The cost savings come from (1) a new upfront #chemistry and (2) super-resolution optics. We think @illumina will use real-world customer data on the NextSeq 2000 to optimize 1 and 2, then possibly upgrade the #NovaSeq line.
illumina.com/systems/sequen…
illumina.com/systems/sequen…
I'm going to briefly (!) illustrate how #sequencing (*by synthesis*) works, walk through a farming analogy, then dive into some technical details. (Sources at the end)
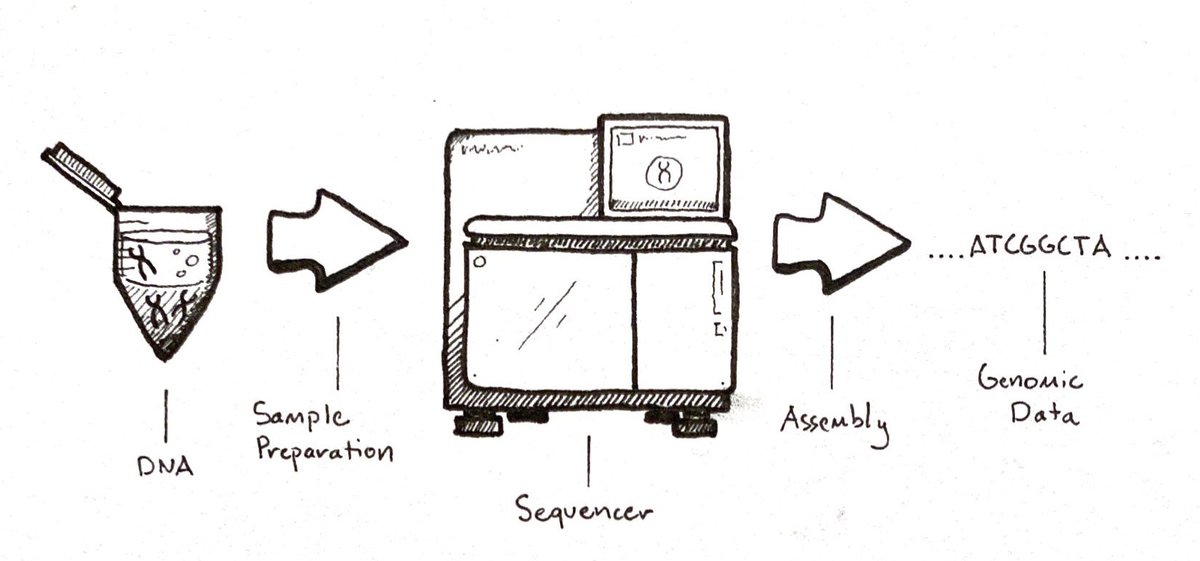
Below is a general overview of a whole genome sequencing workflow (sample in, data out).
Below is a general overview of a whole genome sequencing workflow (sample in, data out).
