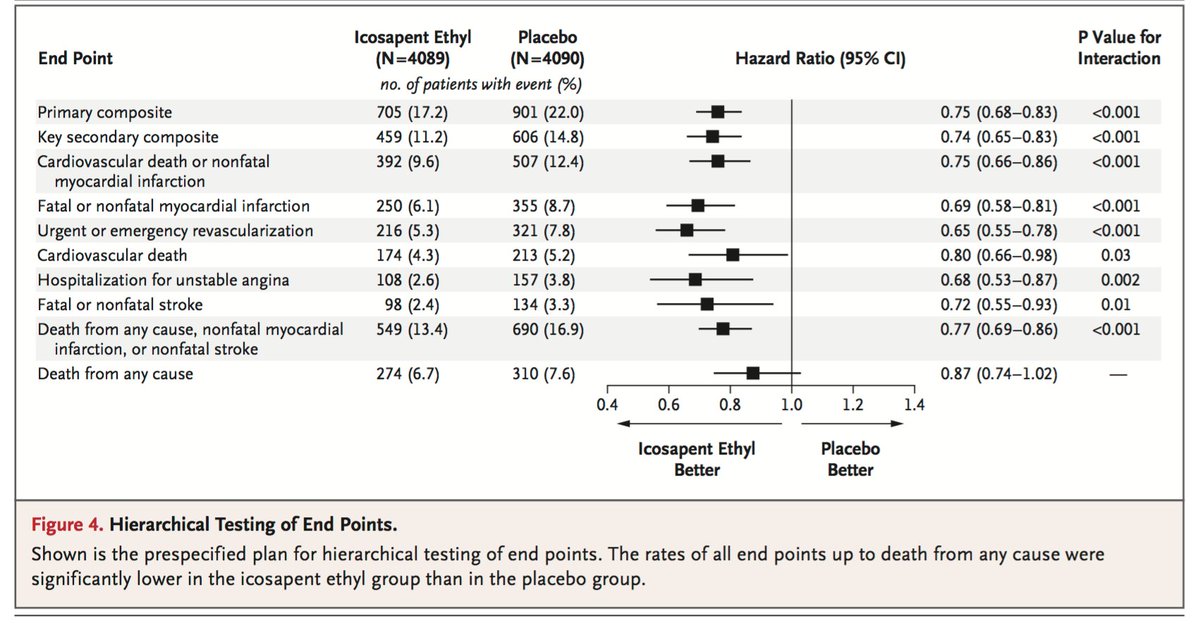
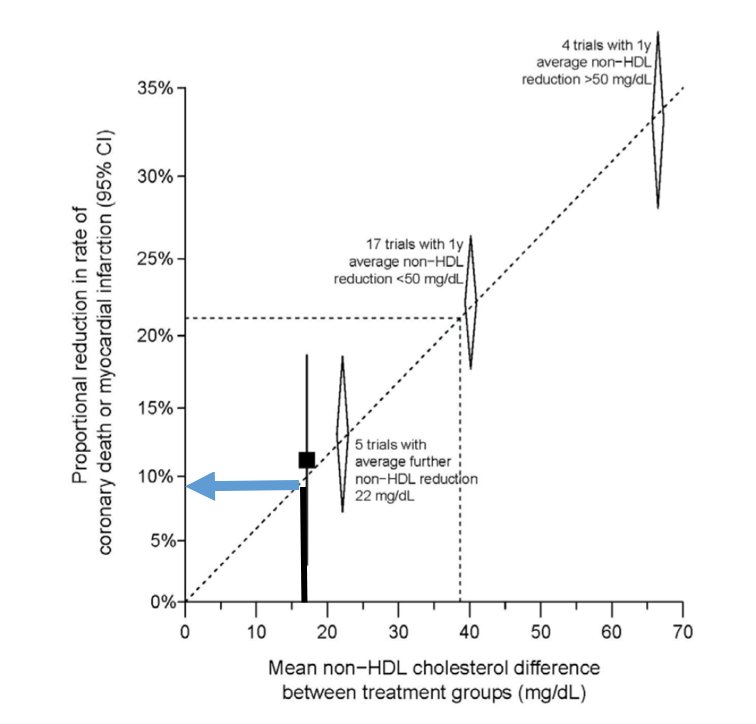
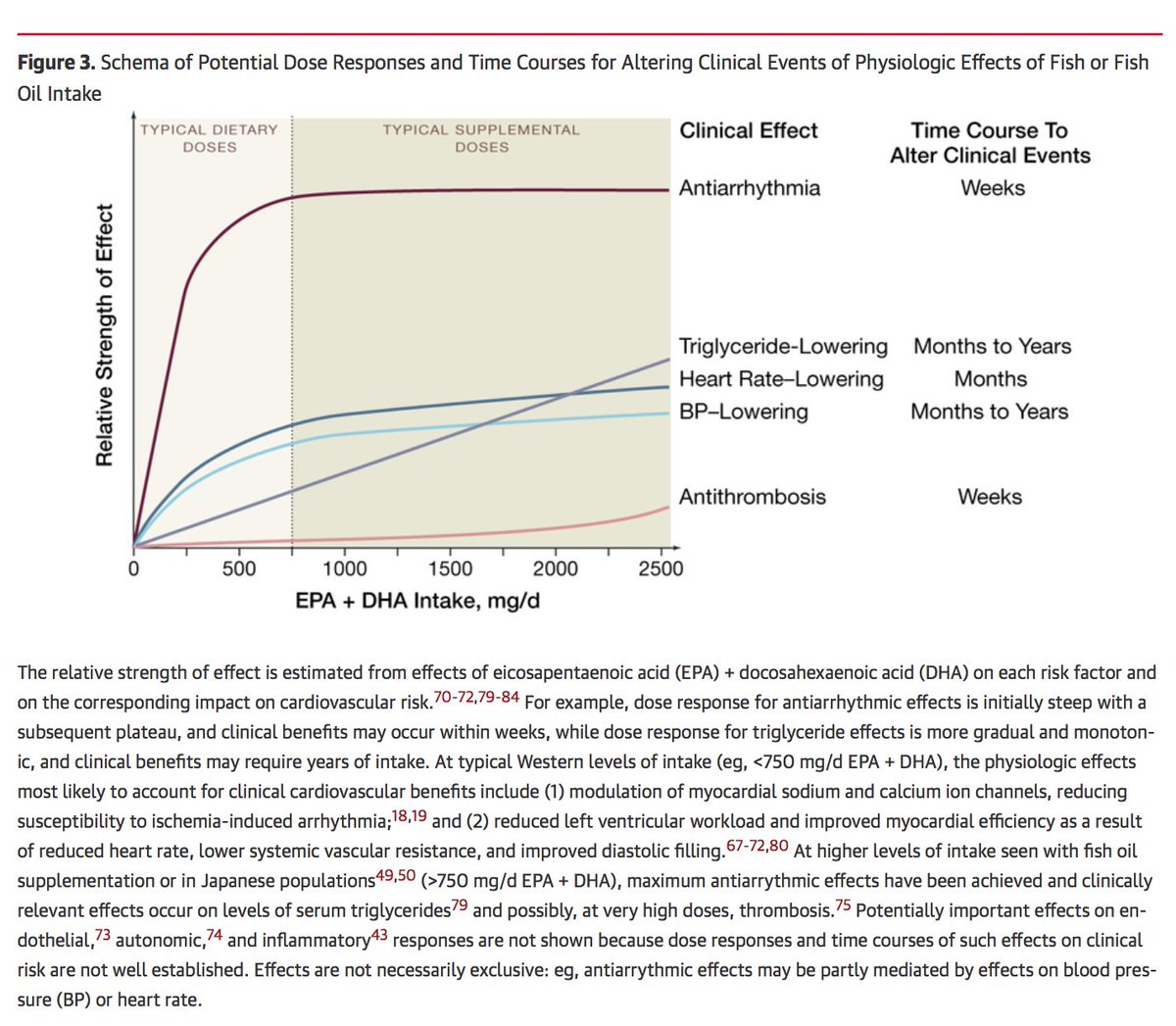
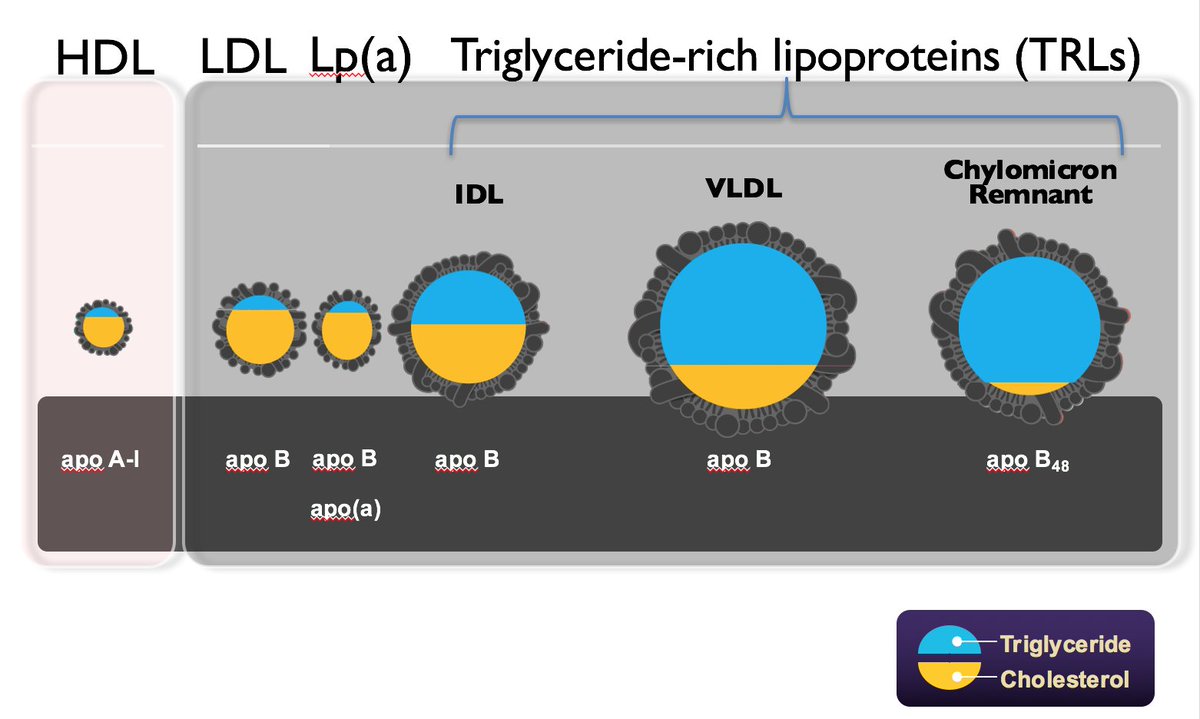
Thank you @euanashley and @joshuawknowles for the nice perspective piece. We agree that it is time to *contemplate* the inclusion of polygenic risk prediction in clinical care.
I am going to expand with some unpublished data on genome-wide polygenic scores for heart attack.
I am going to expand with some unpublished data on genome-wide polygenic scores for heart attack.
We looked at 5000 people with heart attack at a young age (men<50, women<60).
In ~2%, we can identify a monogenic mutation in LDLR, APOB, PCSK9.
What's going on in the remaining 4,900?
In ~2%, we can identify a monogenic mutation in LDLR, APOB, PCSK9.
What's going on in the remaining 4,900?
Over last 10y, we have explored whether a polygenic model can explain risk for early heart attack. 

