,
32 tweets,
23 min read
Read on Twitter
Our fabulous new paper is out in BMJ! We have used VAST datasets to explore DIFFUSION OF INNOVATION in the NHS on an UNPRECEDENTED scale, using a data science approach from another field, adapted with vast effort into a fun new library for medical research bmj.com/content/367/bm…
Let me tell you briefly why this paper is awesome, in terms of (1) the specific findings; (2) how this new data science method can be used by us and others in future work; then (3) the power of modern OPEN approaches, sharing code and (gasp) libraries...
So, first up, the specific findings. How long does it take for medical practice to change, when the evidence, cost, or guidelines change? Remember, medicine tells a story about itself: that we are a data driven profession…
But in reality as a profession, as an ecosystem, medicine fails on its ambition to be data-driven, as I set out in this 20 minute plenary at this year’s @RCGP slides here: drive.google.com/file/d/1vvrAz1… video
@rcgp Now, there is an exciting history to research on “diffusion of innovation”, because some of the earliest social science work was done in healthcare: for example, in the 1950s, looking at how long it took for each doctor to start using antibiotics.
@rcgp (You can read this fascinating history in the first three references from our paper) bmj.com/content/bmj/36…
@rcgp But all this work on diffusion of innovation was done slowly, identifying who has or hasn’t changed behaviour BY HAND. And most modern research on diffusion isn’t very different: it uses manual “changed or not” measures, or simple crude measures like “time to first use of X”
@rcgp We wanted to do something more. So, working with @FelixPretis (a god of “indicator saturation”) we adapted and developed methods to generate richer data on changes in clinical practice, across millions of treatment choices, and many years of data, in thousands of organisations.
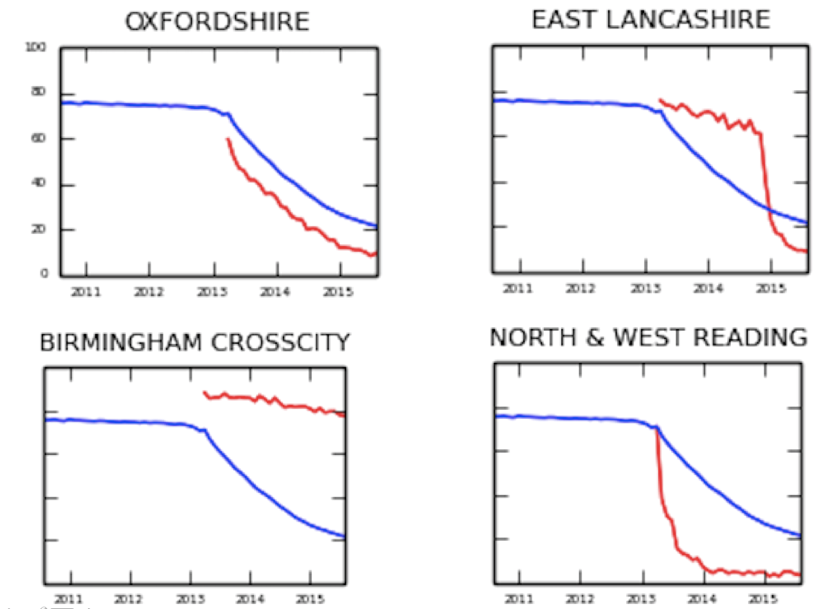
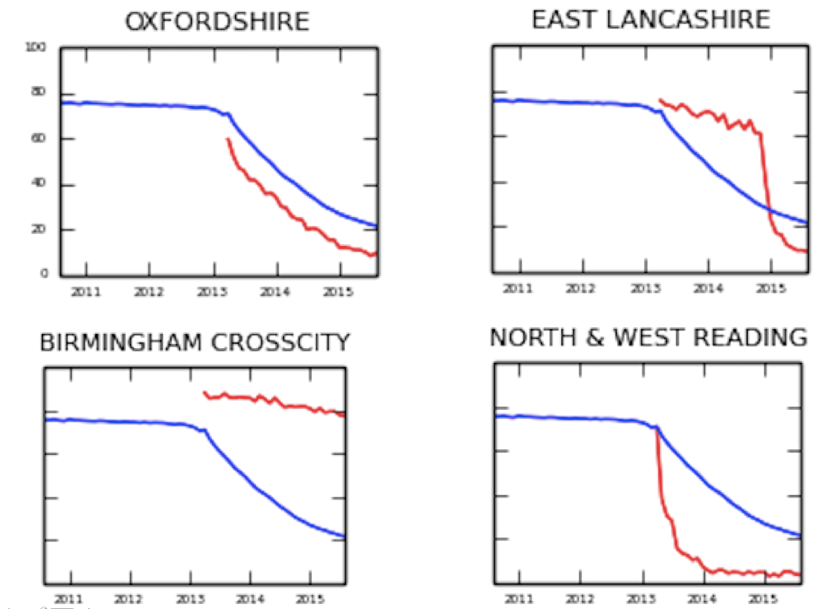
@rcgp @FelixPretis We prove the concept with a couple of examples. For example: in 2013, cerazette went off-patent. From then on, you’d have expected everyone to prescribe generic desogestrel instead. Some did, some didn’t. Take a look at these older graphs for an insight into the issue. 
