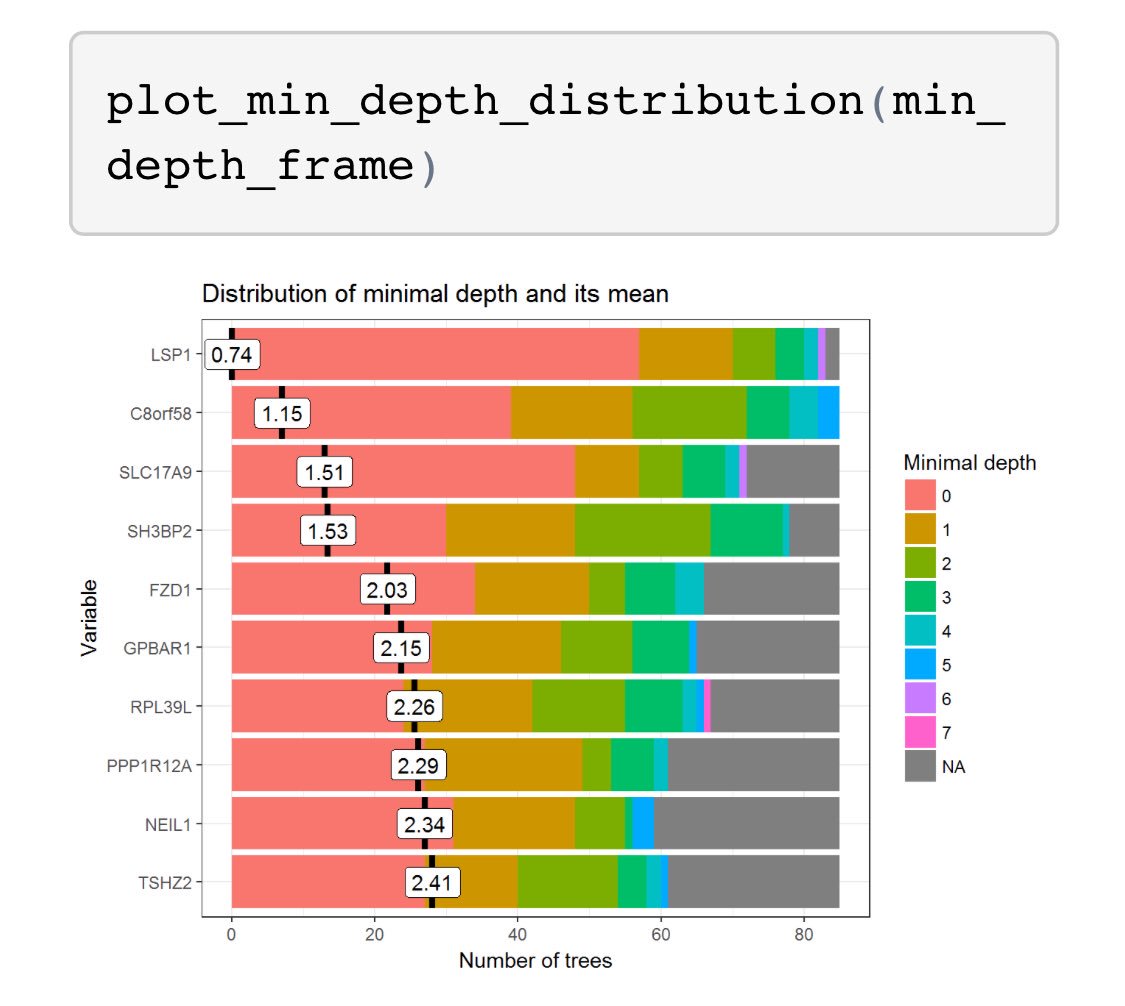
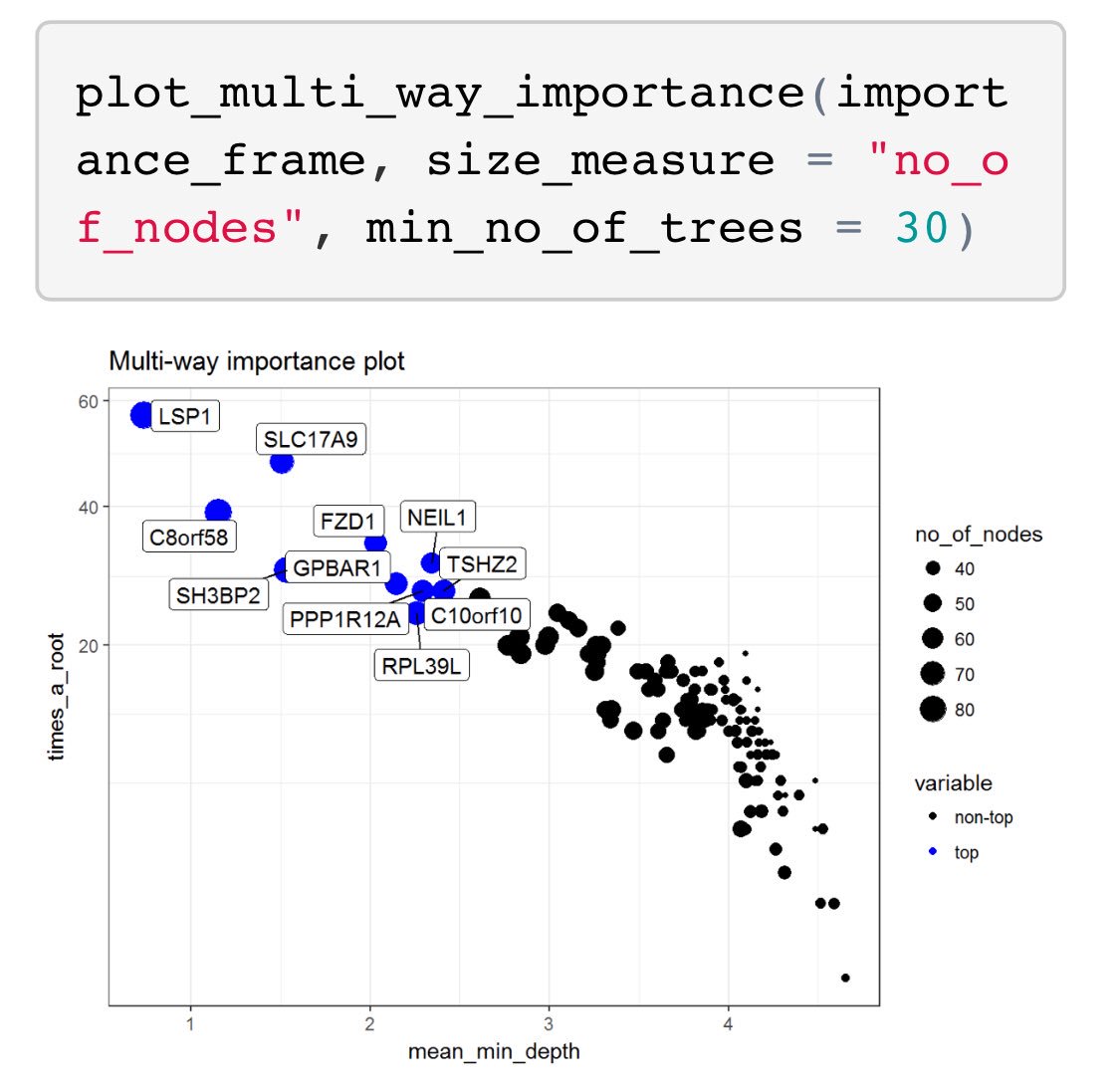
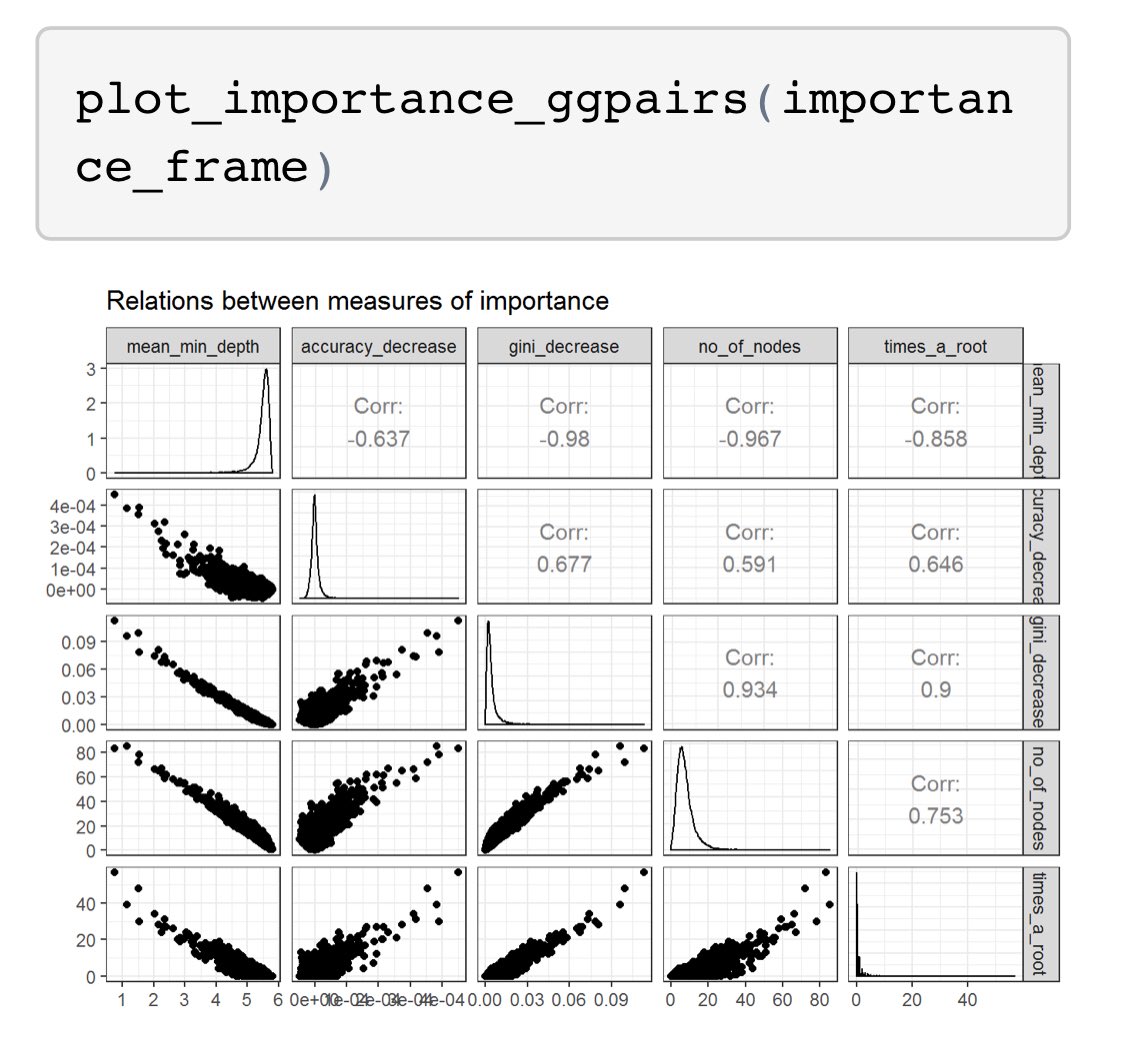
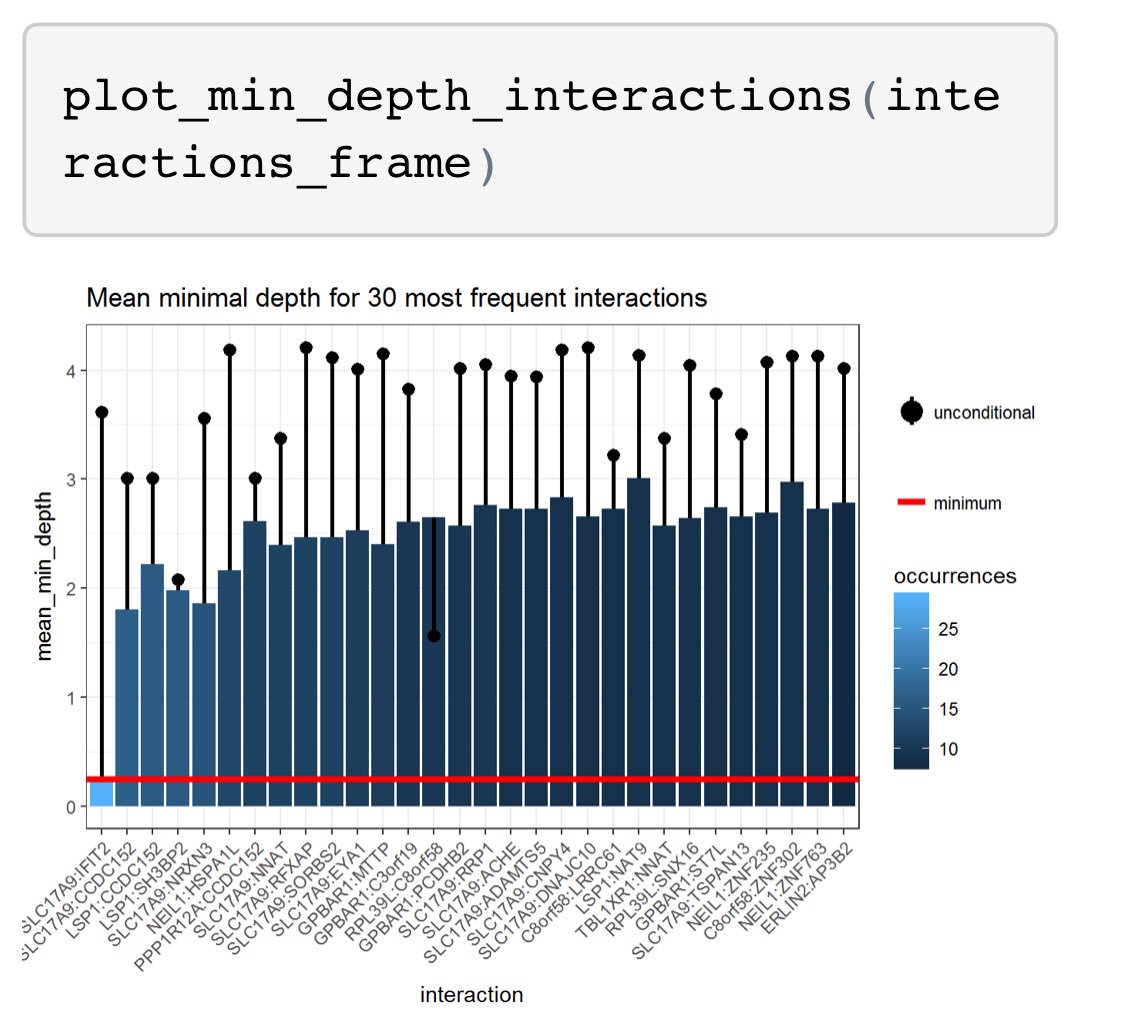
I’ll be giving a talk on implementing predictive models at @HDAA_Official on Oct 23 in Ann Arbor. Here’s the Twitter version.
Model developers have been taught to carefully think thru development/validation/calibration. This talk is not about that. It’s about what comes after...
Model developers have been taught to carefully think thru development/validation/calibration. This talk is not about that. It’s about what comes after...