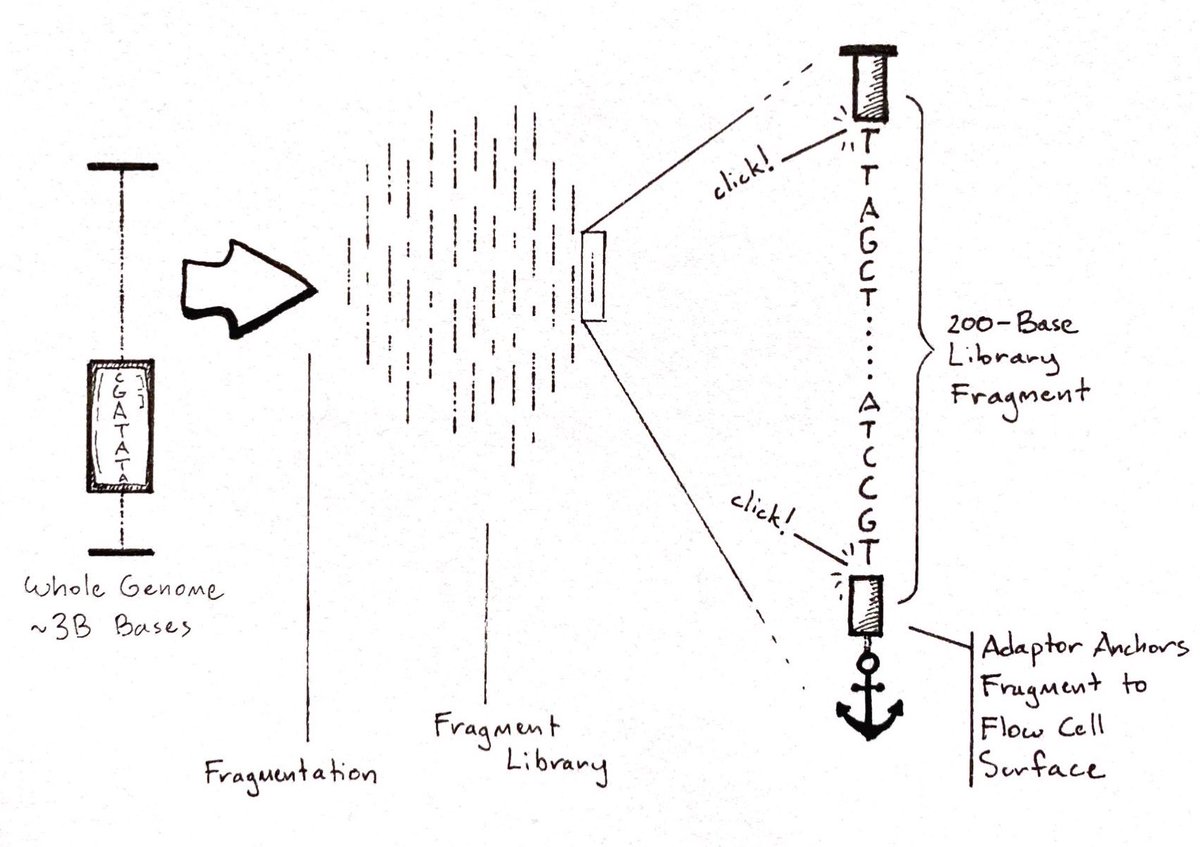
First, let's zoom in on sample prep. #DNA is fragmented into millions of small pieces, each 100-200 letters long. We read DNA in fragments to take advantage of parallel #computation = more efficient.
Later, algorithms reassemble the pieces like a massive jigsaw puzzle.
Later, algorithms reassemble the pieces like a massive jigsaw puzzle.
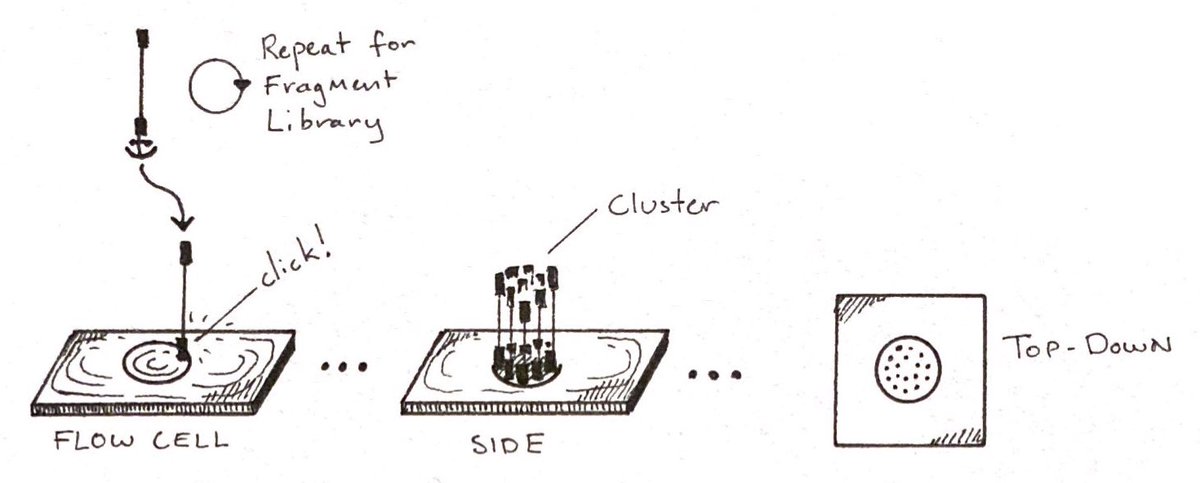
Next, we attach end-caps (adaptors) to protect the fragments and anchor them to the surface of a flow cell, a wafer-thin that holds the fragments in place so the #sequencer can read them all.