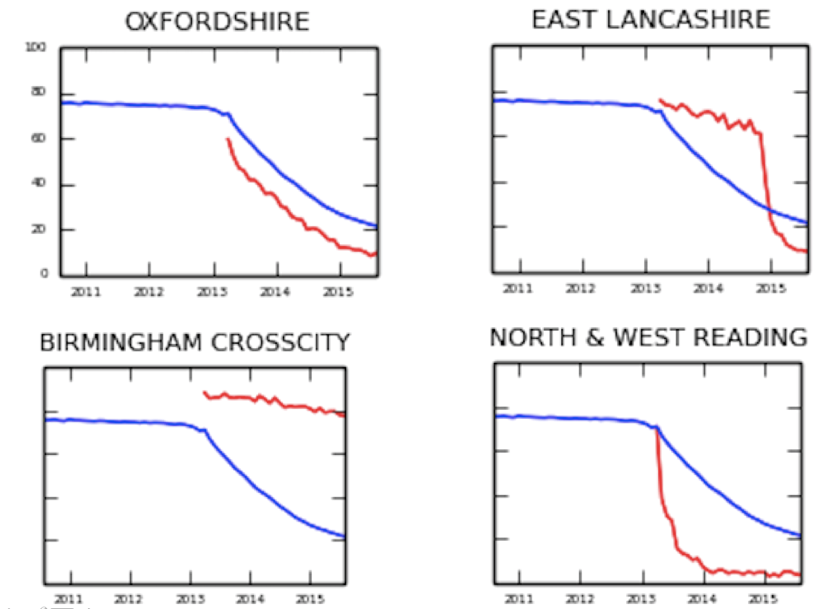
@rcgp @FelixPretis These show the proportion of all desogestrel that was prescribed as branded cerazette. The blue line is the national median. The red lines show each CCG....
@rcgp @FelixPretis Now, in Reading, you can see a sudden sharp downward shock. That’s most likely a medicines optimisation team saying “ok, chop chop everyone, stop wasting NHS money on cerazette, switch to desogestrel unless there’s a good reason not to”.
@rcgp @FelixPretis In Lancashire, you can see the same sudden downward shock, the same coordinated change activity, but it’s… a couple of years later (you can calculate the cost to the NHS of this delay, it’s the area between the two curves!).
@rcgp @FelixPretis In Oxfordshire, you can see the oral tradition of medicine live in action, people gradually finding out, bit by bit. And in Birmingham… they didn’t get the memo. (More current, better/different graphs in the paper and live on our OpenPrescribing.net service)
@rcgp @FelixPretis Now, with your human eyes, attached to your human brain, you can see which line is a sudden drop, and which is a gradual slope; you can see who changes early, and who changes late. But we can’t manually assess 8,000 practices, or do this for every treatment choice imaginable...
@rcgp @FelixPretis So, indicator saturation does this job for us, as you can see in Fig 1 of the paper: it finds the break points, it tells us when there’s a change, and when there is a change, it tells us the slope after that change, so we can see if change is “sudden and coordinated” or not.
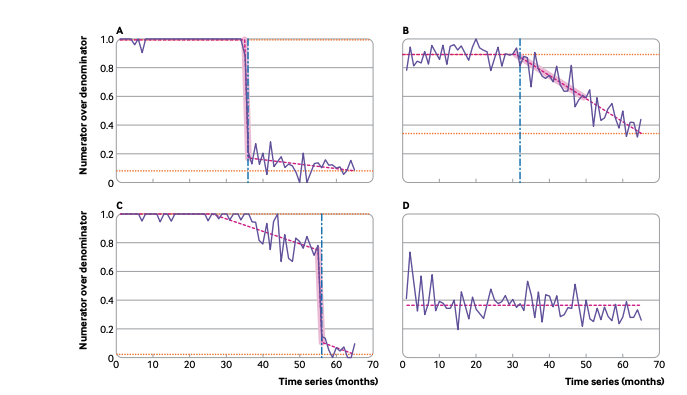
@rcgp @FelixPretis Once you’ve done that, you can do some real cool stuff. You have big numbers. So, in this paper we present descriptive work. For example, you can describe the variation in responsiveness, both when people change, and how coordinated that change is, across the country.
