,
35 tweets,
13 min read
Read on Twitter
Sábado, sabadete, por lo que hoy toca hilo sobre #privacidad y #protecciondedatos o (des)protección de datos. Tema central de hoy: ¿Por qué estamos actualmente en una situación en la que la privacidad y la falta de transparencia se han convertido en cuestiones legales centrales?
Obviamente, se debe a un rápido desarrollo tecnológico, pero quizás sea útil para nuestra discusión sobre #transparencia, #privacidad y #perfiles.
para cavar un poco más profundo en el por qué, y no en el cómo. ¡Adelante hilo!
para cavar un poco más profundo en el por qué, y no en el cómo. ¡Adelante hilo!
Dos hechos tecnológicos hicieron posible esta enorme transformación: 1) el desarrollo de hardware informático y 2) el desarrollo de un software que permitió que muchos ordenadores funcionaran como uno solo. ¿Qué supusieron estos grandes hitos para las organizaciones y empresas?
Un imprescindible a la hora de entender el #BigData es la Ley de Moore, creada por Gordon Moore, cofundador de Intel. Gordon Moore, en el año 1965 escribió un artículo para la revista "Electronics" en el que explica el crecimiento exponencial en la era del big data.
Gordon Moore anticipó que la complejidad de los circuitos integrados se duplicaría cada año con una reducción de coste conmensurable. Finalmente, la predicción se citó como 18 meses como el período de duplicación de la potencia de cálculo general. eng.auburn.edu/~agrawvd/COURS…
Esto significa que, cada 18 meses (desde 1965), la potencia de los circuitos integrados se duplicaría, y su precio sería la mitad. Pero, ¿cómo podemos entender mejor esta predicción de manera que podamos obtener una imagen mental y así visualizar su significado? Con un cuento...
Ray Kurzweil lo explica en su libro: "The age of spiritual machines: When computers exceed human intelligence" a través de la historia de cuando el inventor del ajedrez en la India presentó el juego al Emperador, y éste quedó totalmente impresionado.
El Emperador le pidió al inventor que le pidiera cualquier recompensa. El inventor pidió arroz para alimentar a su familia y usó el tablero de ajedrez para mostrar la cantidad de arroz que pedía. ¿Cómo hizo para calcular la cantidad de arroz? (Un grano, un dato)
Puso un grano de arroz en el primer cuadrado del tablero de ajedrez, dos en el segundo cuadrado, cuatro en el tercero, ocho en el cuarto cuadrado, y repitió este proceso hasta que el último cuadrado del tablero de ajedrez estuviera lleno de granos de arroz.
En la primera mitad del tablero de ajedrez, el cerebro humano puede imaginar la cantidad de granos de arroz, pero en la última parte del tablero de ajedrez, los números se vuelven demasiado grandes para imaginarlos: billones, trillones, cuatrillones...
Cuando esta acción se repite hasta el último cuadrado del tablero de ajedrez se obtiene más de un quintillón de granos de arroz. Un número que se escapa de nuestra imaginación. Vamos a añadir información a este cuento y ver qué tienen que ver los datos con los granos de arroz.
Para entenderlo, volvamos a la ley de Moore, que como dije antes, fue formulada en 1965 y se pronosticó 18 meses como el tiempo de duplicación de los transistores en uso (o granos de arroz en el tablero de ajedrez) 
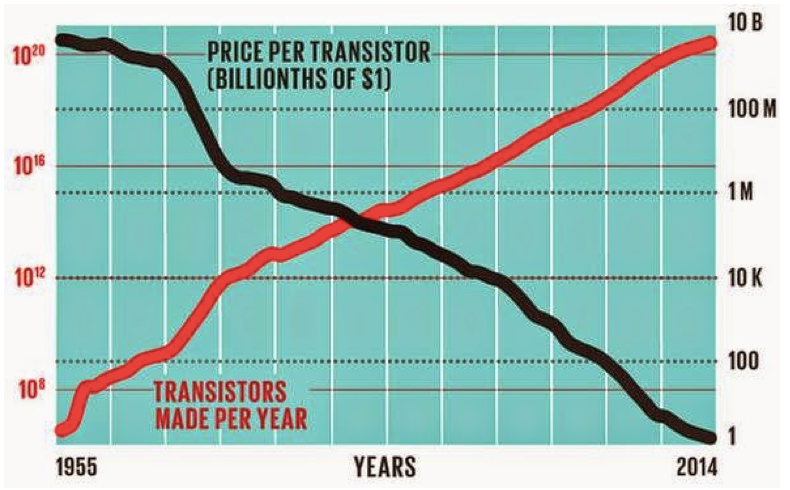
Un tablero de ajedrez tiene 64 cuadrados. En la primera mitad, realizamos 32 duplicaciones de los granos de arroz empezando en el año 1965 (Ley de Moore), y nos colocamos en la segunda mitad del tablero de ajedrez.