But before we move onto implementation, let’s think thru what model discrimination and calibration are:
- discrimination: how well can you distinguish higher from lower risk people?
- calibrations: how close are the predicted probabilities to reality?
... with that in mind ...
- discrimination: how well can you distinguish higher from lower risk people?
- calibrations: how close are the predicted probabilities to reality?
... with that in mind ...

Which of the following statements is true?
A. It’s possible to have good discrimination but poor calibration.
B. It’s possible to have good calibration but poor discrimination.
A. It’s possible to have good discrimination but poor calibration.
B. It’s possible to have good calibration but poor discrimination.
Before you can even think of implementing a model, you need to start with a good model.
At the minimum, it needs to have 💪 internal validation using the data where it was derived, both in discrimination and calibration (using holdout/CV/bootstrap, etc).
Once you’ve got that...
At the minimum, it needs to have 💪 internal validation using the data where it was derived, both in discrimination and calibration (using holdout/CV/bootstrap, etc).
Once you’ve got that...

Then it’s onto Habit 1: select a “treatable” problem where experts agree on the right course of action.
Sepsis seems like such a problem, right? There are certainly tons of models predicting sepsis in the literature...
And how hard can it be to give antibiotics to septic pts?
Sepsis seems like such a problem, right? There are certainly tons of models predicting sepsis in the literature...
And how hard can it be to give antibiotics to septic pts?

