I think there are sneaky tricks going on here...
Hold tight...
Hold tight...
OK, so I have downloaded the video from Reddit and stripped the audio using VLC player. Now that it's an MP3 we can analyse the audio using the method outlined in my little tutorial...
Here's what the audio file looks like in the free software PRAAT: 
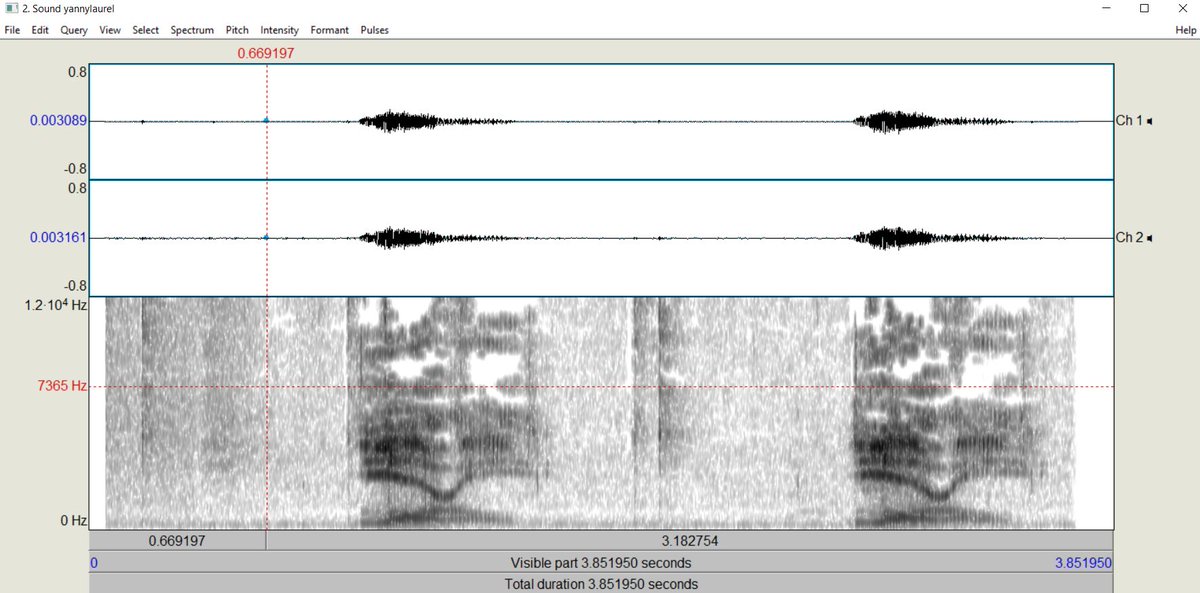
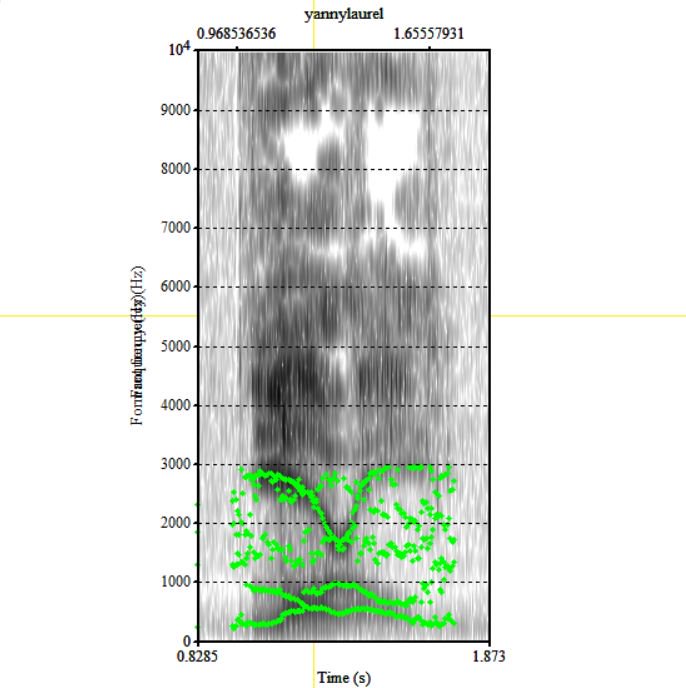
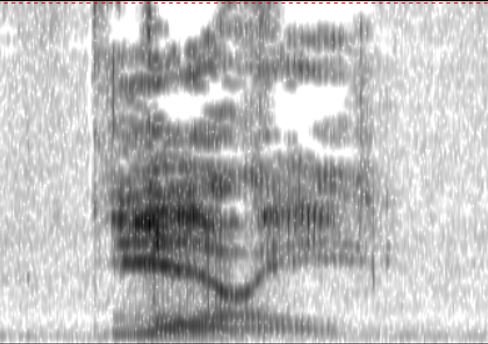
And there's something mysterious going on where those dark bands are at the bottom... In my tutorial, I explain that those dark bark are the 'formants' - the vibrating frequencies of air molecules that are carrying the most energy.
