
,
19 tweets,
5 min read
Read on Twitter
1/ A student just asked me why, if the p-value for a study is 0.04, we can't say the study has a 4% chance of being a false positive. First off, we definitely can't, even under idealized conditions - here's a brief thread as to why.
2/ (Apologies to the great John Ioannidis who does this better than I ever could), and to @VinayPrasadMD whose "Tweetorials" are an amazing epiphenomenon in and of themselves.
3/ Imagine a world of scientific hypotheses - all those hypotheses out there, floating in the ether. "Atorvastatin reduces nose bleeds" is out there. So is "marijuana use increases the chance of graduating college". Some of these are true hypotheses, some are not.
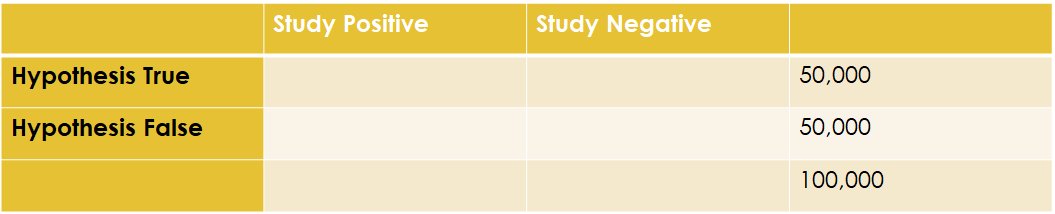
4/ Let's say there are 100,000 of these hypotheses, and 50% of them are true (they correctly state how things actually work). Now we need to study them... 
5/ 50,000 hypotheses are true, 50,000 are false, but that's not what our studies will show.
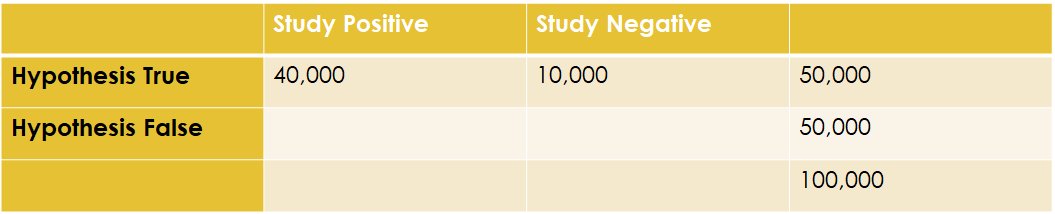
6/ When we test the true hypotheses, assuming our studies have a standard 80% power, we will only capture 40,000 as properly positive. We miss 10,000 true hypotheses. Too bad.
7/ We'll correctly identify that most of the false hypotheses are false, but we'll incorrectly find 5% of those are true (thanks to our p-value threshold of 0.05).
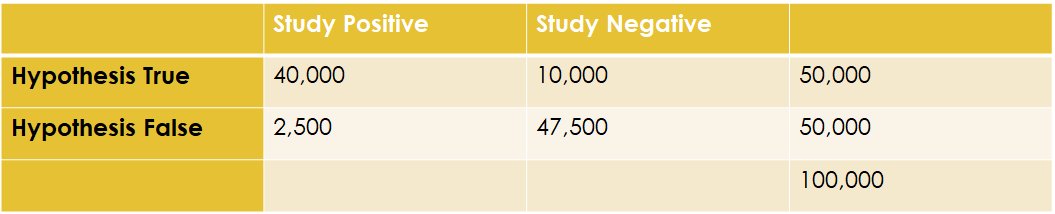
8/ So, we have 42,500 "positive" studies, of which 40,000 are "true positives" - that gives a positive predictive value of 94%. Not bad! Not 5% chance of being wrong (as we might intuit from the p-value), but pretty close!
9/ But what if 50% of the hypotheses in the ether aren't true? What if only, like, 10% are true...
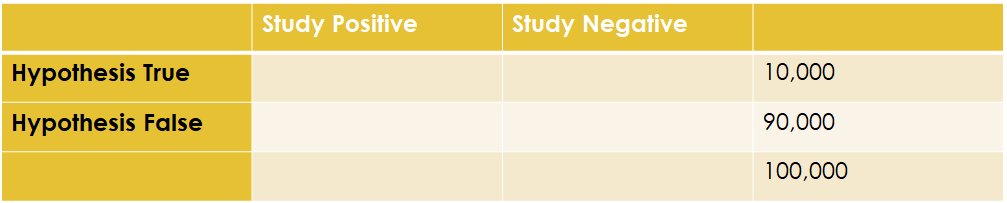
10/ Again, with our 80% power, we'll find 8000 out of 10000 true hypotheses to be true - missing a bunch but such is life.
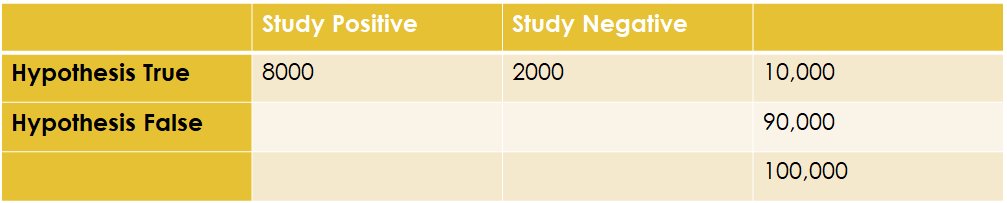
11/ But of the 90,000 false hypotheses, we'll incorrectly find 4500 that we deem as "true" (thanks to our p-value of 0.05).
