
1.1/n Today I was the keynote at the @BudapestBI machine learning, R, pydata and datavis confererence. I'm summarizing my talk here in a twitter thread. Because of the format (keynote) and audience (all attendees/tracks in a plenary session) this was a... 

1.2/n ... higher-level talk compared to the more technical talks I usually give. I tried to give a few tips, "best practices" for doing machine learning in practice/businesses. I aimed to cover 10 tips (in 45 mins), though of course there are many more tips I could give.

1.3/n Despite the "AI" hype that makes you think everything has been invented in the last 2-3 years, machine learning has been successful in many business domains/applications for 10, 20 and even more years (fraud detection, credit scoring, marketing analytics, manufacturing...)

1.4/n Unfortunately the media portrays this as "AI" and vendors/companies/investors have started renaming their products powered by machine learning or even simpler statistical methods to AI. This image projected is that we can do/we have this [see pic]:

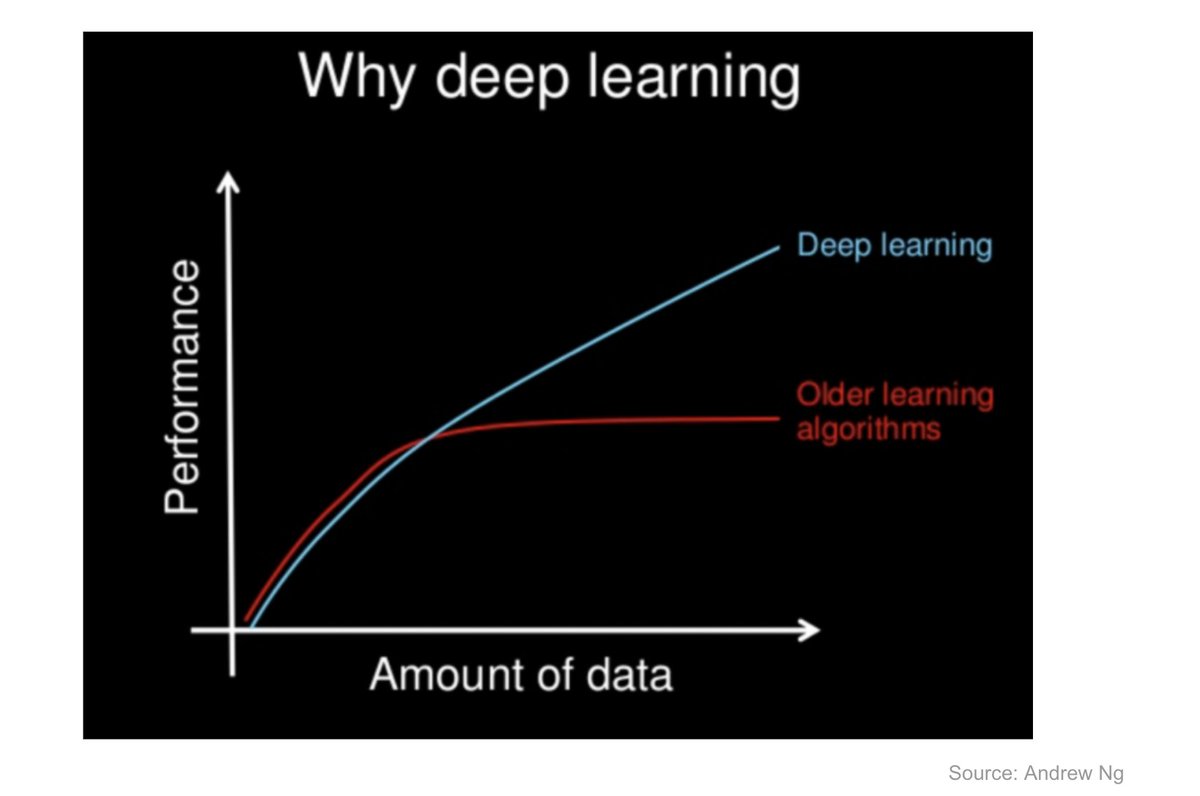
1.5/n When in fact 99% of machine learning projects are more like this [see pic] - that is we have data and we try to predict from some inputs X some output y by fitting a mapping function f, i.e. we are doing "curve fitting" - 99% of machine learning is this: [see pic]

1.6/n We have various algorithms to do this curve fitting/machine learning, some as simple as linear methods, some more complex and flexible being able to fit non-linearities in the data

1.7/n Some people (mostly vendors/investors/media/marketers/so called though-leaders etc.) are hyping even simple linear models as AI.
1.8/n Despite the hype, there are actually still many people who would prefer a more honest term to be used and call it "machine learning" (a term in use for this for many decades, though for simple linear models maybe even that is a bit of a stretch).