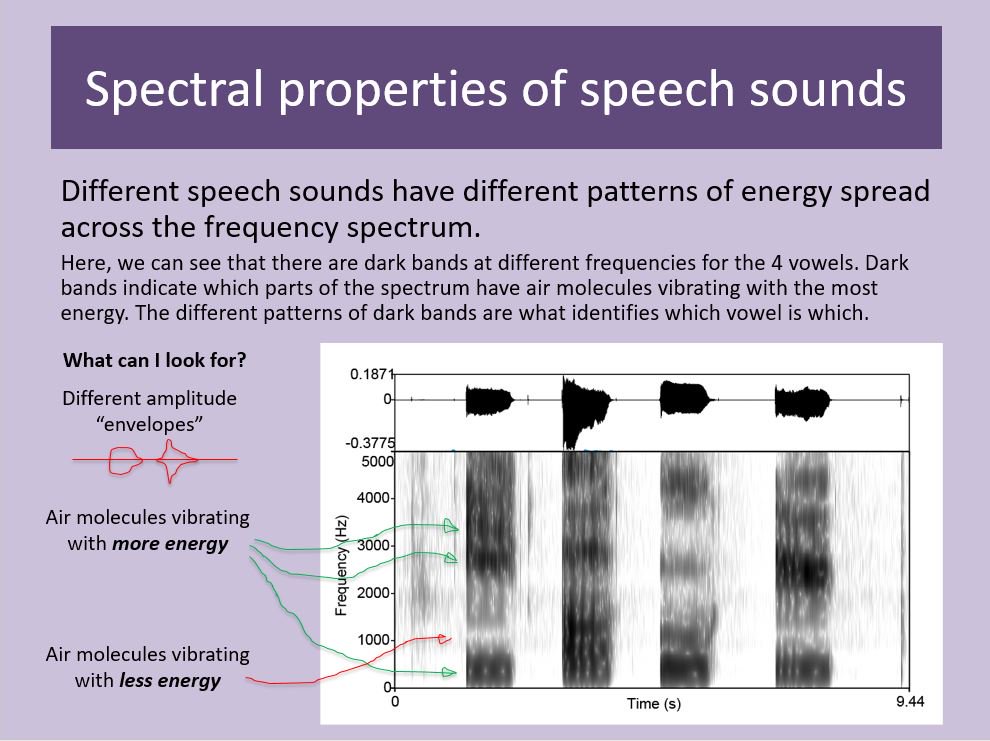
In normal speech, like the spectrogram in the previous tweet, there are THREE dark bands (or formants) under 5000Hz. These are known as F1 (the one at the bottom), F2 (the next one up), and F3 (the one after that). Acoustic scientists are imaginative like that... 🙄