Speaking of sepsis, what exactly is sepsis? Which definition to use?
1. Sepsis-3 consensus defn (medically accurate)
2. Medicare SEP-1 quality measure (based on billing)
If you optimize algo for #1 only, you may end up “hurting” quality measures despite improving sepsis care.
1. Sepsis-3 consensus defn (medically accurate)
2. Medicare SEP-1 quality measure (based on billing)
If you optimize algo for #1 only, you may end up “hurting” quality measures despite improving sepsis care.

At @umichmedicine, we are evaluating our implemented sepsis model on both #1 and #2 so that we understand implications of model performance on both definitions of sepsis.
Let’s say we could all agree on a sepsis definition, do we all agree on treatment?
Let’s say we could all agree on a sepsis definition, do we all agree on treatment?
In this paper by Downing et al (from @StanfordMed), a model-based alert for sepsis led to no difference in primary/secondary outcomes.
One of the outcomes was admin of 30 mL/kg of IV fluids for sepsis hypoperfusion. Why didn’t alerts work? Many MDs disagreed with guidelines...
One of the outcomes was admin of 30 mL/kg of IV fluids for sepsis hypoperfusion. Why didn’t alerts work? Many MDs disagreed with guidelines...

Given that the study found no difference in outcomes, it was terminated early ... SO THAT THE ALERTS COULD BE EXPANDED THROUGHOUT THE WHOLE HOSPITAL?!
A bold move... and one that we are copying at @umichmedicine (based on other evidence). So what else is needed?
A bold move... and one that we are copying at @umichmedicine (based on other evidence). So what else is needed?

Habit 2 is that you need infrastructure and resources.
Model devs dream of having server with interface to EHR.
You’ve got 10 interfaces. None of them deal with predicting no-shows. Now you’ve got 11 interfaces.
This doesn’t scale and ⬆️ prob of one breaking when EHR updates.
Model devs dream of having server with interface to EHR.
You’ve got 10 interfaces. None of them deal with predicting no-shows. Now you’ve got 11 interfaces.
This doesn’t scale and ⬆️ prob of one breaking when EHR updates.

An infrastructural problem needs an infrastructural solution.
There are several options on technical side for running all models in one place, including open source solutions such as KGrid (developed at @umichDLHS), EHR vendor-based clouds, and other internal/external clouds.
There are several options on technical side for running all models in one place, including open source solutions such as KGrid (developed at @umichDLHS), EHR vendor-based clouds, and other internal/external clouds.

