I recently had to deal with some robots.txt behaviour that "didn't make sense" and made me feel confused, until I discovered some things I didn't know, so I will share them here in case they're useful for anybody #SEO
The robots.txt file was something similar to this:
- A disallow for /directory/
- Two lines allowing Googlebot to crawl any .css or .js file
But, when testing it with the robots.txt tester, it allowed Googlebot to crawl /directory/
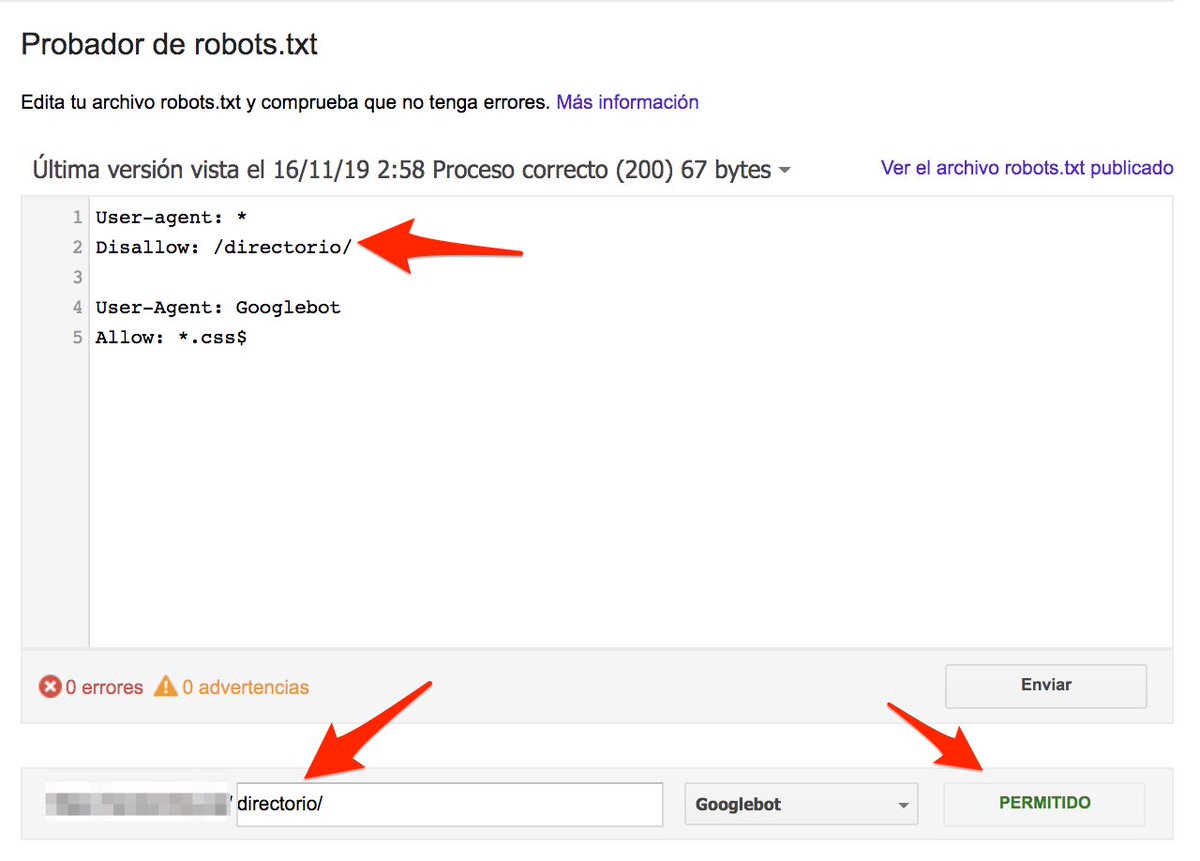
- A disallow for /directory/
- Two lines allowing Googlebot to crawl any .css or .js file
But, when testing it with the robots.txt tester, it allowed Googlebot to crawl /directory/
After several minutes trying to understand, I tried deleting the second set of rules (the ones allowing Googlebot to crawl css/js files), and after that, the first rule worked as I expected:

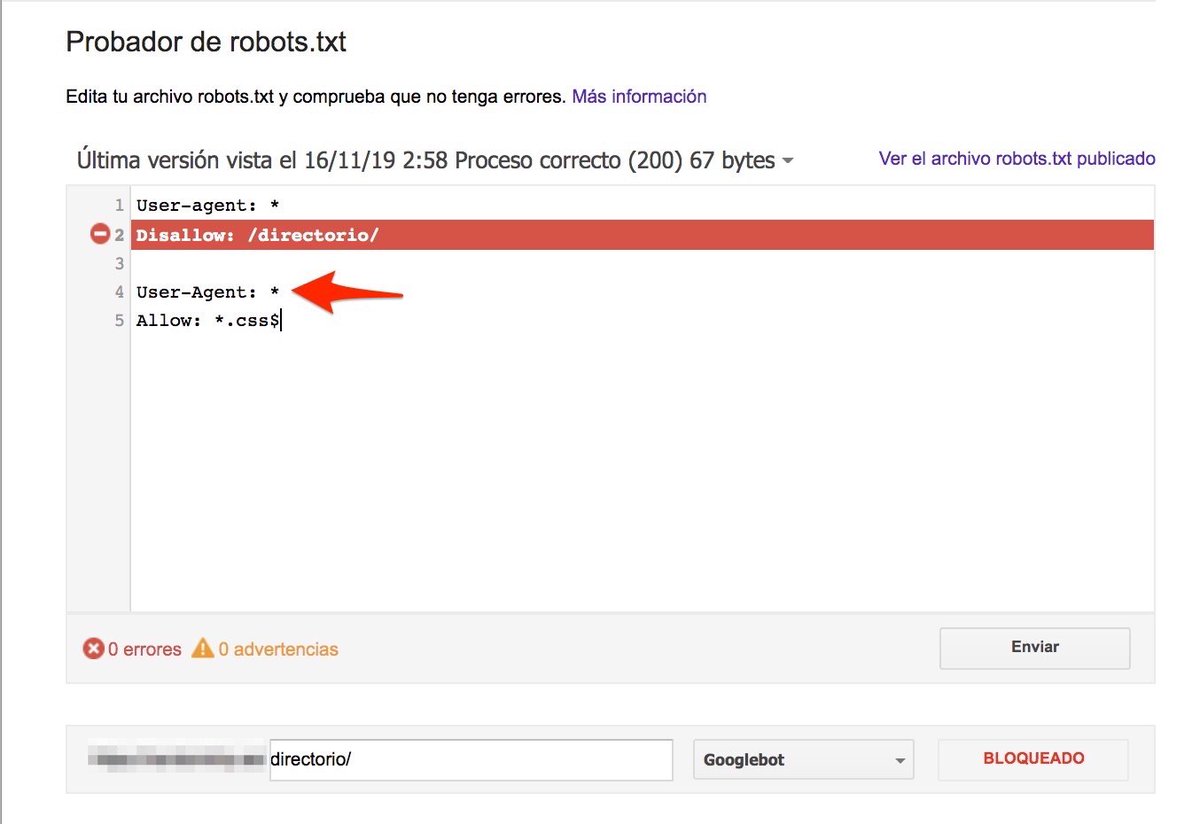
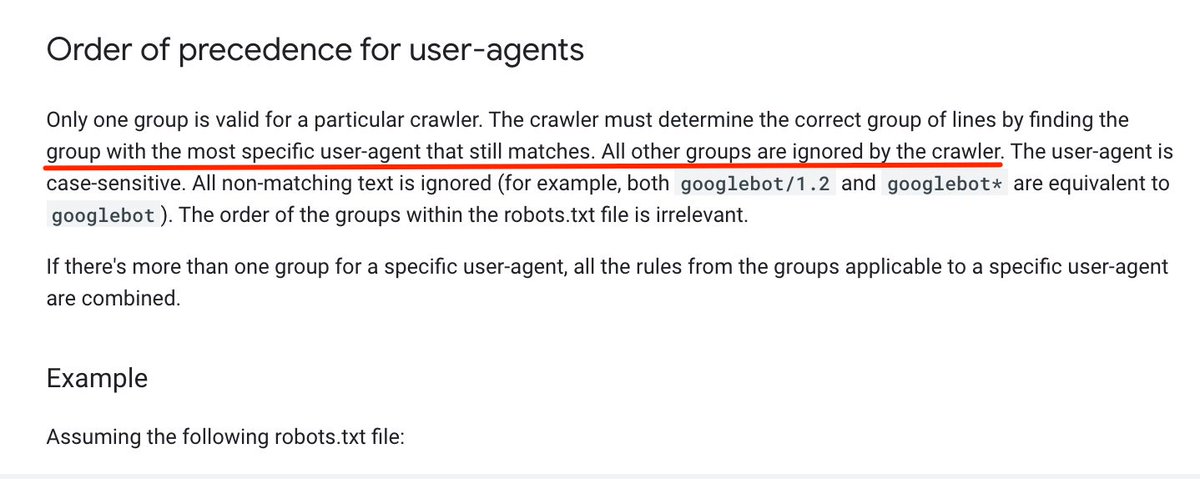
This happens because when there is a set of rules specifically for the User-agent that is checking the file (in this case, Googlebot), it will IGNORE all the other rules, and only apply the ones defined specifically for its User-agent: builtvisible.com/wildcards-in-r…

When testing again, after changing the scope of the second set of rules to any bot (User-agent: *), it worked as I expected in the first place
The same happens if we turn around the rules: even if we define a rule for any bot allowing to crawl any css/js, if there are rules defined specifically for Googlebot it will only obey those and ignore the ones defined for any other User-agent, even if it is "*"

This may seem obvious, but it's confusing, and in this specific case two rules (the ones allowing Googlebot to crawl any css/js file) were invalidating all the other rules previously defined, making the file not working as expected:

This is perfectly explained in the official Docs (thanks @mjcachon for pointing it out!) ==> developers.google.com/search/referen…
If we want to have generic rules and rules only for Googlebot, we would need to duplicate all the generic rules under the User-agent: Googlebot set of rules.