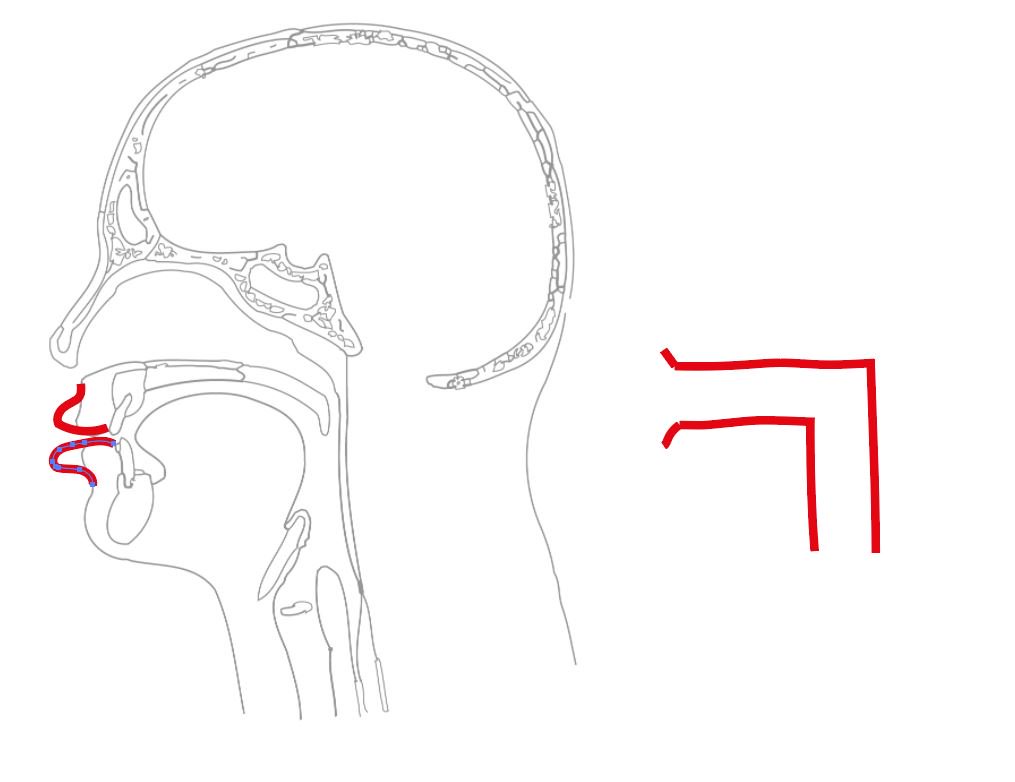
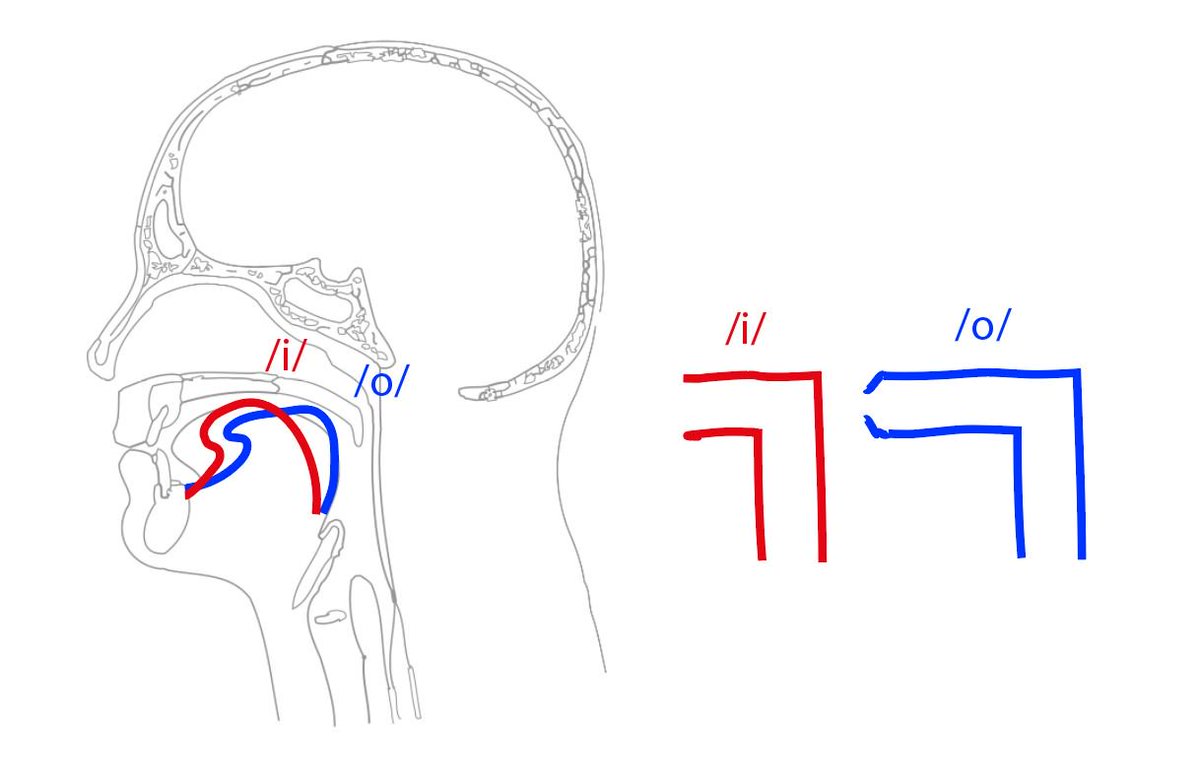
Each formant is the outcome of a different part of your SPEAK-PIPE. (The technical term for this is your vocal tract, but hey, this is Twitter🎉).