@rcgp @FelixPretis (Sorry, I'm really going on, should I stop?)
@rcgp @FelixPretis We do this for cerazette, and for a change in antibiotics behaviour. But you can also do all kinds of other clever new stuff: “factors associated with changing early or late”; “do people who change early on one thing change early on everything”. We have a ton of papers coming!
@rcgp @FelixPretis But here’s the last crucial thing. We want other people to use this approach. So Felix has packaged up his analytic method in an R package; and we’ve packaged that up in a lovely Python library, so it’s as easy as possible for you all: pypi.org/project/change…
@rcgp @FelixPretis THIS REALLY MATTERS. Why? It’s practical, and political. Some fields, especially the various genetics fields, have been REALLY good at open science: sharing data, methods, and their analytic code, creating a commons of knowledge, and a shared codebase.
@rcgp @FelixPretis But epidemiology has fallen behind. We are trapped with a lot of people doing nothing but 1990s logistic regression papers (“factors associated with bad thing X: a cohort study in dataset Y”).
@rcgp @FelixPretis More importantly, with certain wonderful exceptions, it’s proven REALLY rather hard to get epidemiologists sharing their code in places like GitHub, or even sharing their “codelists” consistently.
@rcgp @FelixPretis Our group is trying to do NHS data analysis more openly. We don’t claim to be perfect, but on GitHub under open licenses we have shared 44,000 lines of code in 34 public repositories, with over 5,000 commits, 850 python files, 4,600 lines of SQL.. github.com/ebmdatalab/
@rcgp @FelixPretis Our “issue trackers” are open to all, with 260 open issues and 745 closed ones, all containing a permanent public record of our technical discussions around barriers and solutions, all discoverable in Google.
@rcgp @FelixPretis (I'm nearly done now).... With every paper we share a Jupyter notebook, containing the code, and the outputs of the code. We talk more here about these open approaches, and why they matter. ebmdatalab.net/openness-and-t…
@rcgp @FelixPretis We think these open technical approaches hugely important. They’re the only way the NHS or funders like @UKRI_News @wellcometrust will get good value on digital health: by creating a commons of knowledge, to reduce duplication, eradicate errors early, and help good ideas thrive..
@rcgp @FelixPretis @UKRI_News @wellcometrust There is some sunny news. The notion of these modern open methods is becoming more popular. However, concerningly, we’ve also seen some current incumbents in this space adopting the *language* of openness, without the *delivery*. We now risk "open" becoming an empty buzzword..
@rcgp @FelixPretis @UKRI_News @wellcometrust (We know from experience that this kind of very technical, open, collaborative, sharing only happens when you work with people who understand open methods, and have a track record of delivering them).
@rcgp @FelixPretis @UKRI_News @wellcometrust On a VERY sunny note, we have funding for a policy thinktank, firmly embedded in our technical group: a mix of technical insights, and policy insights. (We think this is new, and good!). From here, we will start describing and advocating for these open approaches. So stay tuned!
@rcgp @FelixPretis @UKRI_News @wellcometrust We’re also very keen to get some resource to TEACH these modern open approaches, and move health data research forward. So, if you can think of anyone who will fund it, as always, please get in touch. The future is looking good!
@rcgp @FelixPretis @UKRI_News @wellcometrust And here’s the paper, one more time. HUGE, epic, vast applause and glory to the heroic team of @alexjohnwalker @darkgreener @felixpretis, and ALL the mighty people at @ebmdatalab in Oxford. Feedback welcome. And keen to build alliances on OPEN. Onward!!
bmj.com/content/367/bm…
bmj.com/content/367/bm…
@rcgp @FelixPretis @UKRI_News @wellcometrust @alexjohnwalker @darkgreener @EBMDataLab Oh, one last thing. Please do use the open library from our paper to measure diffusion of innovation (etc) yourself. BUT this isn't a test! If you'd prefer to do it with us, or need a hand, then of course feel free to get in touch! We collaborate widely, always open to fun offers