Another confusing behaviour I didn't knew about is that the priority of the rules (inside the same User-agent group) is not determined by their order, but by the length of the rule, as @ikhuerta pointed out here:
This means that in the previous example, the rules for css/js files won't work for all files: if there is a rule disallowing a directory (with more characters than the css/js rule), that rule will apply

BUT if the directory is just one letter, bots will be allowed to crawl those files.
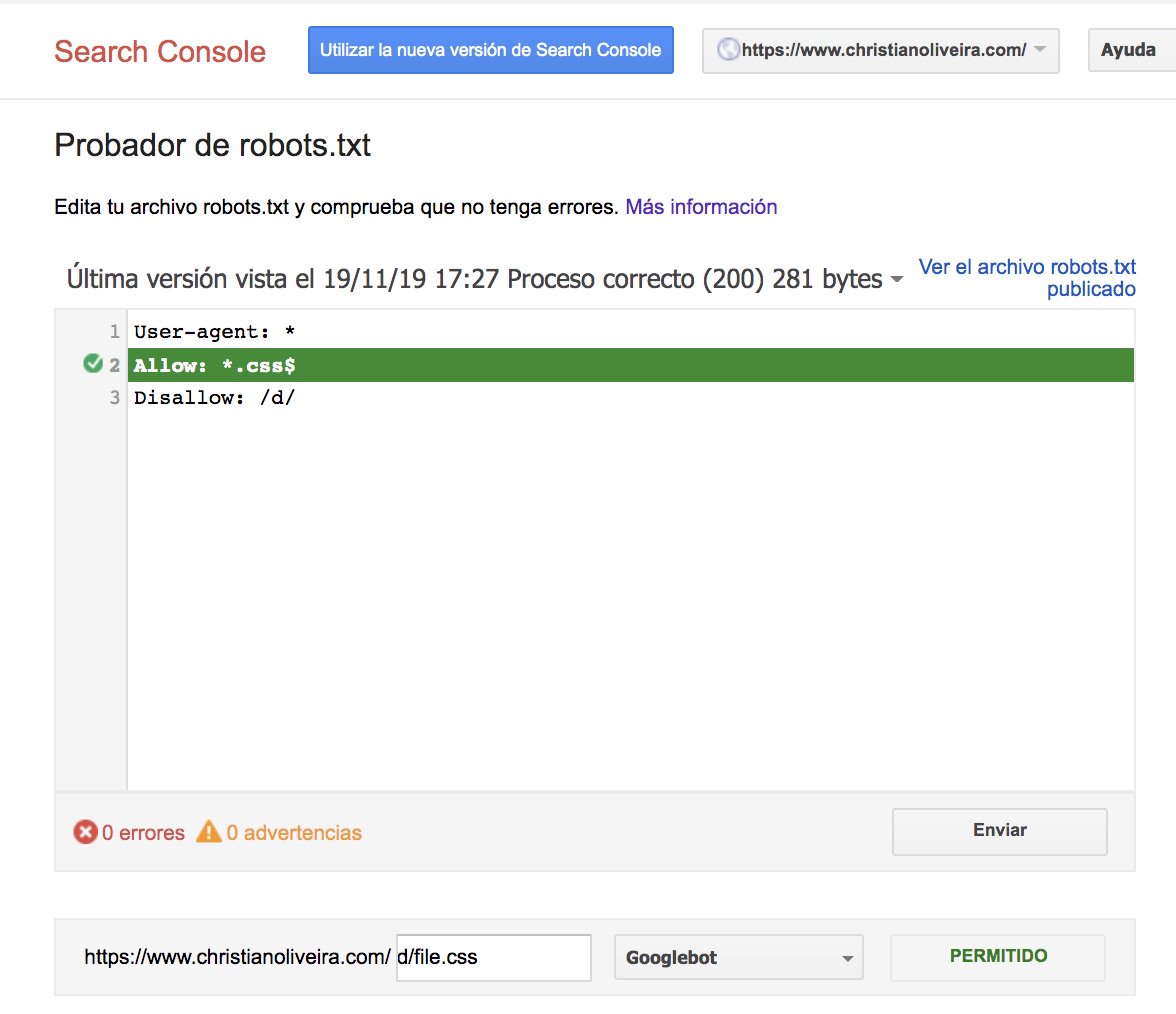
What if we have two rules, with the same length and opposite behaviour (one allowing the crawling and the other one disallowing it?). In theory, the less restrictive rule applies (the allow!)