Here is a complicated anatomical drawing of a human vocal tract, and a diagram of the speak-pipe
Here is a complicated anatomical drawing of a human vocal tract, and a diagram of the speak-pipe
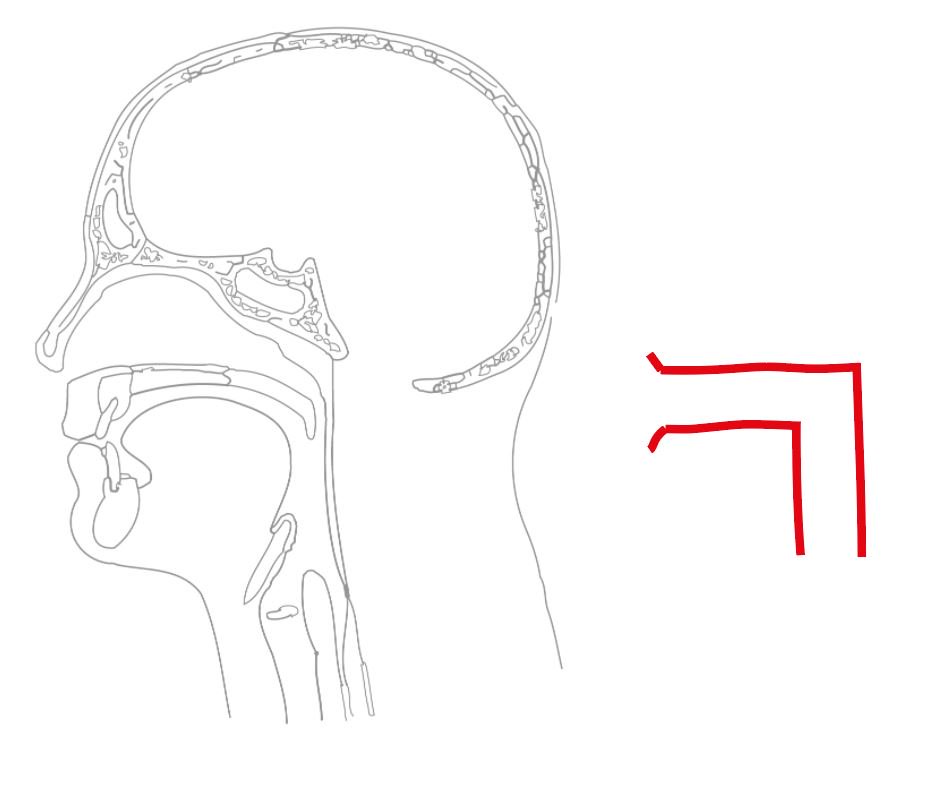
Roughly speaking it works like this:
F1 - length of the upright part
F2 - length of the horizontal part
F3 - shape of the opening
(note that the pronunciation of words sounds different when said with duck-face lips)
F1 - length of the upright part
F2 - length of the horizontal part
F3 - shape of the opening
(note that the pronunciation of words sounds different when said with duck-face lips)
