

Actually, Day 2 Session 3 #hasphdcantcount
#Input: Many problems -- many possible solutions! How to find the right one? #goldilocks
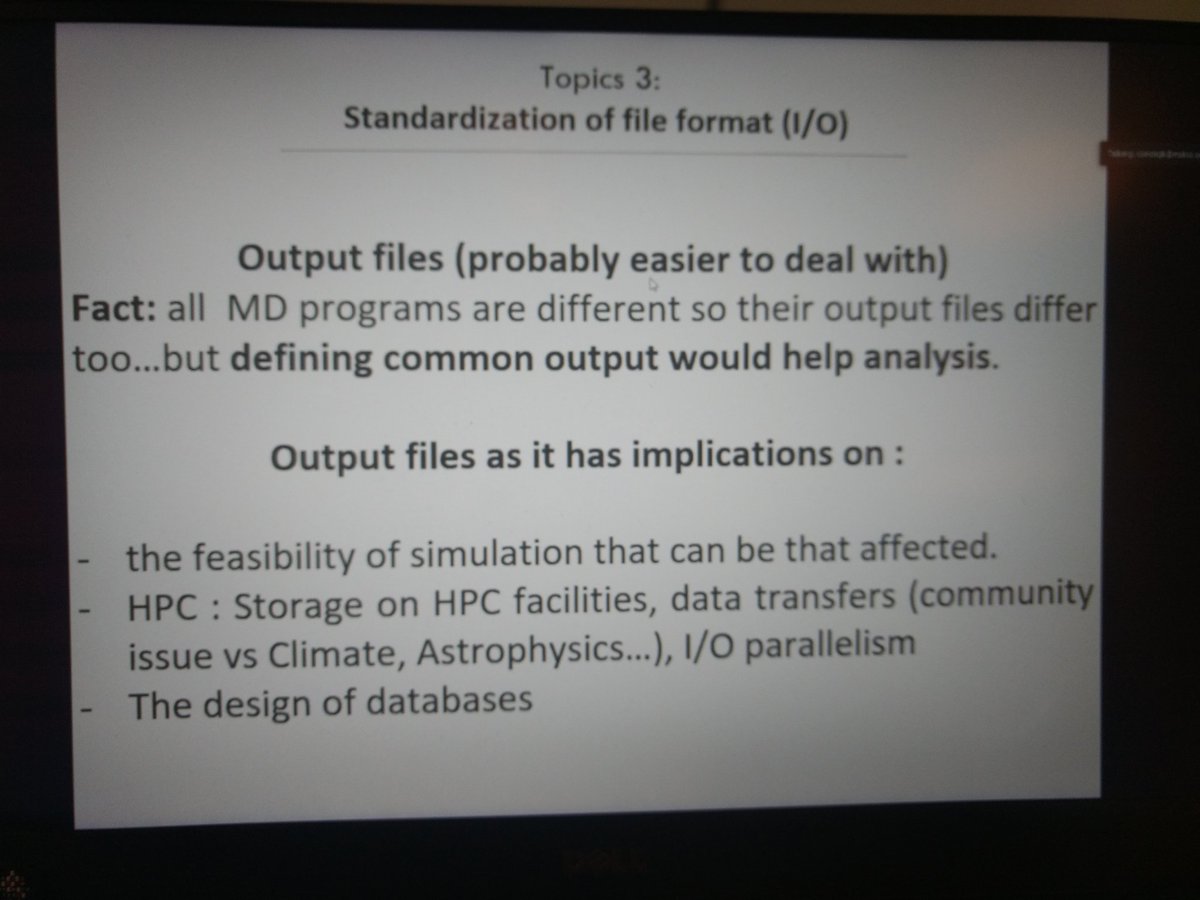
#Output: probably easier to handle and we can learn from other fields, like climate research.
#Output: probably easier to handle and we can learn from other fields, like climate research.
One emerging consensus in the room -- #killpdb. However, what to use to replace it?
cc: @agrossfield
cc: @agrossfield
#HPC performance should be taken into account to prevent #MD being kicked out from supercomputers due to inefficiencies. We also need to take streaming and new tech, such as AR/VR, into account. But, how many #fileformats?
@TINKERtoolsMD chose to use #NetCDF for practical purposes. @daniel_r_roe cheers remotely for the wider adoption of NetCDF 🙌
Multiple solutions exist for output files too, but coming up with a clear #semantic definitions has been mentioned a lot today

