
,
9 tweets,
3 min read
Read on Twitter
Interesting developments happened in 2018/2019 for natural language generation decoding algorithms: here's a thread with some papers & code
So, the two most common decoders for language generation used to be greedy-decoding (GD) and beam-search (BS). [1/9]
So, the two most common decoders for language generation used to be greedy-decoding (GD) and beam-search (BS). [1/9]
Greedy: at each time step, select the most likely next token according to the model until end of sequence. Risk: miss a high prob token hiding after a low-prob one.
Beam-search: to mitigate this, maintain a beam of sequences constructed word-by-word. Choose best at the end [2/9]
Beam-search: to mitigate this, maintain a beam of sequences constructed word-by-word. Choose best at the end [2/9]
Beam-search is now the standard decoding algorithm for almost all language generation tasks including dialog (see arxiv.org/abs/1811.00907).
But interesting developments happened in 2018/2019 [3/9]
But interesting developments happened in 2018/2019 [3/9]
First, there was growing evidence that beam-search is highly sensitive to the length of the output. Best results are obtained when the output length is predicted from the input before decoding (arxiv.org/abs/1808.10006, arxiv.org/abs/1808.09582 at EMNLP 2018) [4/9]
While this makes sense for low-entropy tasks like translation where the output length can be roughly predicted from the input, it seems arbitrary for high-entropy tasks like dialog and story generation where outputs of widely different lengths are usually equally valid [5/9]
In parallel, at least 2 influential papers (arxiv.org/abs/1805.04833, openai.com/blog/better-la…) on high-entropy tasks were published where BS/greedy was replaced by sampling from the next token distribution at each time step (using a variant called top-k sampling, see below) [6/9]
Last in this recent trend of work is arxiv.org/abs/1904.09751 in which @universeinanegg & co show that the distribution of words in BS/greedy decoded texts is very different from the one in human texts.
Clearly BS/greedy fail to reproduce distributional aspects of human text [7/9]
Clearly BS/greedy fail to reproduce distributional aspects of human text [7/9]
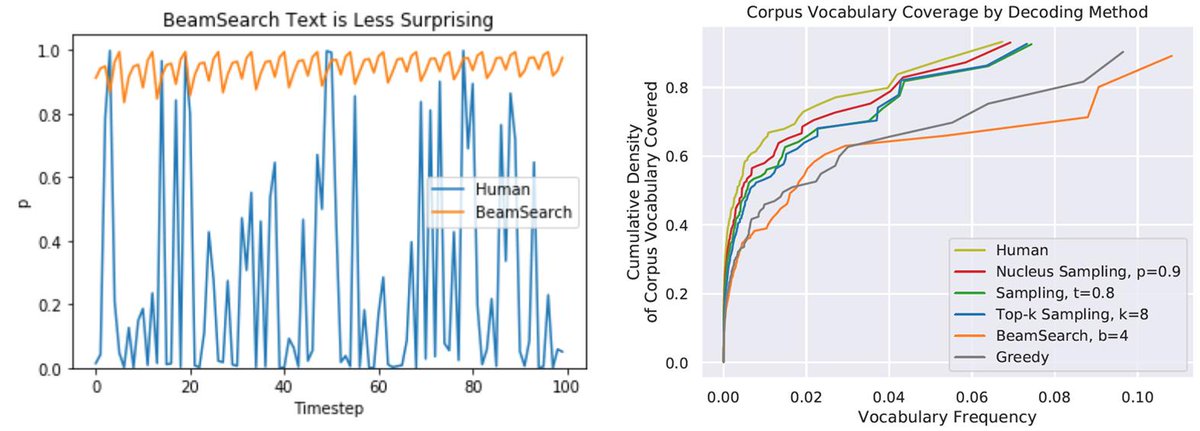
Today, the most promising candidates for high-entropy tasks decoders seem to be top-k & nucleus sampling
General principle: at each step, sample from the next-token distribution filtered to keep only the top-k tokens or the top tokens with cumulative prob above a threshold [8/9]
General principle: at each step, sample from the next-token distribution filtered to keep only the top-k tokens or the top tokens with cumulative prob above a threshold [8/9]
Finally, here is a gist showing how to code top-k and nucleus sampling in PyTorch:
gist.github.com/thomwolf/1a5a2…
[9/9]
gist.github.com/thomwolf/1a5a2…
[9/9]









