait un autre problème dans le modèle ^^

Update avec un modèle un peu plus précis !