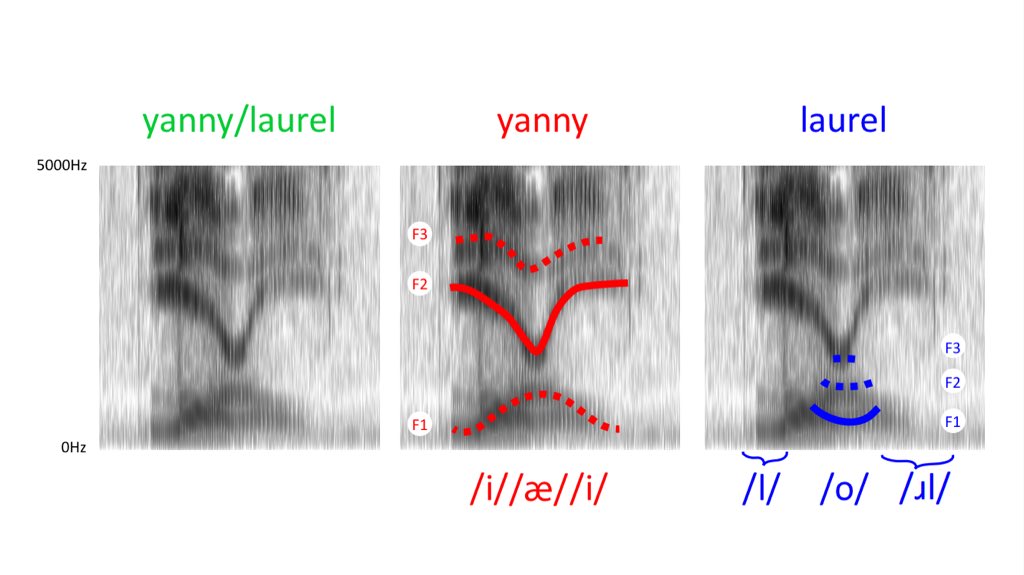
Now, in the yannylaurel clip there are MORE THAN THREE of these formant bands... They are not clearly defined in all places, but you can see that there are loops and overlaps:
If we look at F1 in particular (the bottom one, under 1000Hz), we can see that there are two overlapping shapes:
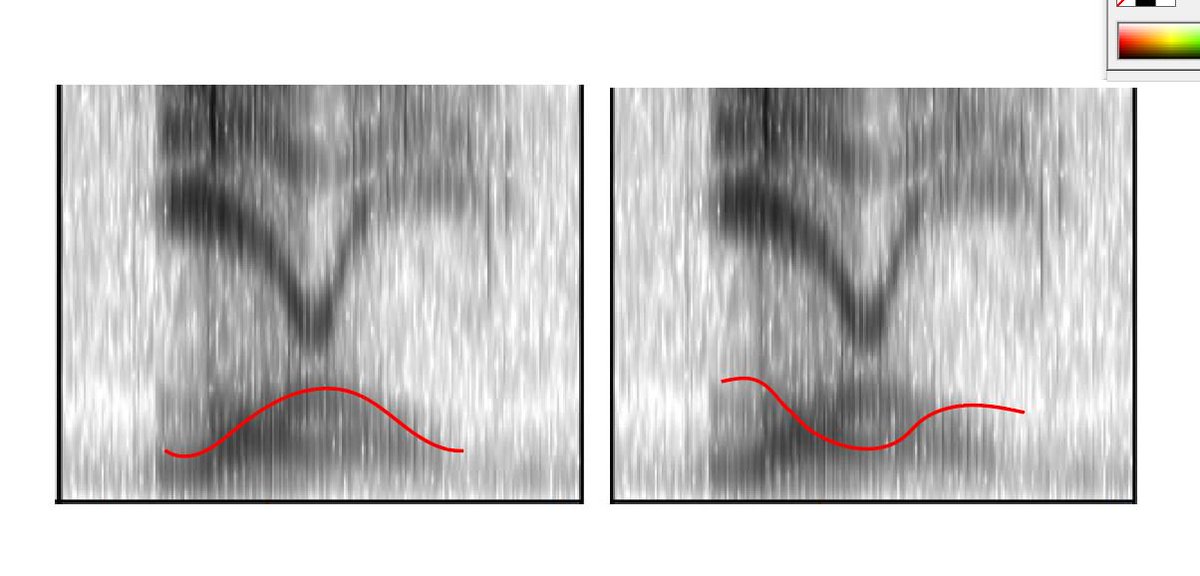
Each F1 shape tells us about the length of the upright part of the speak-pipe, controlled by how high the tongue is in the mouth. Since there are two tracks, the tongue could be either high-low high (left), OR low-high-low (right). That matches the vowels we hear.