1.9/n I had "best practices [...] in 2018" in the original title, though most of these tips are not new, we have been doing the majority of these ML best practices for decades (though some of them are indeed newer).

1.10/n I'll summarize now the 10 "ML best practices" tips I discussed in the talk, though I have a few more tips already. I think I'll spread them in chunks over 2-3 days, I'll do the first tip today.

2.1/n Tip #1: Use the right algorithm (for your problem/your data)

2.2/n Deep learning experts are marketing it as the algorithm that beats all other "traditional" machine learning algorithm (if someone has enough data).
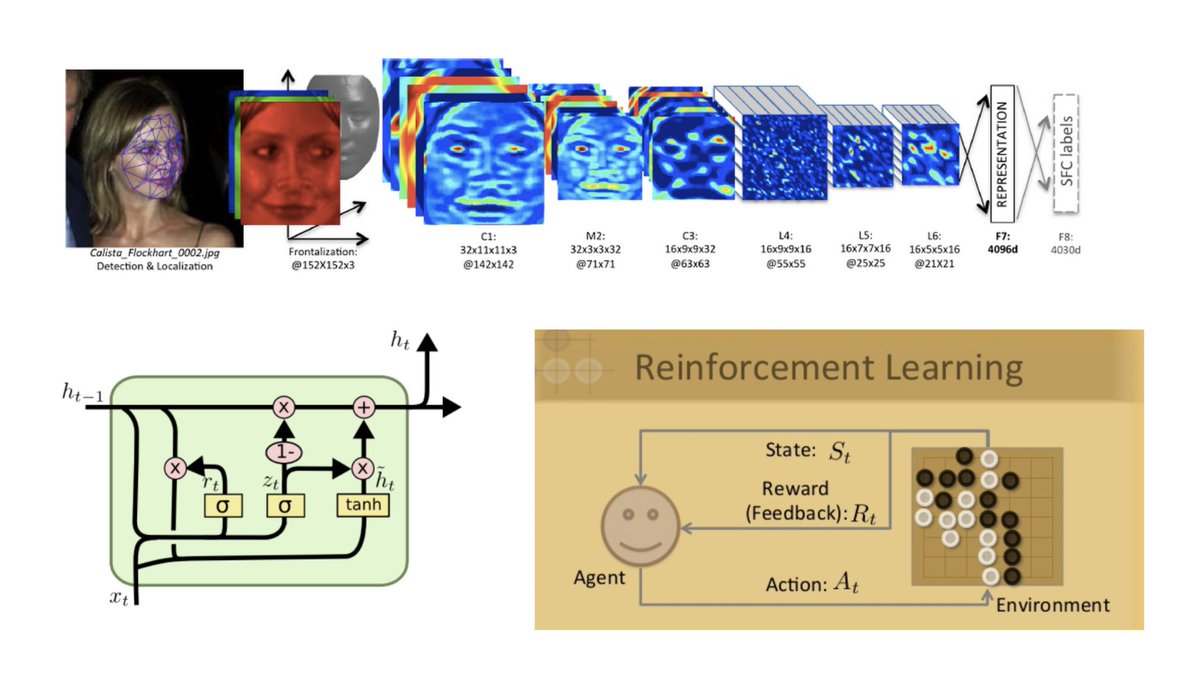
2.3/n No doubt, deep learning has had great success in computer vision, some success in sequence modeling (time series/text), and (combined with reinforcement learning) fantastic results in virtual environments such as playing games.
2.4/n However, in most problems with tabular/structured data (mix of numeric and categorical variables) as most often encountered in business problems, deep learning usually cannot match the predictive accuracy of tree-based ensembles such as random forests or boosting/GBMs.