Fragments organize themselves together in uniform clusters, which makes reading easier.
Fragments organize themselves together in uniform clusters, which makes reading easier.
Finally, we add #fluorescent labels to the clusters - these are tiny molecules that flash upwards so the camera knows what base is in the fragment. This process is repeated down the entire length of the fragments.
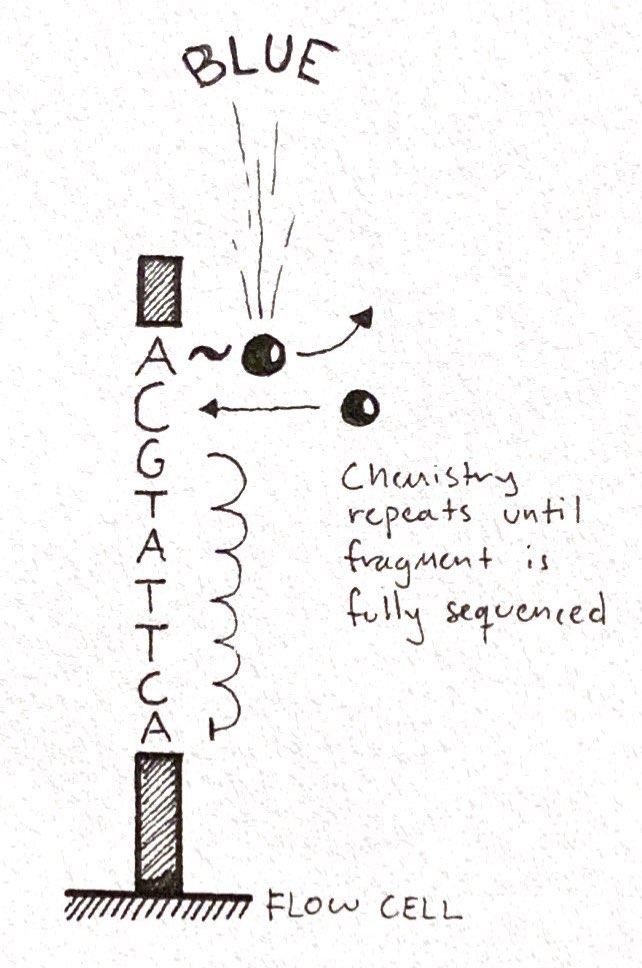
Many @illumina machines use a 2-color heuristic (below, a box w/ no color = dark, meaning no label binds). Algorithms de-convolute these signals, the end resulting equaling an assembled genome (....ATGCATGCA...).
Now, let's get into the specific of the NextSeq 2000...
Now, let's get into the specific of the NextSeq 2000...
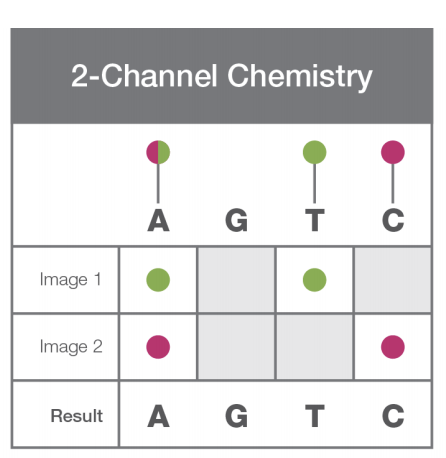
Conceptually:
Tighter clustering of molecules on a flow cell = more base reads in an image/run = amount of #reagents (chemicals) required is smaller = Cheaper!