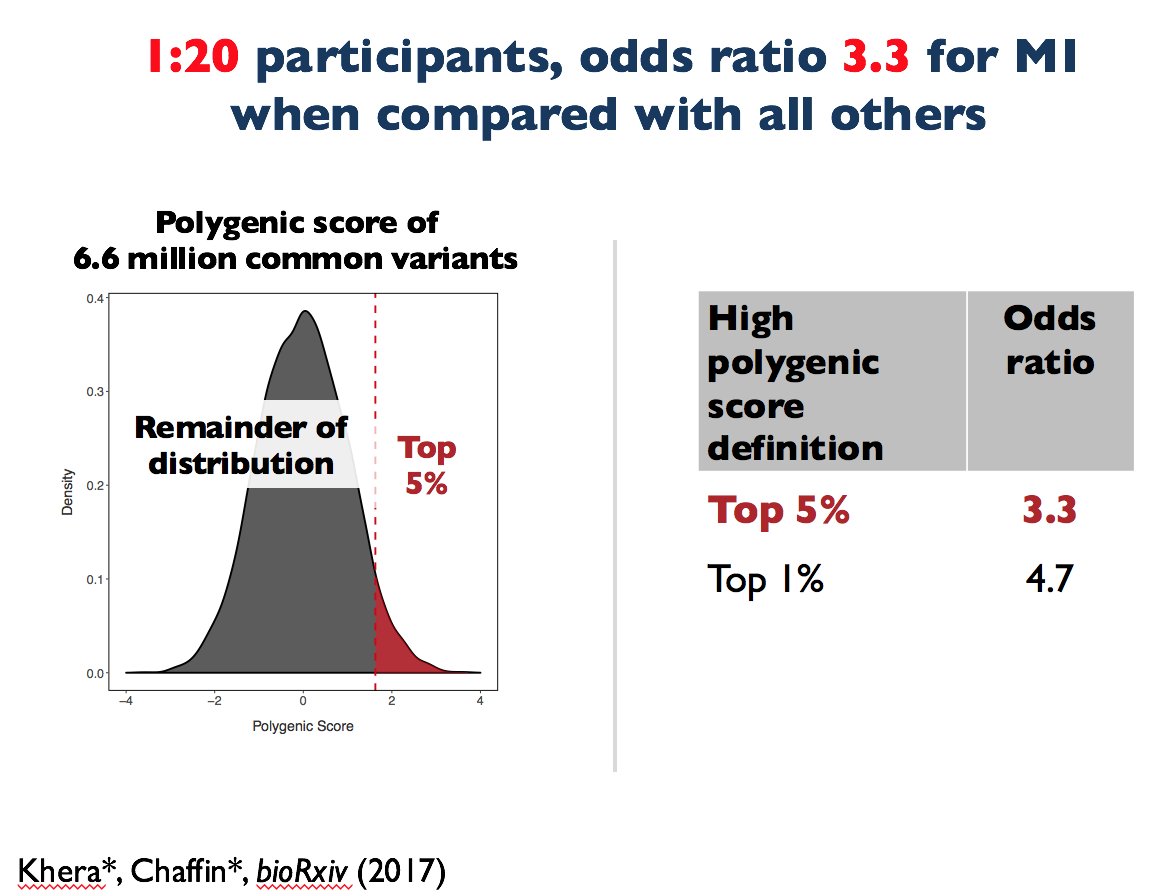
Using 6.6M common SNPs, we now have developed a quantitative metric of inherited liability to heart attack. This quantitative metric:
1. conforms to a Gaussian distribution
2. Those in the extreme of this distribution have levels of risk equivalent to monogenic mutation
1. conforms to a Gaussian distribution
