,
24 tweets,
8 min read
Read on Twitter
NEW: Since March, Facebook has been blocking the release of internal communications showing what it knew about Cambridge Analytica & when.
Today it published them – and they show employees were worried about CA three months before FB originally claimed.
telegraph.co.uk/technology/201…
Today it published them – and they show employees were worried about CA three months before FB originally claimed.
telegraph.co.uk/technology/201…
The document does not clearly contradict Mark Zuckerberg's 2018 testimony to Congress. They actually confirm FB's account of events to some extent.
But it also shows that FB has been, let's say, economical about what /else/ it knew outside that narrative
But it also shows that FB has been, let's say, economical about what /else/ it knew outside that narrative
[NOTE: I deleted my initial first tweet, which referred to these communications as emails, because on close inspection, they may be posts on one of FB's internal networks. It's unclear, but I don't want to misstate anything!]
Here's the timeline:
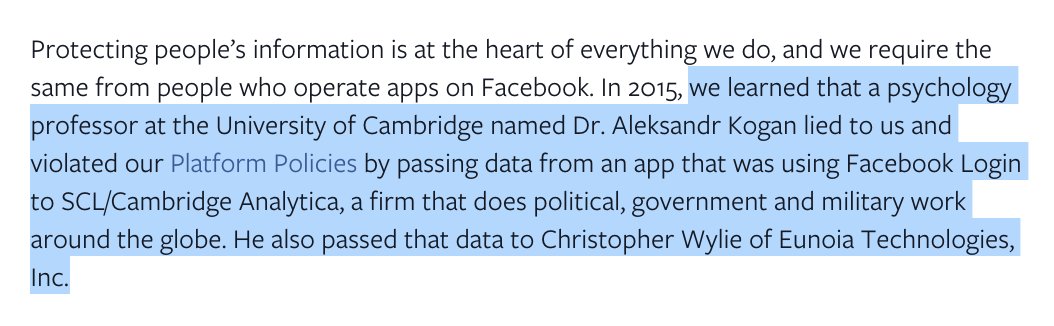
In the spring of 2018, the Observer revealed that Cambridge Analytica had improperly harvested data from around 50m Facebook profiles.
The kicker? Facebook had known since 2015, told nobody, & taken "only lmited steps" to fix things theguardian.com/news/2018/mar/…
In the spring of 2018, the Observer revealed that Cambridge Analytica had improperly harvested data from around 50m Facebook profiles.
The kicker? Facebook had known since 2015, told nobody, & taken "only lmited steps" to fix things theguardian.com/news/2018/mar/…
As you may recall, it was a big fuss. On March 21, after a week of silence, Mark Zuckerberg wrote a Facebook page explaining the timeline of events.
FB, he said, had only learned about Cambridge Analytica's bad behaviour from the Guardian in 2015.
FB, he said, had only learned about Cambridge Analytica's bad behaviour from the Guardian in 2015.

That is a reference to this story on December 11, 2015, which reported:
"Ted Cruz’s presidential campaign is using psychological data based on research spanning tens of millions of Facebook users, harvested largely without their permission."
theguardian.com/us-news/2015/d…
"Ted Cruz’s presidential campaign is using psychological data based on research spanning tens of millions of Facebook users, harvested largely without their permission."
theguardian.com/us-news/2015/d…
But wait. Let's rewind.
The internal documents do indeed show that FB employees were worried by the Guardian's story, which sparked a flurry of discussion and crisis management.
Yet it also shows that those employees had already been investigating CA... since September 22, 2015
The internal documents do indeed show that FB employees were worried by the Guardian's story, which sparked a flurry of discussion and crisis management.
Yet it also shows that those employees had already been investigating CA... since September 22, 2015
This is the post that started the discussion thread. It refers to a number of companies rumoured to be "scraping" user informtion from FB.
The biggest, it says, IS CA, "a sketchy (to say the least) data modelling company that has penetrated our market deeply."
The biggest, it says, IS CA, "a sketchy (to say the least) data modelling company that has penetrated our market deeply."

Employees think CA and other firms may have broken FB's rules against selling or transferring user data to others. But the discussion is bogged down in technical difficulties, and moves on to other companies (which, incidentally, FB has never talked about before to my knowledge)
And then, in December, the Guardian story comes out.
An employee writes: "Can you expedite the review of Cambridge Analytica...? Unfortunately, this firm is now a PR issue."
The messages after that poin tare a fascinating window into FB responding to a crisis.
An employee writes: "Can you expedite the review of Cambridge Analytica...? Unfortunately, this firm is now a PR issue."
The messages after that poin tare a fascinating window into FB responding to a crisis.