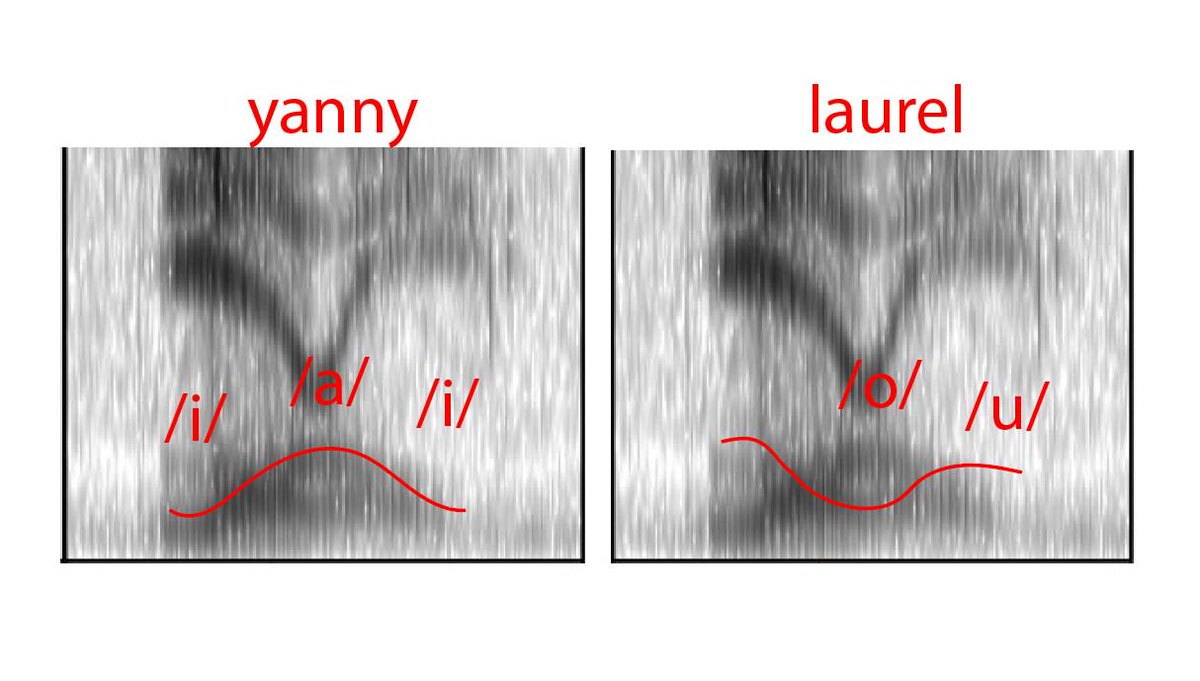
So unless this speaker had two completely separate tongues, this ambiguous speech has been carefully crafted to fool the ears. Shall we call it an Ear-llusion?
Now lots of folks have noticed that if you block the low frequencies, you only hear 'yanny' and if you block the high frequencies you only hear 'laurel'. This can be explained if we look at the next dark band in the enegry profile of the speech.
F2 (the second from the bottom) is controlled by the length of the horizontal part of the speak pipe, so it changes when your tongue is further towards the front or the back of your mouth. More front = shorter; more back = longer. (excuse the hasty rough drawings)
And if you don't believe that that's what your tongue is doing, check out this awesome video from @maxplanckpress showing a high-speed MRI of the speak-pipe in action. There's a cool bit at about 1:10 where the speaker says vowels clearly on their own:
So when we look at the sound with all of the frequencies present (left), we can see a very clear curvy shape. That's front-backish-front. Since the super high F2 is very far front, and can only be an /i/ or a "y" sound. If we cut it off, the strong "y" sounds are gone!