The second speaker in the session is Joao Ribeiro of #NAMD -- only pointing fingers at themselves -- a lot of space for improvement.
This talk was fast!
This talk was fast!
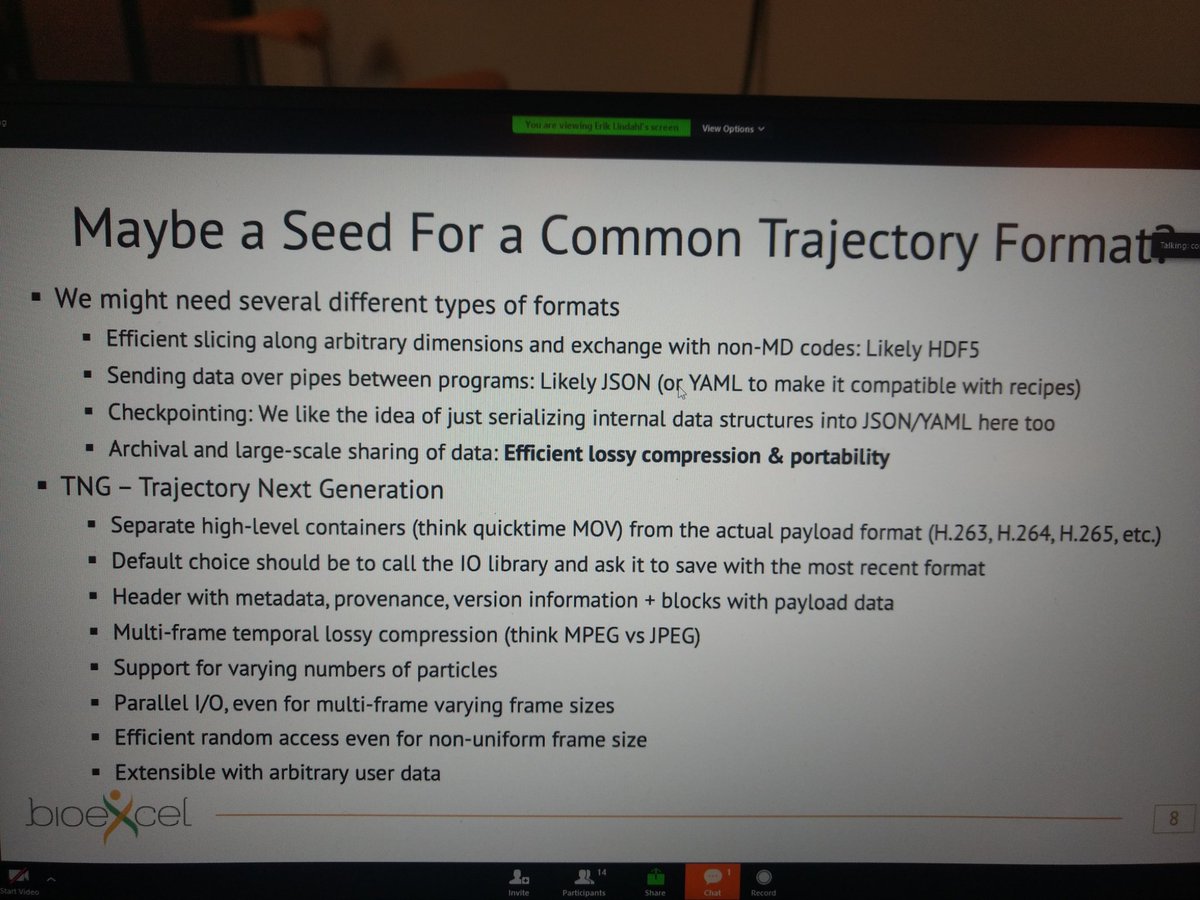
Next is @eriklindahl will share some thoughts not on file formats, but on information exchange as a more important thinking category in this context.
"Interoperability is first #semantics, not #formats".
"Interoperability is first #semantics, not #formats".

What coffee means in different countries, cities and cultures? According to @eriklindahl, the middle cup is sold as coffee, but it's actually sweet brown water...
So, what do we mean when we say things? #semantics strikes again
So, what do we mean when we say things? #semantics strikes again

#Provenance is also an important part of this discussion.
Some suggested solutions below, in essence -- find a core set of common options that we all agree on. Which is a large amount of work.
Some suggested solutions below, in essence -- find a core set of common options that we all agree on. Which is a large amount of work.