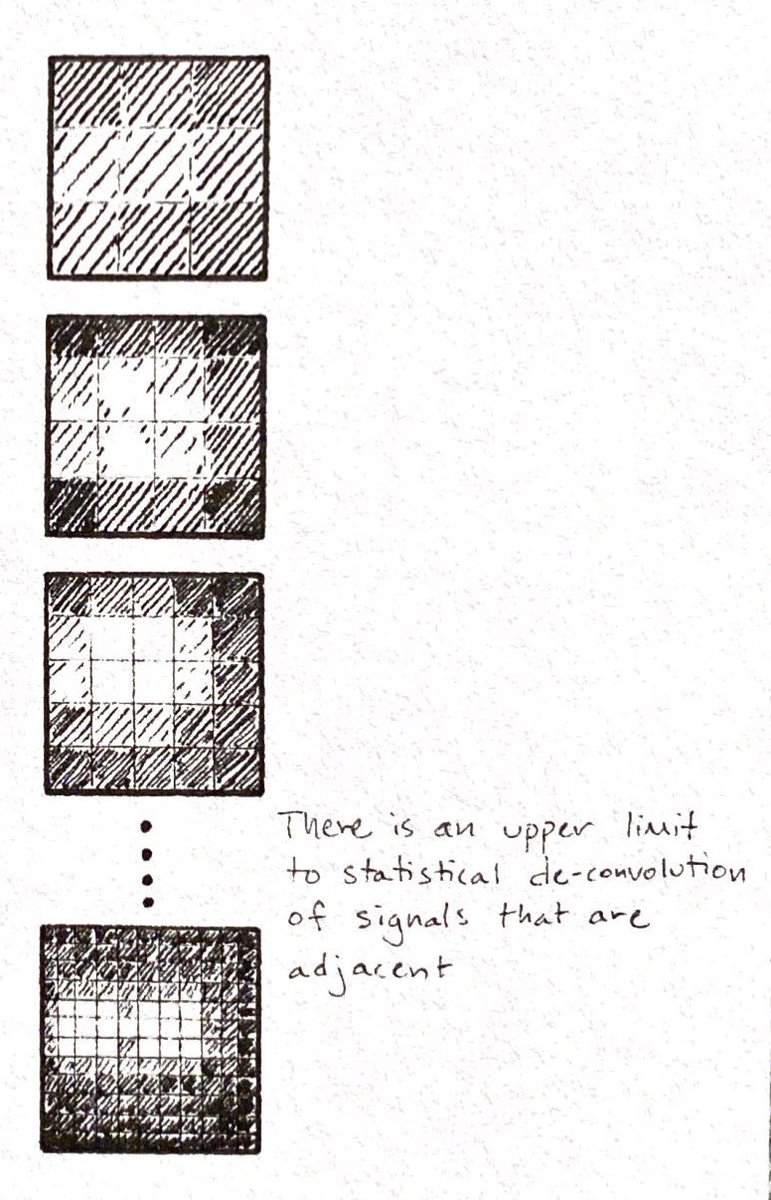
There's a limit to how tightly you can pack fragments in a cluster.
This is what super-res/new chemistry overcame...
Tighter clustering of molecules on a flow cell = more base reads in an image/run = amount of #reagents (chemicals) required is smaller = Cheaper!
There's a limit to how tightly you can pack fragments in a cluster.
This is what super-res/new chemistry overcame...
Imagine you're a farmer, tasked w/ planting trees on a 10 km2 plot of land.
Throwing seeds randomly out on the plot isn't efficient, this is like randomly clustering molecules on a flow cell.
So, patterning clusters neatly is then similar to having a mech. bedder.
Throwing seeds randomly out on the plot isn't efficient, this is like randomly clustering molecules on a flow cell.
So, patterning clusters neatly is then similar to having a mech. bedder.



You want to make efficient use of resources (nutrients ~ reagents). You decide to bed trees as close together as possible, but you run into a physical constraint.
At some density, the trees over-compete for nutrients and wither away.
At some density, the trees over-compete for nutrients and wither away.

Similarly, for sequencing, a cluster that is too dense means the individual light signals can't be resolved, this confuses the sequencer and it can't read bases accurately.