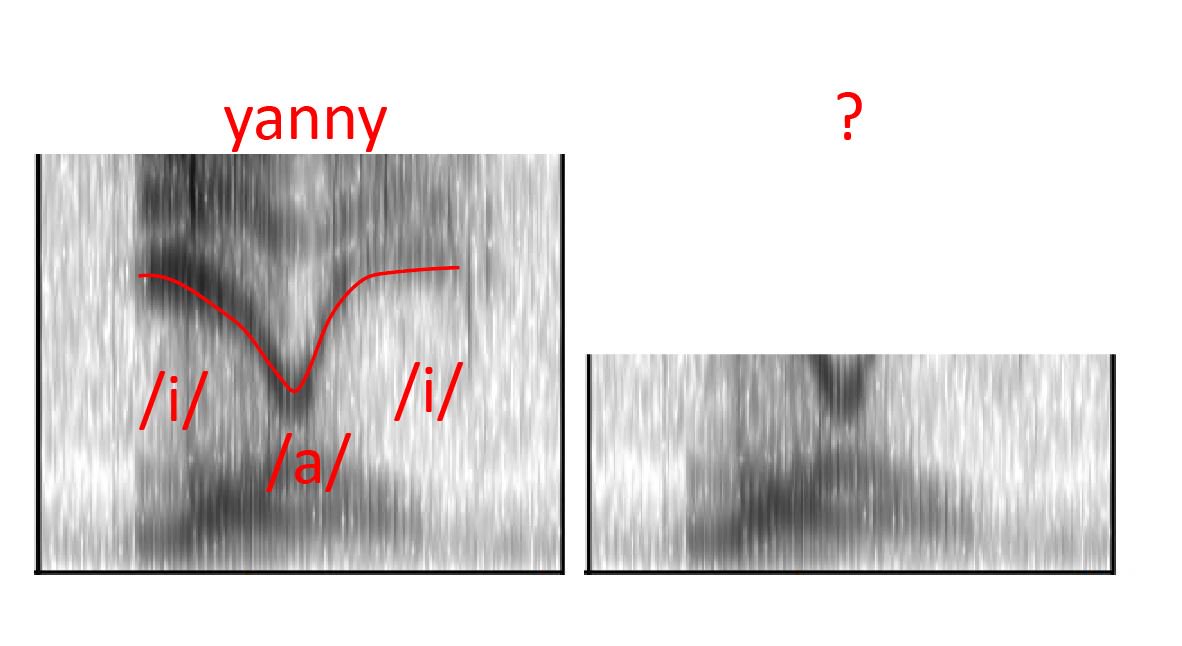
The brain is really good at reconstructing missing information. If the treble is loud-and-clear, then the best matching bass can be reconstructed (left). If the bass is loud-and-clear, then the best matching treble will be identified (right).