En la segunda mitad del tablero de ajedrez los granos de arroz (datos que las empresas gestionaban) se volvieron muy grandes, como apunté antes, y se planteó un enorme desafío: ¿cómo proceder para acceder y gestionar esa ingente cantidad de datos? A través de "la nube"
O lo que es lo mismo, la creación del #BigDataAnalytics. Los datos ya existían, pero no se podía acceder a ellos ni gestionarlos. ¿Cuándo y cómo fue creado el #BigData? En el año 2007, y gracias a un software: #Hadoop. ¿Cómo y por qué fue creado Hadoop?
Pues nos vamos al año 2003, cuando #Google publicó un documento que incluía una innovación básica llamada Google File System (GFS). Este software permitió a Google acceder y administrar una gran cantidad de datos provenientes de miles de ordenadores storage.googleapis.com/pub-tools-publ…
En este momento, el principal objetivo de Google era organizar TODA LA INFORMACIÓN DEL MUNDO a través de su buscador, pero no pudieron hacerlo sin su segunda innovación básica, #MapReduce, que se publicó en 2004. storage.googleapis.com/pub-tools-publ…
Estas dos innovaciones permitieron a Google procesar y explorar una gran cantidad de datos (Big Data). Google compartió estas dos innovaciones básicas con la comunidad open Source.
La comunidad Open Source, no sólo aprovechó este conocimiento, SINO QUE LO MEJORÓ CREANDO HADOOP en el año 2006. Hadoop es un software Open Source que permite que cientos de miles de ordenadores funcionen como un ordenador gigante. Sus creadores: Doug Cutting y Mike Cafarella.

Esta es la razón por la que estos gigantes tecnológicos se globalizaran en el año 2007. Con Hadoop, la capacidad de almacenamiento de datos explotó, haciendo que el #BigData fuera disponible para todos.
Gracias a Hadoop, otras empresas nacieron en 2007, como @Airbnb @Amazon también lanzó #Kindle y el primer iPhone fue lanzado. Según @ATT el tráfico de datos móviles aumentó en más del 100.000% desde enero de 2007 hasta diciembre de 2014 att.com/Investor/ATT_A…
Desde 2007, los gigantes tecnológicos, a través del análisis del #bigdata, han tenido la oportunidad de almacenar todos sus datos (segunda mitad del tablero de ajedrez) en un solo lugar y, por lo tanto, tener un mayor conocimiento del mercado que las empresas tradicionales.
¿Qué consecuencias tuvo esto? Aumento en millones de usuarios para los gigantes tecnológicos, pudiendo ofrecer increíbles productos gracias a todos los datos que Hadoop les permitía almacenar, y permitiéndoles actuar como monopolios debido a su dominio en el mercado y del mercado
Las decisiones de las empresas empezaron a tomarse a través de procesos automatizados de toma de decisiones a través de los perfiles de individuos y grupos. En algunos casos, para realizar publicidad segmentada, pero en otros casos...
estas decisiones automatizadas inciden negativamente en nuestra vida personal y/o profesional, teniendo consecuencias no deseadas debido a resultados sesgados y discriminatorios.
Y en otros casos, debido a la falta de #privacidad, y el dominio del mercado, estos procesos automatizados de toma de decisiones a través de #MachineLearning pueden distorsionar los mercados justos (adapto el precio según tus datos), y elecciones justas (Cambridge Analytica)
Sé que la historia de cómo el #BigData fue creado es densa e intensa, pero creo que es necesario saber de dónde viene la enorme problemática en términos de #privacidad, #eticadelosdatos y #discriminación que estamos sufriendo a nivel global para ser conscientes del problema.
Estos perfiles que de los usuarios, o grupos de usuarios se hacen, y que a través de ellos toman decisions que nos afectan, son inaccesibles para nosotros, por mucho que el RGPD diga que en su artículo 15 que ese derecho nos ampara. No lo hace.