This distance is called the diffraction limit of light (Abbe's Limit), and is on the order of 250 nm.
This distance is called the diffraction limit of light (Abbe's Limit), and is on the order of 250 nm.


Blurry raw images have a limit to how much they can be inferenced.
The #NextSeq 2000 is capable of reading bases that are spaced 20nm apart, yielding super-resolution (breaking Abbe's limit). This doesn't mean a physical law was violated.
It means chemical/optical cleverness.
The #NextSeq 2000 is capable of reading bases that are spaced 20nm apart, yielding super-resolution (breaking Abbe's limit). This doesn't mean a physical law was violated.
It means chemical/optical cleverness.

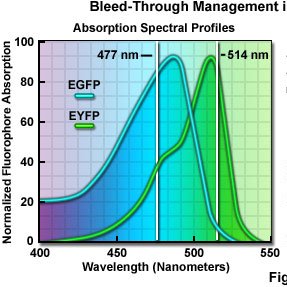
First, the new chem is blue-green, not red-green. While true that blue-green share a sizable #spectral overlap (meaning blue can get confused as green by the machine), the tininess of the blue wavelength more than offsets this issue, enabling tighter molecular clustering.
Next, the colored labels use stochastic (random) photo (light) switching ~ they go bright and dark randomly, even when bound to an A, T, G, or C.
This makes the probability that two adjacent, identical bases will shine simultaneously (and interfere w/ each other) about 0.5%.
This makes the probability that two adjacent, identical bases will shine simultaneously (and interfere w/ each other) about 0.5%.

Loosely:
Probability ~~ function(x-position, y-position, time).
The blue-green/random-flash hack is a clever circumvention of a physical law imposed by the wave nature of light.
It enables 30% closer clustering and a significant reduction in reagents.
Probability ~~ function(x-position, y-position, time).
The blue-green/random-flash hack is a clever circumvention of a physical law imposed by the wave nature of light.
It enables 30% closer clustering and a significant reduction in reagents.
In Summary:
A clever, randomized blue-green chemistry and a high-resolution optical array enable DNA bases (that are closer together than the diffraction limit of light) to be spatially resolved, resulting in fewer necessary reagents in sample prep and a 2X reduction in OpEx.
A clever, randomized blue-green chemistry and a high-resolution optical array enable DNA bases (that are closer together than the diffraction limit of light) to be spatially resolved, resulting in fewer necessary reagents in sample prep and a 2X reduction in OpEx.
DISCLAIMER:
This is not a recommendation to buy, sell, or hold any security. The intent is for educational purposes only and is based solely on publicly available information sourced below.
This is not a recommendation to buy, sell, or hold any security. The intent is for educational purposes only and is based solely on publicly available information sourced below.
Sources:
ILMN Patent:
patentimages.storage.googleapis.com/38/1d/51/9ba7d…
Channel Chemistry:
illumina.com/science/techno…
ILMN Slide Deck:
seekingalpha.com/article/431673…
Diffraction Limit:
microscopyu.com/techniques/sup…
Resolution Interference:
microscopyu.com/microscopy-bas…
Stochastic Photo-Switching:
microscopyu.com/techniques/sup…
ILMN Patent:
patentimages.storage.googleapis.com/38/1d/51/9ba7d…
Channel Chemistry:
illumina.com/science/techno…
ILMN Slide Deck:
seekingalpha.com/article/431673…
Diffraction Limit:
microscopyu.com/techniques/sup…
Resolution Interference:
microscopyu.com/microscopy-bas…
Stochastic Photo-Switching:
microscopyu.com/techniques/sup…
Sources (Cont.)
Statistical Deconvolution of Images:
ncbi.nlm.nih.gov/pubmed/22677393
Excitation and Emission Spectra:
micro.magnet.fsu.edu/primer/lightan…
All Drawing My Own!
Statistical Deconvolution of Images:
ncbi.nlm.nih.gov/pubmed/22677393
Excitation and Emission Spectra:
micro.magnet.fsu.edu/primer/lightan…
All Drawing My Own!