
,
52 tweets,
15 min read
Read on Twitter
Last week I spoke about how we build ultra-reliable AWS services. It's my favourite talk that I've given. Everyone I've asked has told me that they learned something new and interesting 😃 Here I'm going to tweet some highlights to tempt you to watch ...
Like most systems architects, we divide our services into data planes ... the pieces that do the work customers are most interested in, like a running an instance, serving content, or storing bits durably ... and control planes, which manage everything behind the scenes.
Control Planes are all about taking intent and translate it into real world action in the universe. Just like your TV remote. You tell it what you want, and it's job is to make that happen. But it's harder than it seems! 

Have you ever used a universal remote control, and had it turn your TV on, but not your audio system? Super common problem! There's two things going on: one is that there's a network partition ... your remote can't reach everything, ok fine, so you move it around and press again.

But more deeply, the real problem is that the control has no idea whether it achieved success or not. It has no feedback mechanism! This is the most common design problem for control planes. A system like that can never be stable!
I see this all the time in customer designs. For example: users change settings, but sometimes they don't take, because the update doesn't make it to all the servers. Often they end up with support processes to push everything again, on demand, or tell users to try reseting.
Systems like this aren't just annoying, they fail catastrophically under stress! So we have approaches and patterns that help us build more high quality systems. I'm going to share ten of these patterns, and they are awesome, but also they aren't magic.
The most important thing I know about building anything high quality is that there is no magic quality sprinkle dust. Instead it comes about as a result of good habits. Paying lots of attention to detail, always testing and checking things. That's where it really comes from.

Before building great systems, you need to build a great team. Strive for fearlessness, That means a no blame, no shame, awesome positive atmosphere ... and then translate that into action and calculated risk taking ... the safety to try new things and new ideas.

But DON'T risk taking with security, durability, or availability. Those are core values, and top priorities that need to be inviolable. Take risks with business ideas and features, and product names, and have some fun!

With that context, let's build some stable and reliable control systems! What do we use them for? 4 common reasons: 1/ lifecycling resources (launching, scaling, etc) 2/ deploying system config 3/ deploying software 4/ deploying user settings.

At Amazon, we encourage merging 2 and 3. Deploying systems config, like global feature flags, *IS* deploying software. So where possible, we use the same system for both. We have awesome awesome deployment safety systems. One-boxing, staggering, rollback, etc. So use it for both!

For building control systems, it turns out there's a whole branch of rigorous engineering called control theory. There's a lot of math, and it is awesome, well worth knowing, but also you don't need all of that to get most of the benefit. Here is what is worth knowing ...

Every stable control system needs 3 things: a measurement process, a controller, and an actuator. Basically something to see how the world is, something to figure out how the world needs to change, and something that makes that change happen.

That simple mental model is very very important. Most control systems built by CS people *don't* have a measurement element. Like the remote control we've already seen! These systems propagate errors they can't correct. BAD BAD.
So always start with the idea of a measurer; poll every server to know what state it is in, check if the user settings get there, etc ... and build the system as something that corrects any errors it sees, not just a system that just blindly shouts instructions.
O.k. that's 80% of control theory right there for you. The next 10% is that controllers are very sensitive to lag. Imagine a furnace that heated your boiler based on the temperature it was an hour ago? It'd be very unstable!

Imagine scaling up based on the systems load from 2 hours ago? You might not even need those machines any more, peak may have passed! So systems need to be fast. Low lag is critical. O.k. now we know 90% of control theory,
If you want to get the next 5%, 9% ... 10% , and please do, then focus on learning what "PID" means. I'm just going to say this to tempt you: if you can learn to recognise the P.I.D. components of real-world control systems, it is a design review super-power.

Like in seconds you can spot that a system can't possibly be stable. Buy this book ... amazon.com/Designing-Dist… it's very approachable and takes a pattern based approach.

Since it is so accessible, I'm going to borrow the pattern approach and give 10 patterns we use at Amazon. I've chosen patterns that I hope will be interesting, new, and short enough to synopsise. We have way more!

O.k. pattern 1: CHECKSUM ALL THE THINGS. Because this: status.aws.amazon.com/s3-20080720.ht… Never underestimate the ability of bit-rot to set in. S3 had an event in 2008 due to a single corrupt bit!!
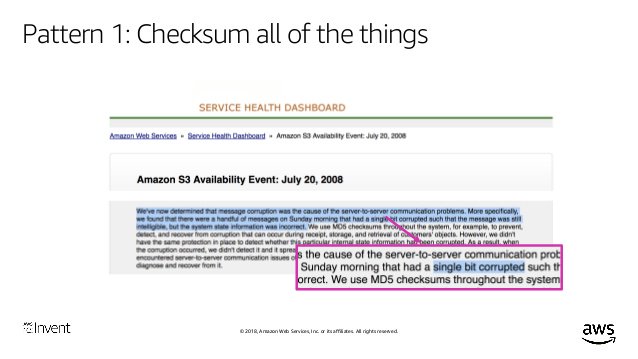
To this day, we still ask teams if they are checksumming everything. Another example of how corruption can slip in is ... YAML. Because YAML is truncatable, configs can fail back to implicit defaults due to partial transfers, full disks, etc. *sigh* CHECKSUM ALL THE THINGS.

Pattern 2: control planes need strong cryptographic authentication! They are important security systems, make sure that they are protected from malicious data. It's ALSO useful to make sure that test stacks don't talk to prod and that operators aren't manually poking things.

Pattern 3: reduce blast radius. Do your best, write great code, do great code reviews, test everything, twice, more. But still have some humility and assume things will fail. So reduce the scope of impact, have circuit breakers and so on.