2. Those in the extreme of this distribution have levels of risk equivalent to monogenic mutation
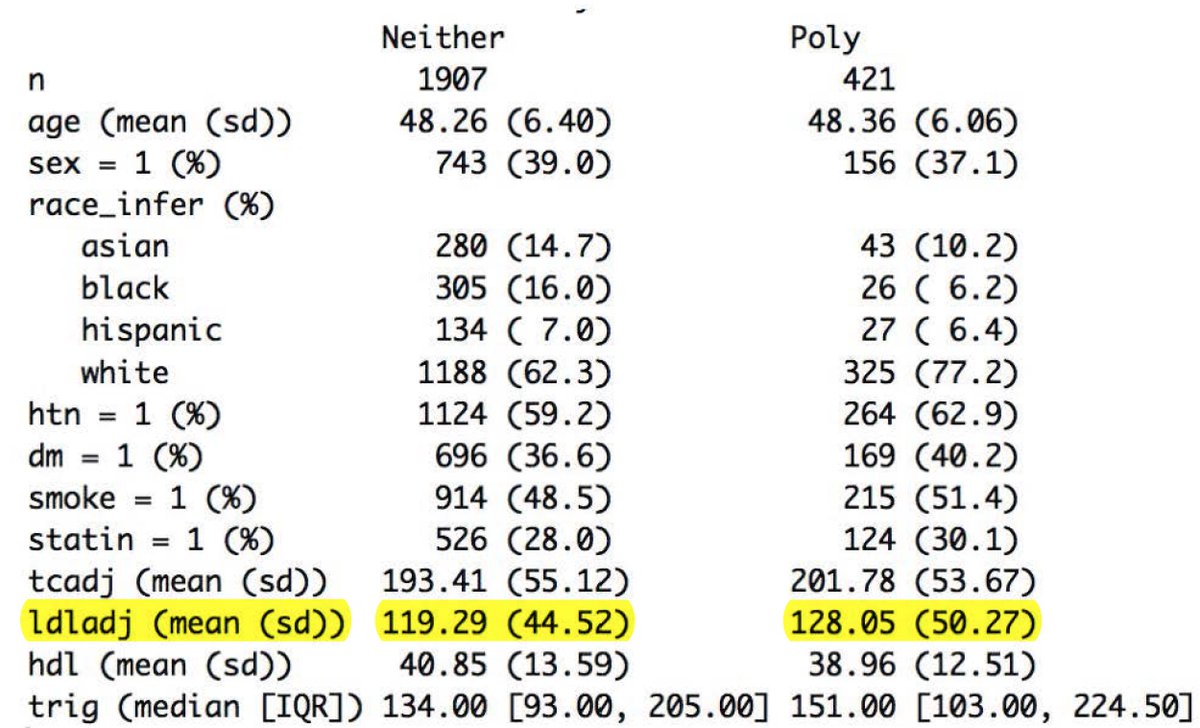
Most important: Those in the extreme of genome-wide polygenic risk score are NOT distinguished by known risk factors!
Look at the mean LDL in the high polygenic risk group versus all others: 128 mg/dl versus 119!
Look at the mean LDL in the high polygenic risk group versus all others: 128 mg/dl versus 119!