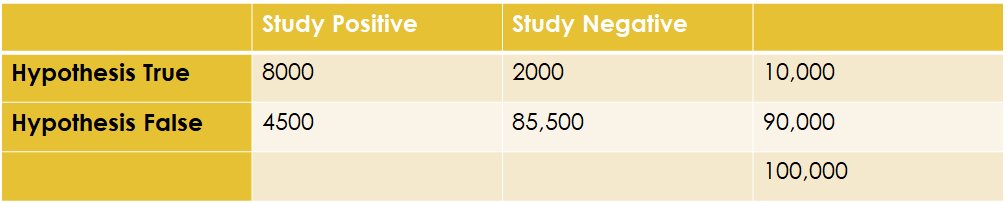
12/ Now we have 12,500 positive studies, but only 8000 of them are true positives. Meaning in this world, the positive predictive value of a positive study is just 8000/12,500 or 64%. Meaning 36% of the positive studies are FALSE POSITIVES. That's a far cry from 5%.
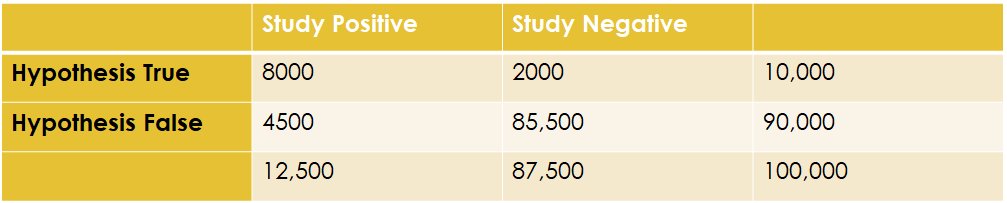
13/ The realization here is that the more untrue hypotheses are tested, the higher the rate of false positive studies. Here's how this looks graphically:
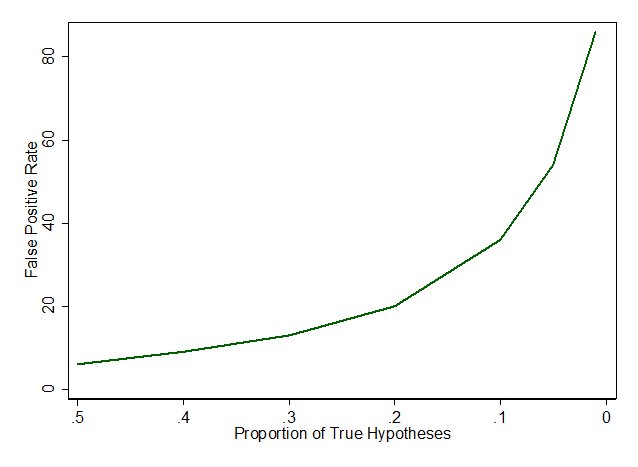
14/ Also realize that I didn't talk about publication bias, p-hacking, confounding, or any of the "cheating" ways that increase the risk of false-positive studies - this analysis assumes everything is on the up and up.
15/ Interpret a SINGLE study in the exact same way. Given a p-value of, say, 0.04, you need to decide how likely the hypothesis being tested was prior to the study. This tool, from Held et al, BMC Med Res Methodol 2010 can help.
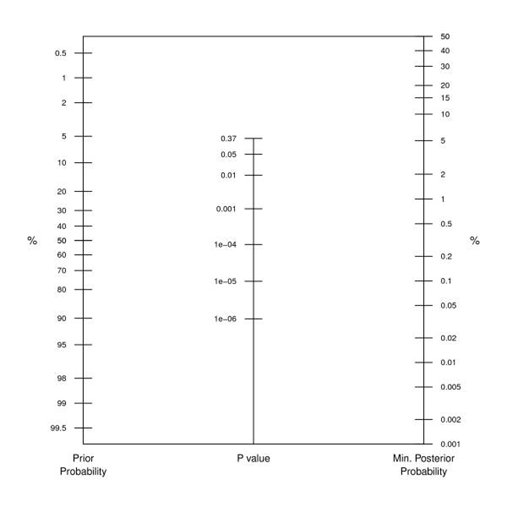
16/ In clinical terms, think of a randomized trial like you think of a test for a disease. If the patient is at extremely low risk, you view a "positive" test skeptically. If the patient has all the symptoms, a positive test is much more trustworthy.
17/ And the opposite is also true! If it is very likely a hypothesis is true, a p-value of 0.06 is quite reassuring! It doesn't disprove anything.
18/ Yes, this is Bayesianism. But I didn't want to say that til the end. I'm not wading into that debate. I just wanted to talk a bit about why p=0.04 does NOT mean 4% this study is wrong.
19/ I hope this helps someone! Let me know.