If something was good 20-30 years ago, doesn't mean we should still use it in 2020 -- we need to move on and allow depreciation of (poorly) aged features


Where we do really bad in our field? Force fields and parameterized systems. How do we even start here? So many different ways to assign parameters and every package is doing it differently -- each of this ways is associated with a different workflow.
Any format must be #modular and #extensible!
Peter ends with an optimistic outlook: Sorting this out will be a lot of work that will keep occupied for a long time to come 🔧⚙️
Peter ends with an optimistic outlook: Sorting this out will be a lot of work that will keep occupied for a long time to come 🔧⚙️

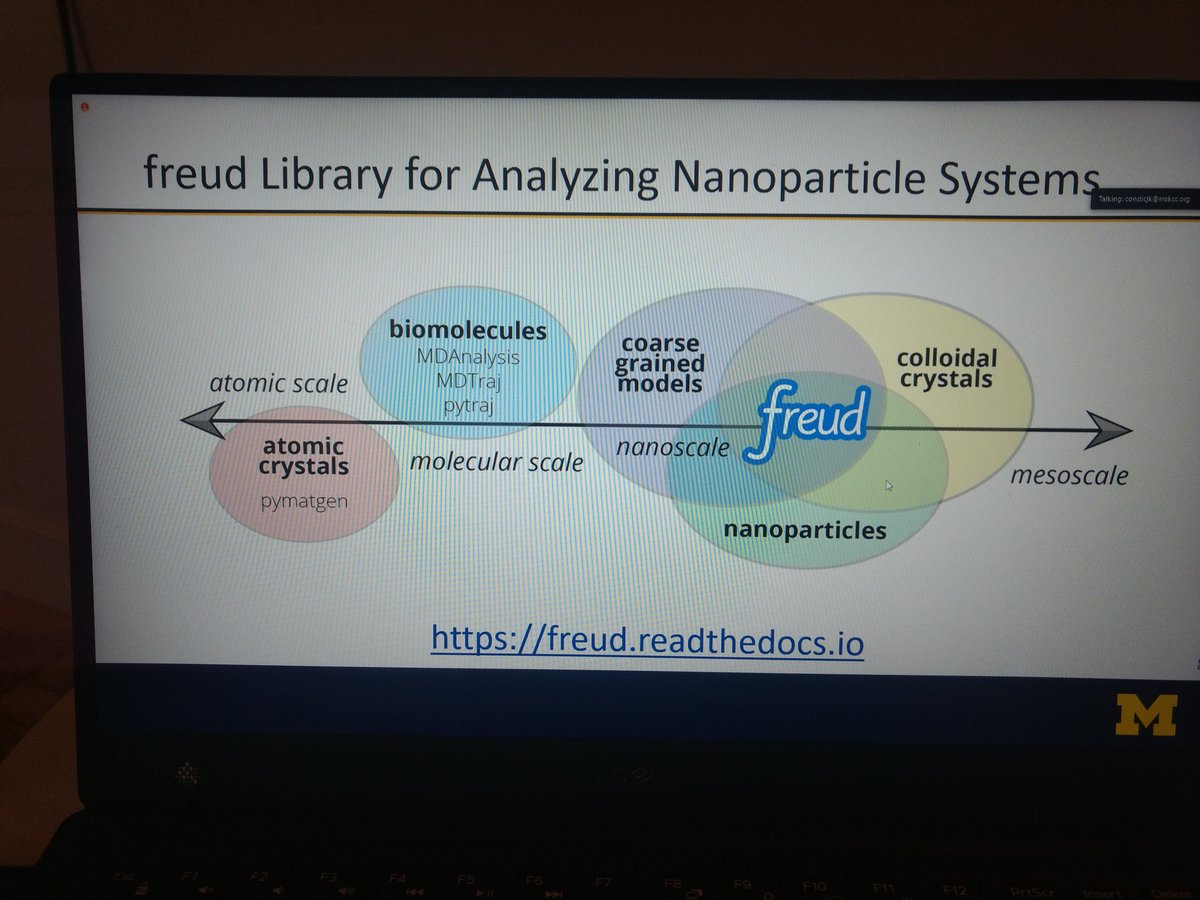
They are also working on #freud library for analysis of coarse grained models, nanoparticles and colloidal crystals.
glotzerlab.engin.umich.edu/hoomd-blue/
freud.readthedocs.io/en/stable/
glotzerlab.engin.umich.edu/hoomd-blue/
freud.readthedocs.io/en/stable/


Challenges with parameters ordered from easy to difficult.
Impropers are terrible. Terrible.
Impropers are terrible. Terrible.