El acceso que tenemos es hasta el punto C) de la imagen que adjunto. A partir de ahí, otras leyes, como la Directiva de Secreto Comerciales, permite a las empresas ser opacas. Y, precisamente, a partir de ese punto, si son transparentes es por una decisión ética.

Algunos dirán que sí que tenemos acceso, que si pedimos la información que de nosotros tienen en sus perfiles, nos la mandan. Vale, ¿pero en qué formato? páginas excel con información imposible de descifrar. Vamos, que no nos sirve de nada. Pero no solamente queremos esa info...
Vuelvo a adjuntar imagen (confeccionada por @steennewmexico y por mi para nuestro paper). Queremos saber cómo están segmentadas tus bases de datos, porque es en las bases de datos donde empieza el sesgo y la discriminación (Punto C)). Sigo... (ya falta poquito).
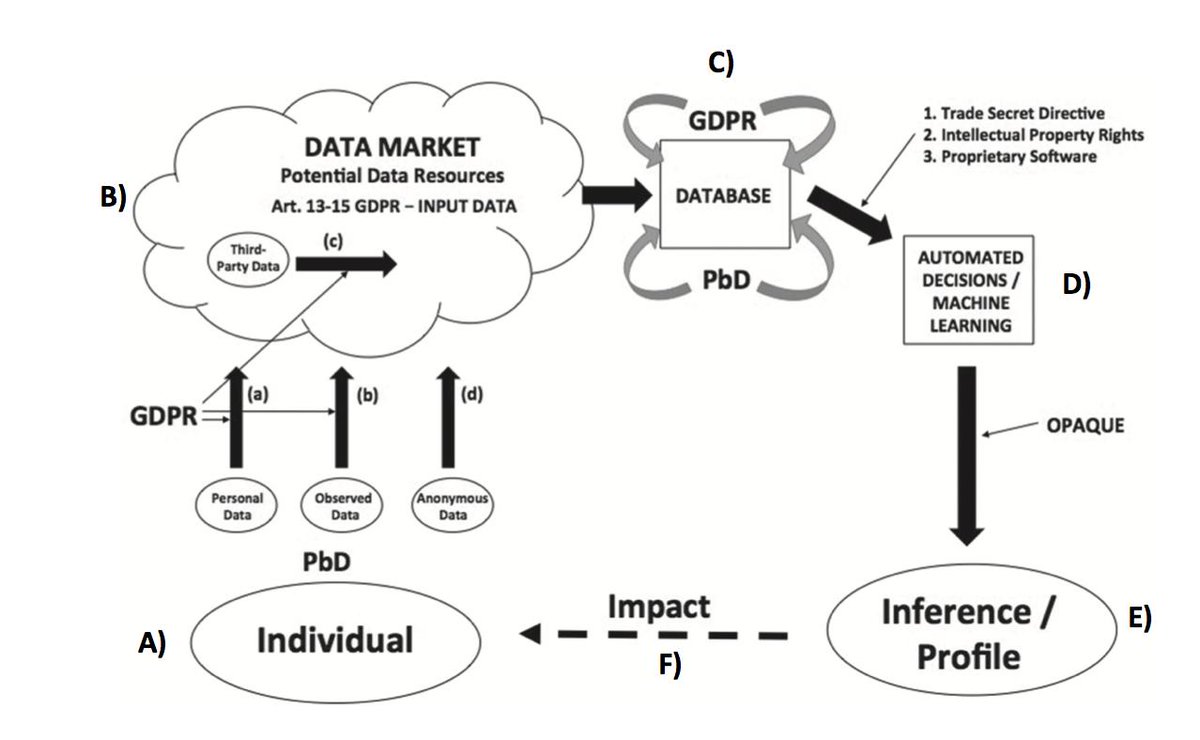
Queremos saber cómo está entrenado tu algoritmo (punto D)) para que cuando introduzcas los datos tal y como los tienes en la base de datos, confeccionen los perfiles, o hagan las predicciones, o tomen decisiones que me van a afectar a mi vida privada.
También quiero saber qué datos has usado para la confección de mi perfil para saber si son ciertos, o están sesgados (punto E)) , y las consecuencias en mi vida privada/profesional.
Y en base a esta información, y nuestros derechos, cada sábado me he dispuesto a hablar sobre las políticas de privacidad de las empresas y de si respetan, o no ,nuestros #datospersonales y nuestra #privacidad, que es un problemón que tenemos desde el 2007.