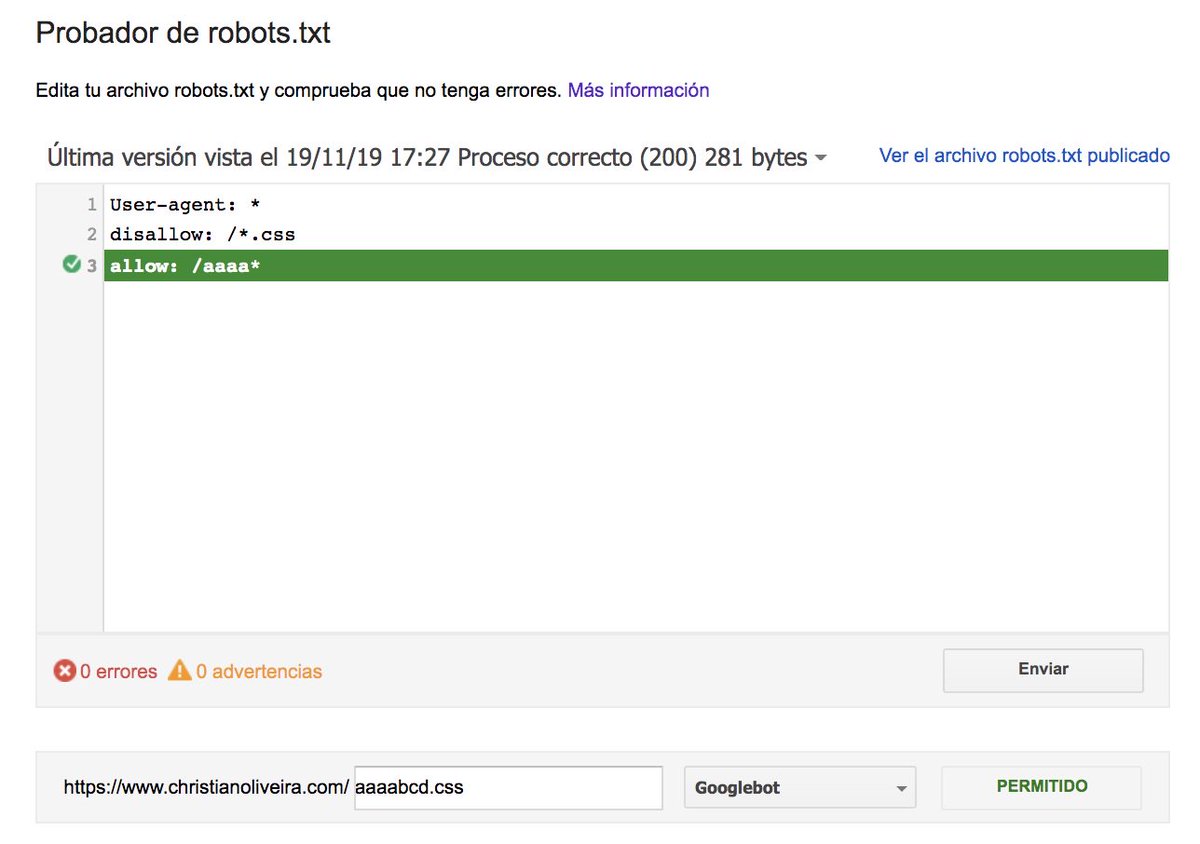
Besides all these things, it seems there are some cases with inconsistencies between what is explained in the docs, the robots.txt tester and the open-source parser announced some weeks ago, explained in this post by @distilled distilled.net/resources/goog…
@distilled Thanks to @Errioxa I just saw that @distilled launched a new tool to test robots.txt behaviour based on the open-source parser Google launched : realrobotstxt.com (more info on distilled.net/resources/free… )