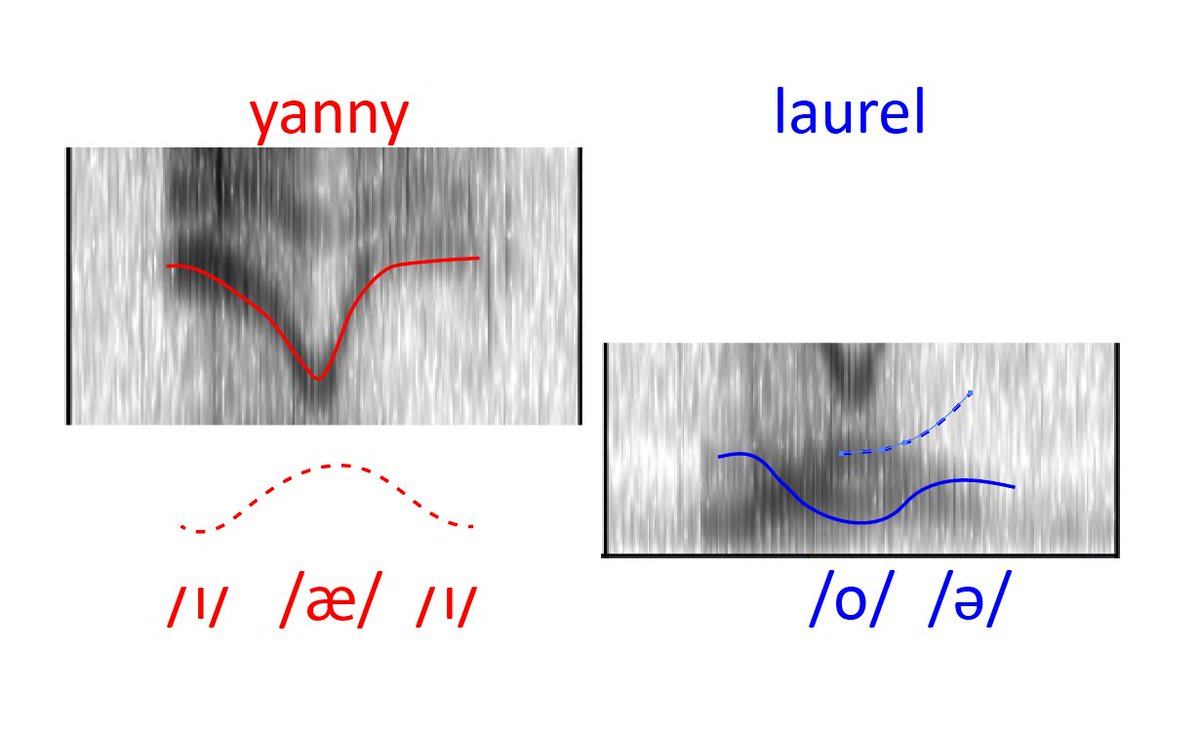
In short, this #earllusion contains acoustic info from both names. 'Yanny' is clearer in the higher frequencies because of the clear signal for "y" sounds in F2. 'Laurel' is clearer in the low frequencies for F1. Play with your stereo settings and watch your brain switch tracks!
GASP! the plot thickens! It appears that the original is from an online dictionary, as revealed by OP RolandCamry on Reddit
Which means that the audio was not created to fool our ears, but was an accidental outcome of the speech synthesis algorithm!
#badrobot
#badrobot
And since this thread has attracted *quite* a bit of attention (ahem)... I have tidied up the analysis a bit. This next chart is more accurate than the previous ones👇🏻
We expect there to be 3 dark bands for the formants below 5000Hz, but instead there's a mighty tangle. It could be three vowels (Yanny) or lots of consonants with a vowel in the middle (Laurel). Both options are possible!
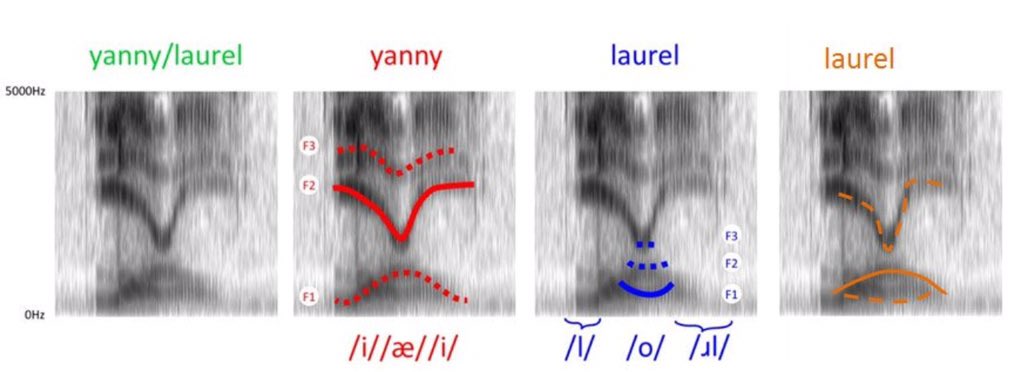
has updated the graphic, showing that the lines should be continued a bit more for Laurel, like in her orange version.
Thanks for that! 💯
Thanks for that! 💯
And new news about the origins of the audio have emerged!