Another key infrastructural issue is governance, the “social” part of sociotechnical infrastructure.
At @umichmedicine, we have a multidisciplinary committee (Clinical Intelligence Committee) that oversees model implementation. It is a “sister” committee to our CDS committee.
At @umichmedicine, we have a multidisciplinary committee (Clinical Intelligence Committee) that oversees model implementation. It is a “sister” committee to our CDS committee.

Issues we are grappling with for governance:
1. If model dev is researcher, do they need to support model during normal business hours if problems occur?
2. Outside of business hours, how to respond to models gone rogue?
3. Prior to model updates, who needs to sign off?
1. If model dev is researcher, do they need to support model during normal business hours if problems occur?
2. Outside of business hours, how to respond to models gone rogue?
3. Prior to model updates, who needs to sign off?
Habit 3 is to perform a “local” validation (where the “external validation” = OUR HEALTH SYSTEM).
Miscalibration of models developed elsewhere is common but poor model discrimination can also be found, as has happened to us. This can lead to a model being dead-on-arrival.
Miscalibration of models developed elsewhere is common but poor model discrimination can also be found, as has happened to us. This can lead to a model being dead-on-arrival.

Why might a local (prospective) validation fail?
Many reasons, but even if the model was developed locally, issues with timestamps and variable mappings between research and operational databases can lead to unexpected performance drops in prospective local validation.
Many reasons, but even if the model was developed locally, issues with timestamps and variable mappings between research and operational databases can lead to unexpected performance drops in prospective local validation.

If it’s JUST a calibration issue, take a look at the 8 ways to recalibrate models in @ESteyerberg’s Clinical Prediction Models book (2nd edition).
Most of these methods can be readily implemented to adjust an existing model’s output to be better calibrated for local data.
Most of these methods can be readily implemented to adjust an existing model’s output to be better calibrated for local data.
I borrowed Habit 4 from “5 rights of CDS” but it’s different in that there are more ways to operationalize model output.
We use:
1. Pages (for sepsis alerts)
2. Case management of hi-risk pts in SIM project (with @CHRTumich)
3. Pt lists sorted by acuity (in ER)
and others...
We use:
1. Pages (for sepsis alerts)
2. Case management of hi-risk pts in SIM project (with @CHRTumich)
3. Pt lists sorted by acuity (in ER)
and others...

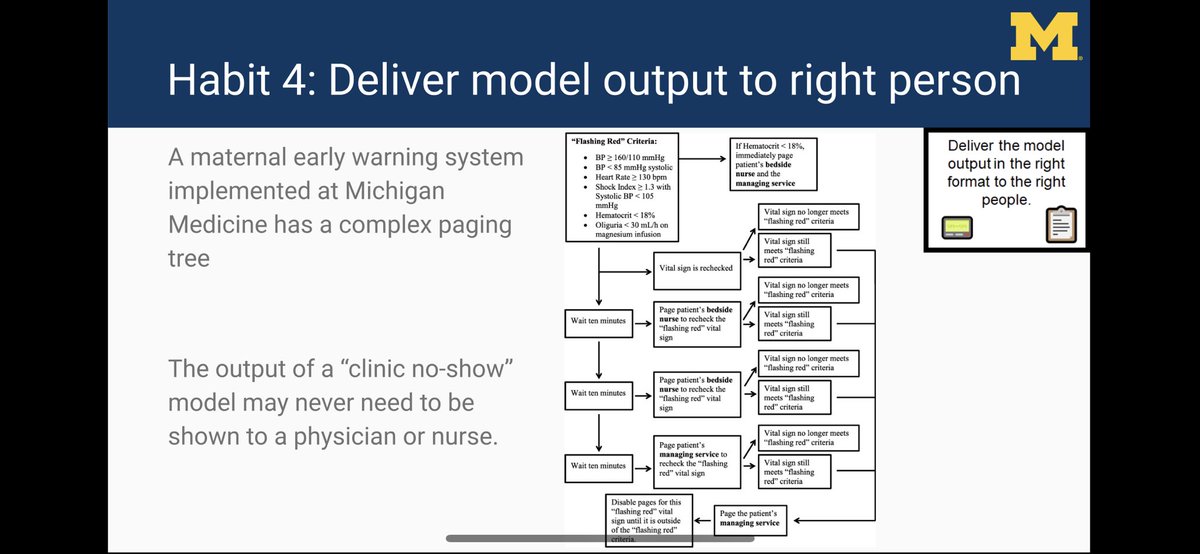
The maternal early warning system operationalized at @umichmedicine (via @AlertWatchMed) has a complex paging tree for RNs/MDs (OB and OB anesthesiologists).
On the other hand, output from a clinic no-show model might be shown primarily to an admin (we have not implemented one).
On the other hand, output from a clinic no-show model might be shown primarily to an admin (we have not implemented one).
Habit 5 is to balance the workload budget. If every model results in more cognitive or physical load, it’s not hard to imagine this directly contributing to burnout.
For alerts to work, need to de-implement ones that don’t work and use models to de-escalate low value care.
For alerts to work, need to de-implement ones that don’t work and use models to de-escalate low value care.