These messages refer to Aleksandr Kogan, the Cambridge University psychologist whose firm, GSR, actually collected the data which it then trasnferred to CA.
As FB tries to figure out just what Kogan did, one employee says they actually studied under Kogan at Cambridge!
As FB tries to figure out just what Kogan did, one employee says they actually studied under Kogan at Cambridge!

Tantalisingly, this thread refers to ANOTHER thread, which we haven't heard of before, suggestively titled: "Wait, What".
The Wait, What thread apparently discusses Facebook having worked with Kogan in the past.
Wait, what?
The Wait, What thread apparently discusses Facebook having worked with Kogan in the past.
Wait, what?

Now, here's the thing. Facebook argues that the issue raised on September 22 is /completely separate/ from the Graun's Dec 11 story.
"This document proves the issues are separate; conflating them has the potential to mislead people," said an exec today.
newsroom.fb.com/news/2019/08/d…
"This document proves the issues are separate; conflating them has the potential to mislead people," said an exec today.
newsroom.fb.com/news/2019/08/d…
According to FB, the big deal was not that Kogan collected that data (which at the time was actually allowed by FB!). It was that Kogan had transferred the data to CA.
So the Sep post was about data scraped from users' /pubic/ profiles. The Dec story was about Kogan. Separate!
So the Sep post was about data scraped from users' /pubic/ profiles. The Dec story was about Kogan. Separate!

The new document does basically confirm this story. FB employees appear very worried by the Guardian story and it's clear it's a new development for them. It transforms the pace and tone of the discussion.
But was this really "separate" from the prior issue? I have some doubts.
But was this really "separate" from the prior issue? I have some doubts.
First, if Kogan was a totally separate issue, why does an FB employee ask to "expedite" an existing review into CA, not start a new or different one?
Notably, FB has said that its engineers found no evidence of scraping by CA – but not that they /finished/ their probe.
Notably, FB has said that its engineers found no evidence of scraping by CA – but not that they /finished/ their probe.
Second, if the early thread is all about data scraping, how come the /third post/ cites Facebook's rules against "selling, licencing or purchasing any data obtained from us" and "transferring any data that you receive... to any ad network, data broker" or other ad service.

Third, the thread actually goes way beyond CA. Employees mention numerous firms engaging in suspicious activity, to the point that some clients are really worried but don't feel they can say no because all their rivals are doing the same kind of data-mining from FB.
I've asked FB about all of this. I'll let you know if I hear back.
In the meantime, we now enough to say: yes, this document confirms the bare bones of the story that FB has told until now. But it raises a lot of questions about what exactly that story might be missing.
In the meantime, we now enough to say: yes, this document confirms the bare bones of the story that FB has told until now. But it raises a lot of questions about what exactly that story might be missing.
We can also say that even if FB was not aware of the specific issue that ended up creating the Cambridge Analytica scandal – and these documents are strong evidence that it was not – it /was/ aware of a whole industry of "sketchy" data-mining practices, CA being part of it.
This thread by @juliacarriew gives a good idea of why this is a problem.
Even if the issue raised in Sep 15 /is/ totally separate to the one which killed CA, isn't it kind of weird that FB never mentioned it when legislators asked what it knew?
Even if the issue raised in Sep 15 /is/ totally separate to the one which killed CA, isn't it kind of weird that FB never mentioned it when legislators asked what it knew?
"Your honour, we only became aware that Carmen Sandiego had stolen all those famous artworks from our museum in the summer of 1985.
"...okay, so I did hear that she had also tried to sell us forged paintings in 1984. But these are totally separate issues!"
"...okay, so I did hear that she had also tried to sell us forged paintings in 1984. But these are totally separate issues!"
Anyway, this is not a scandal on par with CA itself. But it does raise many questions, and give us a portal into a time when shady data-miners roamed freely across the savannah of FB's platform.
(Are you a huge nerd? You can read the full document here!) newsroom.fb.com/news/2019/08/d…
(Are you a huge nerd? You can read the full document here!) newsroom.fb.com/news/2019/08/d…
PS: A very similar situation to the one which allowed Cambridge Analytica to happen has even now been unfolding on Instagram, where @robaeprice found multiple companies blatantly scraping data from the service agains tits rules.