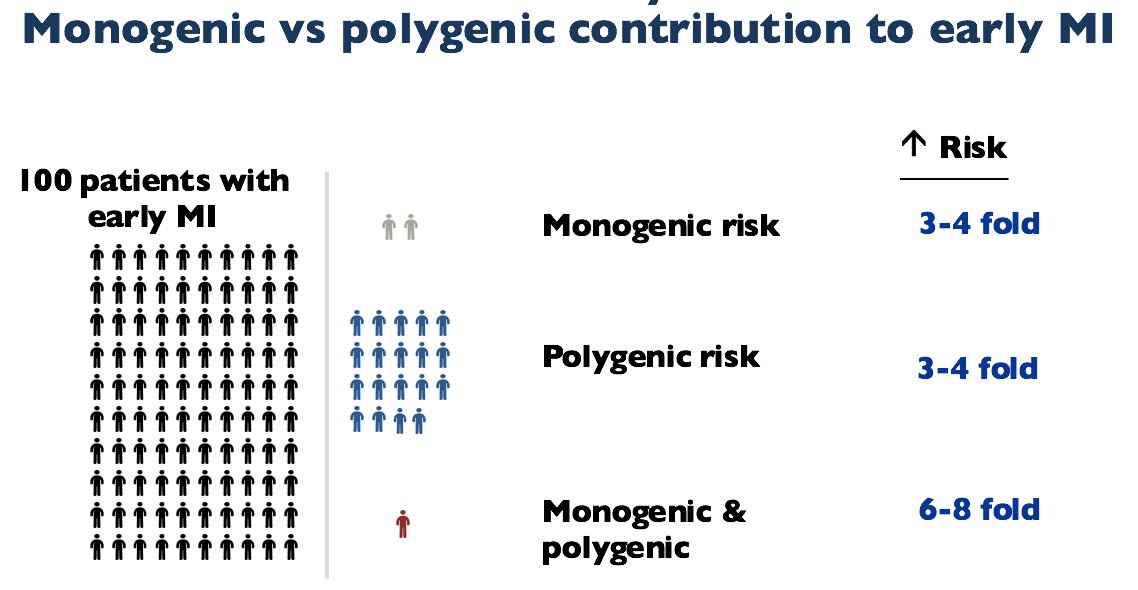
What proportion of early MI patients is due to high polygenic risk?
Below is a summary of the contribution of monogenic and polygenic models to early MI.
Note that those at polygenic risk are currently *UNAWARE* AND not being picked up by traditional risk factors.
Below is a summary of the contribution of monogenic and polygenic models to early MI.
Note that those at polygenic risk are currently *UNAWARE* AND not being picked up by traditional risk factors.
OK. Now, you have a new quantitative metric of genetic liability to heart attack.
Those with high scores are at much higher risk heart attack.
These patients not being picked up by usual risk factors.
But, can one modify this high polygenic risk? Yes. By, lifestyle, statin
Those with high scores are at much higher risk heart attack.
These patients not being picked up by usual risk factors.
But, can one modify this high polygenic risk? Yes. By, lifestyle, statin

Finally, will same score work across different ethnic groups (note recent handwringing on twitter on this topic)?
We took new genome-wide polygenic score derived/validated largely whites & asked if score predictive other ancestries.
Same score *WORKS* across range ancestries.
We took new genome-wide polygenic score derived/validated largely whites & asked if score predictive other ancestries.
Same score *WORKS* across range ancestries.
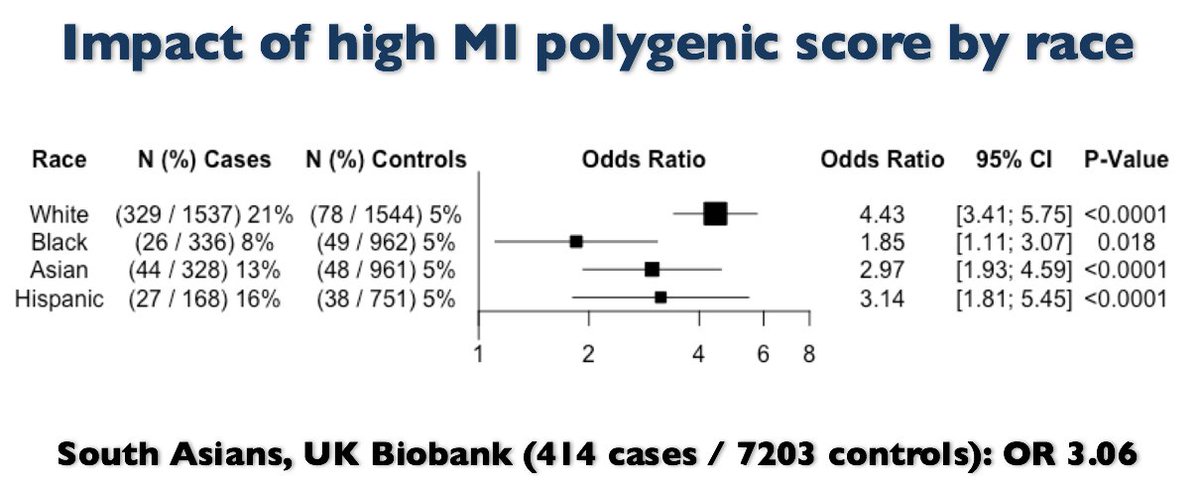
Agree with @euanashley @joshuawknowles that time to *contemplate* integrating new genome-wide polygenic risk score for MI into clinical practice to find those in the extremes of this score & offer preventive intervention.