Habit 6 is to start with a low-fidelity pilot.
The first question I ask clinicians wanting to implement a model is: what are you going to do with the output?
Use a low-fidelity pilot to explore possible ways to incoporate a model into your process flow. This will payoff later.
The first question I ask clinicians wanting to implement a model is: what are you going to do with the output?
Use a low-fidelity pilot to explore possible ways to incoporate a model into your process flow. This will payoff later.

Lastly, Habit 7 is to deploy, monitor, and adapt.
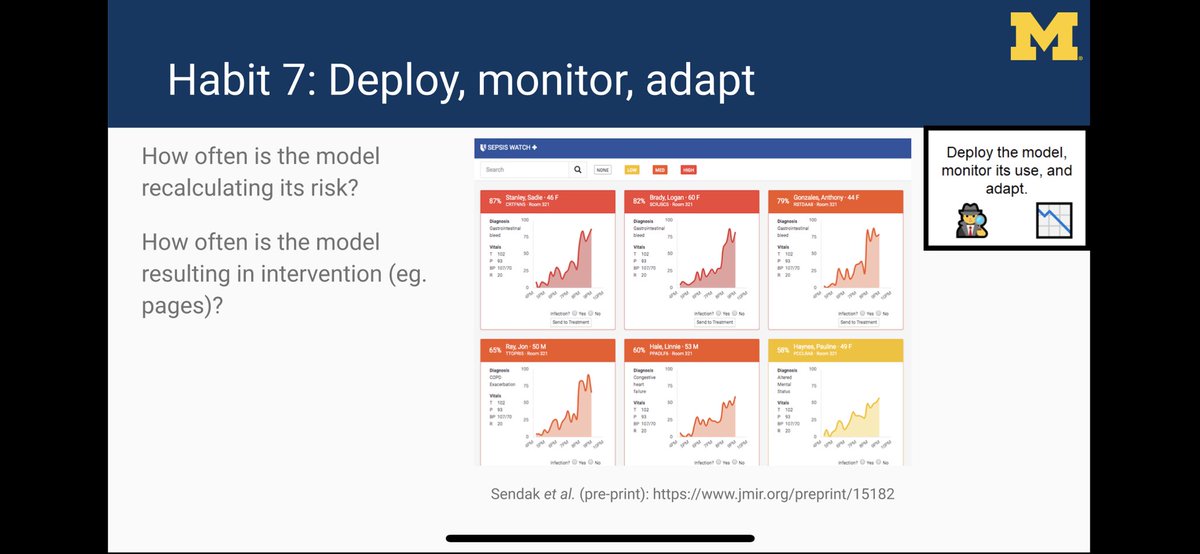
Do you know how often your model is running/alerting? An EHR update can break models silently by messing up variable mappings.
Need a dashboard to monitor models.
👇 dashboard by @MarkSendak @JFutoma @kat_heller @DukeInnovate
Do you know how often your model is running/alerting? An EHR update can break models silently by messing up variable mappings.
Need a dashboard to monitor models.
👇 dashboard by @MarkSendak @JFutoma @kat_heller @DukeInnovate
Part of the monitoring involves watching for calibration drift, which can be subtle and occur slowly over time.
Guess what happens when the outcome occurs ⬆️/⬇️ frequently over time? Your current health system doesn’t look like the one you locally validated. Need to recalibrate.
Guess what happens when the outcome occurs ⬆️/⬇️ frequently over time? Your current health system doesn’t look like the one you locally validated. Need to recalibrate.