2.5/n There is evidence for this "conjecture" in Kaggle competitions: >60% of Kaggles (mainly those with tabular/structured data) are won with some combination of boosting/GBMs (and feature engineering and ensembles).

2.6/n So quick recommendation for what algo to use: For tabular/structured data use random forests or GBMs (if you have enough data). For very small data (e.g. 100 records) use linear/logistic regression (most other methods will overfit).
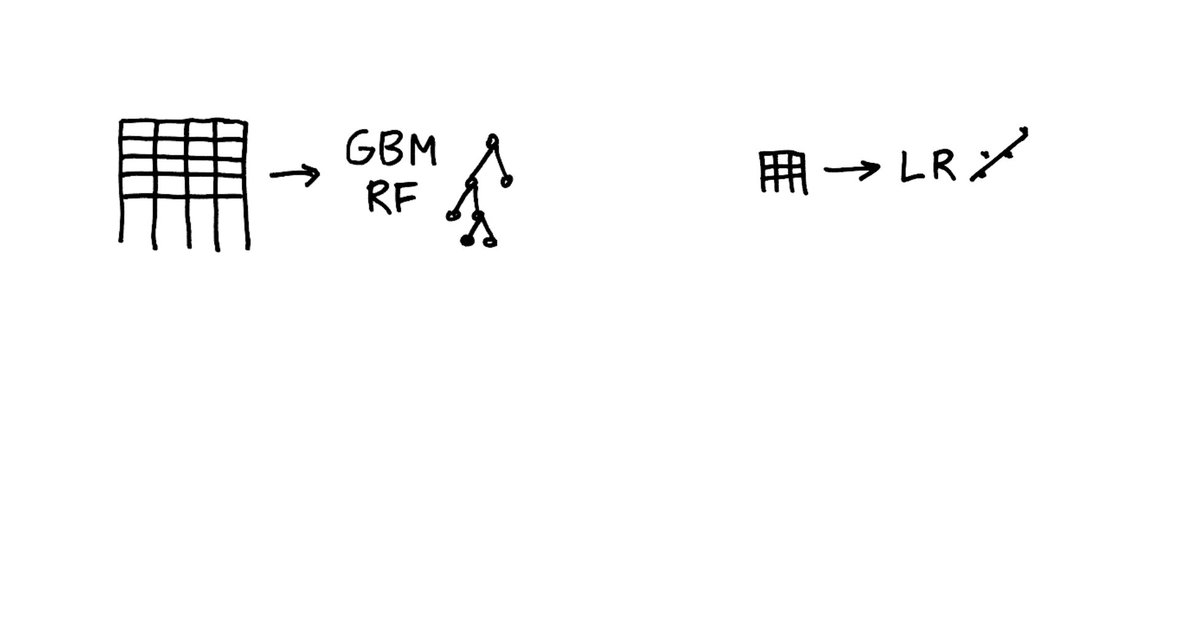
2.7/n ... For big and sparse data (lots of rows and columns) use linear models with strong regularization (L1/L2) fitted with stochastic gradient descent (most others will be computationally infeasible). For images/speech do absolutely use deep learning!!

2.8/n Better recommendations: [1] it depends 😀😎😂 [2] try them all (there are like 4-5 methods for supervised learning that usually win: RF, GBM, NN/DL, LR, SVM) [3] do hyperparameter tuning ...

2.9/n [4] do ensembles of models [5] often feature engineering is more important than the algo you use (in providing larger lift in accuracy) [6] sometimes accuracy is not the primary/only goal, you might need interpretable models etc.

2.10/n Kaggle surveys show that the most widely used ML algo in practice is actually... linear/logistic regression 😛😂 and then simpler methods are more often used than more complex ones

2.11/n If I do an informal twitter poll, I get that (my followers) use most often random forests/GBMs (someone biased sample, also they might have larger data/more experience etc. than the average Kaggler)

2.12/n Already at 21 tweets, I'll continue this thread with more tips on machine learning best practices tomorrow 😎
2.13/n Update: thread continues here:











