Important point from Rep Rodgers Q about a specific instance of FB's algorithm taking down content that wasn't in violation of ToS. No algorithm is 100% accurate--90% accuracy is quite high. Now imagine applying that algorithm to the hundreds of thousands of posts every minute.
Algorithms suffer from both false positives (Type 1 error) and false negatives (Type 2 error). My favorite visual aid for when I teach this in stats: 

In FB's case, if you build an algorithm to automate the process of identifying and removing content in violation of the ToS, you have to assume it will will some that is in violation (false negative) and remove some that isn't (false positive).
Something else we've seen that highlights the role of human's in this process is that people can submit false reports to bring down content or users they disagree with. For example, we've seen this in the trans and Native American communities. washingtonpost.com/news/morning-m…
Shockingly enough (not shocking at all), marginalized groups suffer the most from these errors b/c of human & technical reasons. From a technical perspective, algorithms are often designed for "normal" or "average" users. Also, lack of diversity on design teams is a HUGE problem.
I could bring up a dozen different examples of how having a more diverse set of engineers could have avoided very embarrassing outcomes, but I'll point to just two: 1) Google search results for gorillas: wired.com/story/when-it-…, and 2) a soap dispenser: gizmodo.com/why-cant-this-…
Looking at the human side of this, @pewinternet looking at trolling behaviors online and found that "to troll is human" and that there are currently not sufficient disincentives for people to stop engaging in bad behavior. pewinternet.org/2017/03/29/the…
The average person is never going to understand how an algorithm works in any level of detail. Instead, let's educate people to understand that 1) people are writing these algorithms, 2) therefore algorithms are imbued with human bias, and 3) they WILL make mistakes.
Beyond that, there's so much more to know. Digital and privacy literacy is a huge part of my research agenda and I often feel overwhelmed as to how I can possible help people gain the requisite knowledge/skills to succeed and not be scammed.
How do you explain SEO to people who struggle to create an account on their bank's site? How do you tell them they can't trust the first Google result in a search because other factors determine that placement besides those that are "most relevant" to the search terms?
One thing Google did do right was fix a loophole in their algorithm after this 2010 algorithm where a scam eyeglasses seller in NYC used bad publicity to sell more product: nytimes.com/2010/11/28/bus…
However, we start to get into a gray area when Google (or FB or Twitter) starts making decisions outside of strictly legal spaces, like Google did when they removed anti-Semitic auto-completes from search queries: theguardian.com/technology/201…
Rep Castor just brought up an excellent point that the FB ecosystem extends tremendously far beyond Facebook, Instagram, and Whatsapp. Simply not using the app doesn't keep your data out of their hands.
One of the hardest concepts to operationalize in privacy research has been group (vs. individual) privacy management. In reality, we have very little control over our own data, as the Cambridge Analytica case has revealed.
For example, I--someone who has been intimately researching privacy on FB for 8+ years--am one of the 87M people whose data is part of the Cambridge Analytica breach because one of my FB Friends used the app.
When I teach Intro to Information Science, we talk about the power of network effects. I use the example of telephone penetration in the US and how a town with 20 phones had exponentially more benefits than one with just four phones.
But network effects also make it harder to CONTROL your data. If I had just 10 FB friends, I would pick my closest and most trusted connections. Maybe we'd talk before anyone made major sharing decisions. I'd have much more awareness of their behaviors on the site.
But if I have 180 FB friends (which was the average awhile ago), there is no way I am close to all of them or know their attitudes/behaviors around sharing and privacy or can monitor the behavior. It's simply impossible; time is inelastic ... without a time machine at least.
Looking at it this way, I would argue that FB's efforts to connect you to more people and make your network larger actually decreases your control over your information at a macro level. At a micro level, yes, you do have various controls, e.g., approving posts you're tagged in.
I really didn't mean for this to become a thread but this is a topic I am quite passionate about. It is core to my teaching and research at @iSchoolUMD. My goal is to improve the public's knowledge and skills around tech and privacy and empower them to take control of their data.
Zuckerberg is somewhat correct in saying the company has a strong reason to protect users' data. However, to go back to network effects & benefits associated with them, most people won't leave the site because FB is the only place that has nearly their full network in one place.
I'm enjoying Rep. Johnson's (OH) line of questioning here. If you want to read Facebook's Community Standards, they're here: facebook.com/communitystand…
No, FB doesn't SELL your data. It just SHARES that data. This small shift in language is widespread (ie, not limited to FB or social media platforms). From FB's ToS: facebook.com/terms.php
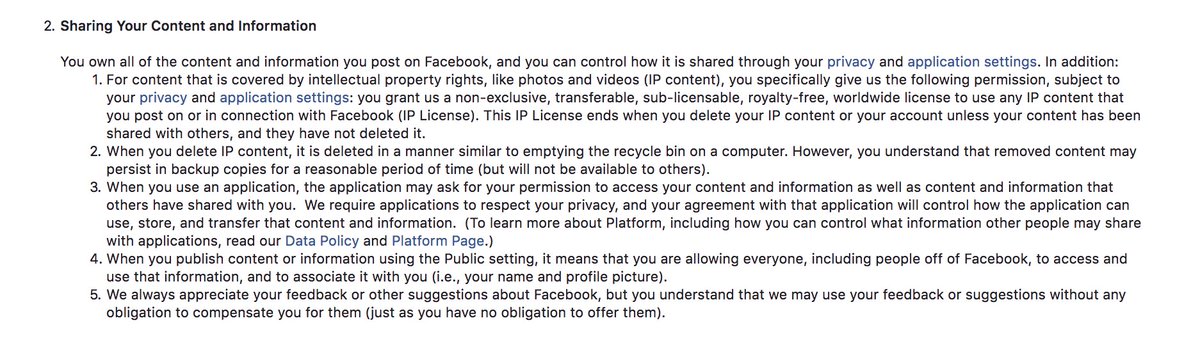
I feel a bit sad saying this, but you can't be so idealistic as to say, "We want to ensure we don't just give people tools but make sure they're used for good" when you're running a company that includes ~1/3 of the Earth's population. At that scale, you can't ENSURE anything.
Idealism is a great starting point, but the tools and policies that guide them must be grounded in a reality that understands there will always be bad actors and people who will find a way to circumvent whatever restrictions you put in place.
You could probably argue that blind idealism (and the original motto of "move fast, break stuff") is part of the reason why FB has had to apologize so many times for violating users' trust over the years.
Yes Mark, norms do evolve over time. They will continue over time. Many of us have been carefully studying the evolution of sharing and privacy norms on social media for more than a decade.
I think it's a bit ridiculous how many reps are chastising Zuckerberg for not knowing the fine details of how a 27,000-employee, 2B-user company is run. That's not a CEO's job. Sure, this could have been part of his prep for the hearing but it seems like a waste of their time.
For those looking at this issue from a more academic/theoretical lens, may I suggest you read this book by Helen Nissenbaum on contextual integrity, which is highly appropriate to this hearing, information flows, and privacy norms. amazon.com/Privacy-Contex…
Did Chariman Walden just ask Zuckerberg to throw other tech CEOs under the proverbial bus?