What are next steps needed in evidence base? Finis.
What are next steps needed in evidence base? Finis.
P.S. And this new approach to scoring genetic liability to disease using a genome-wide set of common SNPs works for a range of common diseases beyond CAD.
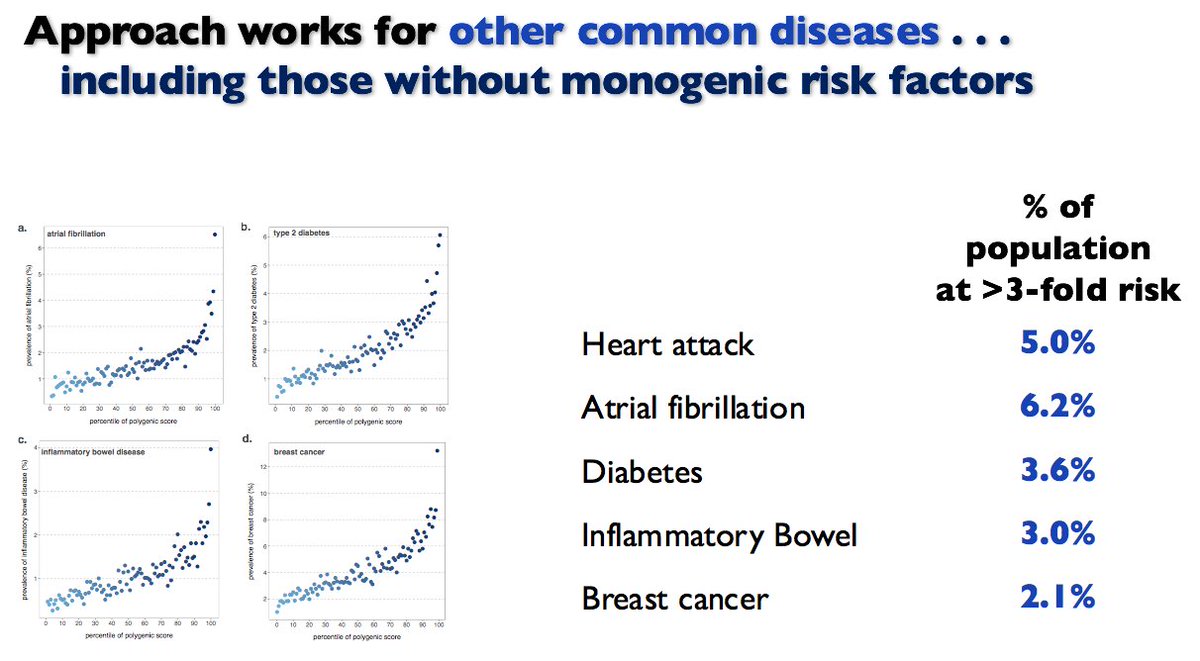
P.S. By the way, to calculate these new genome-wide polygenic scores, all you need is genotype array data combined with statistical imputation.
Despite incorporating 6.6M common variants, our genome-wide CAD polygenic score does *NOT* require whole genome sequencing.
Despite incorporating 6.6M common variants, our genome-wide CAD polygenic score does *NOT* require whole genome sequencing.