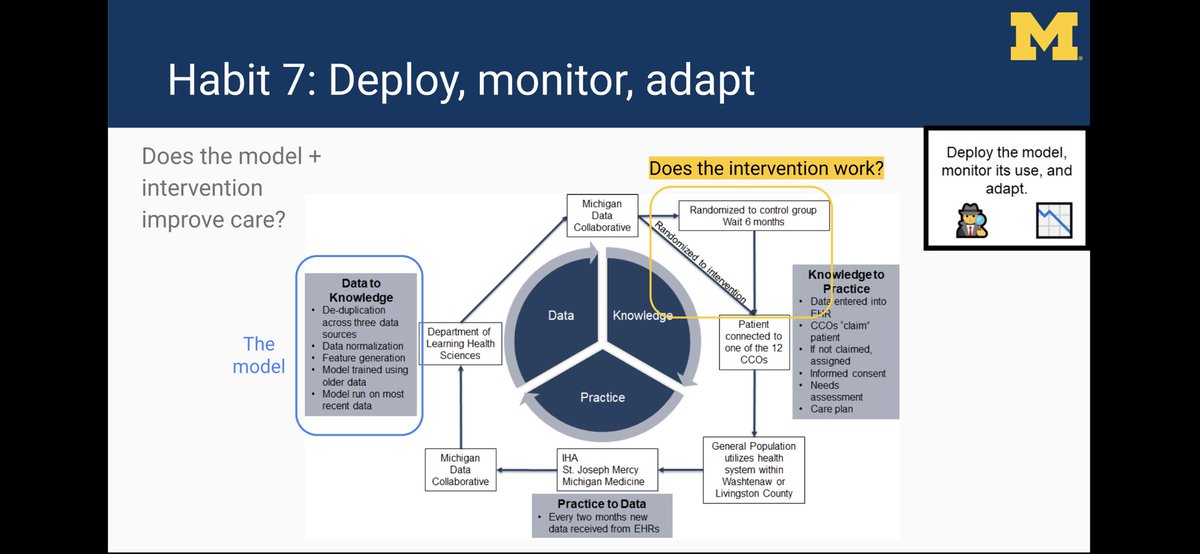
When you link a model to an intervention (as you should), you also need to figure out whether the model+intervention works better than no intervention.
We embedded an ER utilization model within an RCT (working with @CHRTumich @Andy_Ryan_dydx) to figure out if intervention works
We embedded an ER utilization model within an RCT (working with @CHRTumich @Andy_Ryan_dydx) to figure out if intervention works
In conclusion, for every successful model implementation you read about, there are at least 100 that failed at some step along the way.

Have lots of colleagues to thank for where we are @umichmedicine with implementing predictive models and where we are heading (including many not on this slide).
I presented a shorter version of this talk at @mlforhc 2019.
Here’s a link to our abstract: static1.squarespace.com/static/59d5ac1…
/fin
Here’s a link to our abstract: static1.squarespace.com/static/59d5ac1…
/fin