Watch @PeterVosshall's talk to go much deeper on this:
Pattern 4: Asynchronous Coupling! If system A calls system B synchronously, which means that B has to succeed to A to make any progress, then they are basically one system. There is no real insulation or meaningful separation.

Worse still: if A calls B which calls C and so on, and they have retries built-in, things can get really bad really quickly when there are problems! Just 3 layers deep with 3 retries per layer, and you have 27x application factor if the deepest service fails. Oh wow is that bad.
Asynchronous systems are more forgiving: queues and workflows and step functions and so on are all examples. They tend to try consistently and they can make partial progress when dependencies fail. Of course don't let queue grow infinitely either, have some limits.
All of AWS's multi-region offerings, like S3 cross-region replication, or DynamoDB global tables, are asynchronously coupled. That means that if there is a problem in one region, that the other regions don't just stall waiting for it. Very powerful and important!
Pattern 5: use closed feedback loops! Always Be Checking. Never fire and forget. So important that I repeat this a lot. Repeating good advice over and over is actually a good habit.

Pattern 6: should we push data or pull data from the control plane to the data plane? WRONG QUESTION! I mean we can get into eventing systems and edge triggering, but let's not. What really matters 99% of the time is the relative size of fleets ...

The way to think about it is this: don't have large fleets connect to small fleets. They will overwhelm the small fleet with a thundering herd during cold starts or stress events! Optimize connection direction for that.
Related is pattern 7: Avoid cold start caching problems! If you end up with a caching layer in your system, be very very careful. Can it cope if the origin goes down for an extended duration? When the TTLs expire, will the system stall?

Try to build caches that will serve stale entries, and caches that self-warm or prime their cache before accepting requests, pre-fetching is nice too. Wherever you see caches, see danger, and go super deep on whether they will safely recover from blips.
If you have to throttle things to safely recover and shorten the duration of events, do! have a throttling system at hand. But don't kid yourself either: throttling a customer is also an outage. Think instead how throttling can be used to prioritise smartly ...

Example: ELB is a fault-tolerant AZ-redundant system. We can lose an AZ at any time and ELB is scaled for capacity, it'll be fine. We can deliberately throttle ELBs recovery in a zone after a power event to give our paying customers priority. Works great! Good use of throttling.
Pattern 9: I couldn't say it at the time, but basically use a system like QLDB (aws.amazon.com/qldb/) for your control plane data flow if you can! If you have an immutable append only ledger for your data flow then ...
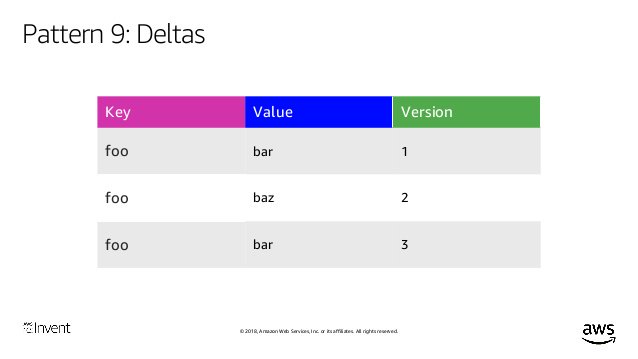
... you can compute and merge deltas easily minimising data volume, and you get item history, so you can implement point-in-time-recovery and rollback! You can also optimise-out no-op changes. We use this pattern in Route 53, EC2, bunch of places.
O.k. I left the most important thoughts and pattern for last. You have filter every element of your design through the lens of "How many modes of operation do I have". For stability, that needs to be minimal.

Avoid emergency modes that are different, or anything that can alter what the system is doing suddenly. Think about your system in terms of state space, or code branches. How many can you get rid of?
Branches and state spaces are evil, because they grow exponentially, past the point you can test or predict behaviour, they become emergent instead. A simple example here is relational databases.

I'm not knocking offerings like RDS or Aurora, relational DBs are great for versatile business queries, but they are terrible for control planes. We essentially ban them for that purpose at AWS. Why?
RDBMSs have built-in fancy Query Plan Optimizers that can suddenly change what indices are being used, or how tables are being scanned. That can have a disastrous effect on performance or behaviour. Another is that they are very accessible and tempting ...
... an operator, product manager, business analyst might all think it's safe to run a one-time read-only query, but a simple SQL typo can choke up the system! Bad bad. So what's the fix?
Use NoSQL and do things the "dumb" way every time. Because the perf characteristics are much more obvious to the programmer and designer, now you can just do a full join, or a full table scan every time for every query. Much more stable!
I've tweet stormed about this before, but now we're getting into the "constant work" pattern. The most stable control systems do the same work all of the time, with no change that is dependent on the data, or even the volume of change.

Suppose you need to get some config to your data plane. What if the data plane just fetched the config from S3 every 10 seconds, whether it changed or not? And reloaded the configuration, every time, whether it changed or not?
This simple, simple, design is rarely seen in the wild, but I don't know why. It's very very reliable ... incredibly resilient and will recover from all sorts of issues. It's not even expensive! We're talking hundreds of dollars per year. Not even a few days of SDE time.

That's the pattern we use for our most critical systems. The network health check statuses that allow AWS to instantly handle an Availability Zone power issue? Those are always flowing, all the time, 0 or 1, whether they change or not.
We have these and so many more patterns, and ... we're been building them into API Gateway and Lambda behind the scenes too! So consider building your control planes on those!

Thank your for listening to my talk! Always always feel free to AMA. This is the last tweet in the thread for now, and I won't even promote my Soundcloud!











